 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualFLIP: Do Predictions Depend on Task-Critical Visual Evidence in Multimodal Reasoning?
Jun 05, 2026When a multimodal large language model answers a visual reasoning question correctly, is the prediction actually supported by the task-critical visual evidence? Correct answers can coexist with flawed reasoning, making accuracy alone an incomplete test of grounding. We introduce VisualFLIP, a paired benchmark with 1,374 images arranged as same-question perturbation pairs across cardinality, attribute, spatial, and logic tasks. Each pair keeps the question fixed but minimally changes the evidence so the gold answer deterministically flips. We evaluate 24 MLLMs with pair accuracy, which requires solving both sides of a pair, and Collapse Rate (CR), which measures how often a model that solves at least one side repeats the same non-empty answer for both images. Together, these metrics show that paired correctness and evidence dependence are related but distinct: capable models can still fail to update after task-critical visual changes, and collapse becomes more severe for some models when the edited image follows an earlier answer in a sequential setting. Further details are available on our project page: https://didizhu-judy.github.io/VisualFLIP/
LLaVA-OneVision-2: Towards Next-Generation Perceptual Intelligence
May 25, 2026We introduce LLaVA-OneVision-2 (LLaVA-OV-2), the most capable vision-language model in the LLaVA-OneVision series to date, achieving superior performance across a broad range of multimodal benchmarks. The model builds on a native OneVision-Encoder and incorporates Windowed Attention for efficient local computation while maintaining native resolution. Its key advance is codec-stream tokenization: it treats compressed video as a continuous bit-cost stream, where bit-cost dynamics determine adaptive temporal groups, and motion-residual cues select salient spatial evidence into compact visual canvases. This allocation concentrates a limited token budget on event-bearing content, enabling more stable long-video token compression than fixed groups of pictures. A shared 3D RoPE further places codec canvases, sampled frames, and images in a unified spatiotemporal coordinate system. Furthermore, we build the LLaVA-OV-2 data and training stack around large-scale open supervision: approximately 8M re-captioned video samples for pretraining, a 4M-sample spatial corpus for fine-tuning. We also introduce JumpScore, a temporal-localization benchmark targeting fine-grained grounding in high-frequency, densely repeated motion, a regime underrepresented by existing video evaluations. A standout capability of LLaVA-OV-2 is its unified perception across video understanding, temporal grounding, spatial grounding, and manipulation-trace reasoning. On JumpScore, LLaVA-OneVision-2-8B reaches 74.9 JumpScore mAP, surpassing Qwen3-VL-8B (30.1) by +44.8 points; under matched visual-token budgets on the same benchmark, codec-stream inputs improve temporal grounding over frame sampling by +9.7 points. Across standard benchmarks, LLaVA-OneVision-2-8B further outperforms Qwen3-VL-8B by +4.3 average points on video tasks, +5.3 on spatial tasks, and +15.6 average J&F on tracking tasks.
Watch Wider and Think Deeper: Collaborative Cross-modal Chain-of-Thought for Complex Visual Reasoning
Jan 04, 2026Multi-modal reasoning requires the seamless integration of visual and linguistic cues, yet existing Chain-of-Thought methods suffer from two critical limitations in cross-modal scenarios: (1) over-reliance on single coarse-grained image regions, and (2) semantic fragmentation between successive reasoning steps. To address these issues, we propose the CoCoT (Collaborative Coross-modal Thought) framework, built upon two key innovations: a) Dynamic Multi-Region Grounding to adaptively detect the most relevant image regions based on the question, and b) Relation-Aware Reasoning to enable multi-region collaboration by iteratively aligning visual cues to form a coherent and logical chain of thought. Through this approach, we construct the CoCoT-70K dataset, comprising 74,691 high-quality samples with multi-region annotations and structured reasoning chains. Extensive experiments demonstrate that CoCoT significantly enhances complex visual reasoning, achieving an average accuracy improvement of 15.4% on LLaVA-1.5 and 4.0% on Qwen2-VL across six challenging benchmarks. The data and code are available at: https://github.com/deer-echo/CoCoT.
OmniEduBench: A Comprehensive Chinese Benchmark for Evaluating Large Language Models in Education
Oct 30, 2025With the rapid development of large language models (LLMs), various LLM-based works have been widely applied in educational fields. However, most existing LLMs and their benchmarks focus primarily on the knowledge dimension, largely neglecting the evaluation of cultivation capabilities that are essential for real-world educational scenarios. Additionally, current benchmarks are often limited to a single subject or question type, lacking sufficient diversity. This issue is particularly prominent within the Chinese context. To address this gap, we introduce OmniEduBench, a comprehensive Chinese educational benchmark. OmniEduBench consists of 24.602K high-quality question-answer pairs. The data is meticulously divided into two core dimensions: the knowledge dimension and the cultivation dimension, which contain 18.121K and 6.481K entries, respectively. Each dimension is further subdivided into 6 fine-grained categories, covering a total of 61 different subjects (41 in the knowledge and 20 in the cultivation). Furthermore, the dataset features a rich variety of question formats, including 11 common exam question types, providing a solid foundation for comprehensively evaluating LLMs' capabilities in education. Extensive experiments on 11 mainstream open-source and closed-source LLMs reveal a clear performance gap. In the knowledge dimension, only Gemini-2.5 Pro surpassed 60\% accuracy, while in the cultivation dimension, the best-performing model, QWQ, still trailed human intelligence by nearly 30\%. These results highlight the substantial room for improvement and underscore the challenges of applying LLMs in education.
Noise Projection: Closing the Prompt-Agnostic Gap Behind Text-to-Image Misalignment in Diffusion Models
Oct 16, 2025In text-to-image generation, different initial noises induce distinct denoising paths with a pretrained Stable Diffusion (SD) model. While this pattern could output diverse images, some of them may fail to align well with the prompt. Existing methods alleviate this issue either by altering the denoising dynamics or by drawing multiple noises and conducting post-selection. In this paper, we attribute the misalignment to a training-inference mismatch: during training, prompt-conditioned noises lie in a prompt-specific subset of the latent space, whereas at inference the noise is drawn from a prompt-agnostic Gaussian prior. To close this gap, we propose a noise projector that applies text-conditioned refinement to the initial noise before denoising. Conditioned on the prompt embedding, it maps the noise to a prompt-aware counterpart that better matches the distribution observed during SD training, without modifying the SD model. Our framework consists of these steps: we first sample some noises and obtain token-level feedback for their corresponding images from a vision-language model (VLM), then distill these signals into a reward model, and finally optimize the noise projector via a quasi-direct preference optimization. Our design has two benefits: (i) it requires no reference images or handcrafted priors, and (ii) it incurs small inference cost, replacing multi-sample selection with a single forward pass. Extensive experiments further show that our prompt-aware noise projection improves text-image alignment across diverse prompts.
FedEve: On Bridging the Client Drift and Period Drift for Cross-device Federated Learning
Aug 20, 2025Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model without exposing their private data. Data heterogeneity is a fundamental challenge in FL, which can result in poor convergence and performance degradation. Client drift has been recognized as one of the factors contributing to this issue resulting from the multiple local updates in FedAvg. However, in cross-device FL, a different form of drift arises due to the partial client participation, but it has not been studied well. This drift, we referred as period drift, occurs as participating clients at each communication round may exhibit distinct data distribution that deviates from that of all clients. It could be more harmful than client drift since the optimization objective shifts with every round. In this paper, we investigate the interaction between period drift and client drift, finding that period drift can have a particularly detrimental effect on cross-device FL as the degree of data heterogeneity increases. To tackle these issues, we propose a predict-observe framework and present an instantiated method, FedEve, where these two types of drift can compensate each other to mitigate their overall impact. We provide theoretical evidence that our approach can reduce the variance of model updates. Extensive experiments demonstrate that our method outperforms alternatives on non-iid data in cross-device settings.
Keeping Yourself is Important in Downstream Tuning Multimodal Large Language Model
Mar 06, 2025Multi-modal Large Language Models (MLLMs) integrate visual and linguistic reasoning to address complex tasks such as image captioning and visual question answering. While MLLMs demonstrate remarkable versatility, MLLMs appears limited performance on special applications. But tuning MLLMs for downstream tasks encounters two key challenges: Task-Expert Specialization, where distribution shifts between pre-training and target datasets constrain target performance, and Open-World Stabilization, where catastrophic forgetting erases the model general knowledge. In this work, we systematically review recent advancements in MLLM tuning methodologies, classifying them into three paradigms: (I) Selective Tuning, (II) Additive Tuning, and (III) Reparameterization Tuning. Furthermore, we benchmark these tuning strategies across popular MLLM architectures and diverse downstream tasks to establish standardized evaluation analysis and systematic tuning principles. Finally, we highlight several open challenges in this domain and propose future research directions. To facilitate ongoing progress in this rapidly evolving field, we provide a public repository that continuously tracks developments: https://github.com/WenkeHuang/Awesome-MLLM-Tuning.
Generative Artificial Intelligence in Robotic Manipulation: A Survey
Mar 05, 2025



This survey provides a comprehensive review on recent advancements of generative learning models in robotic manipulation, addressing key challenges in the field. Robotic manipulation faces critical bottlenecks, including significant challenges in insufficient data and inefficient data acquisition, long-horizon and complex task planning, and the multi-modality reasoning ability for robust policy learning performance across diverse environments. To tackle these challenges, this survey introduces several generative model paradigms, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), diffusion models, probabilistic flow models, and autoregressive models, highlighting their strengths and limitations. The applications of these models are categorized into three hierarchical layers: the Foundation Layer, focusing on data generation and reward generation; the Intermediate Layer, covering language, code, visual, and state generation; and the Policy Layer, emphasizing grasp generation and trajectory generation. Each layer is explored in detail, along with notable works that have advanced the state of the art. Finally, the survey outlines future research directions and challenges, emphasizing the need for improved efficiency in data utilization, better handling of long-horizon tasks, and enhanced generalization across diverse robotic scenarios. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/GAI4Manipulation/AwesomeGAIManipulation
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025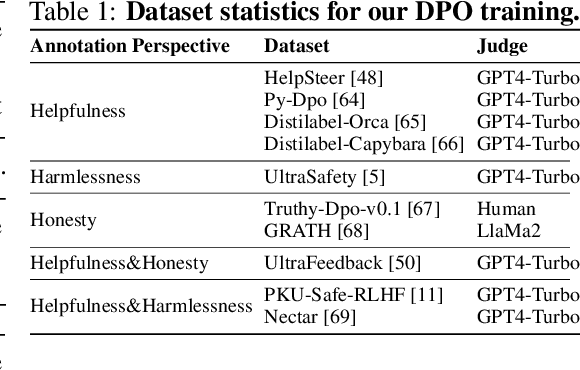
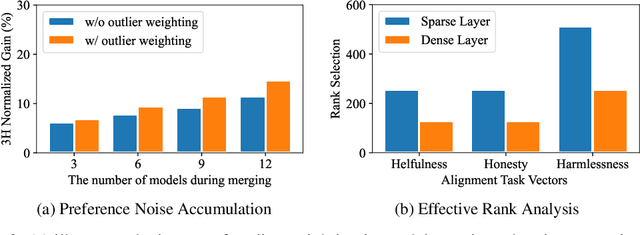
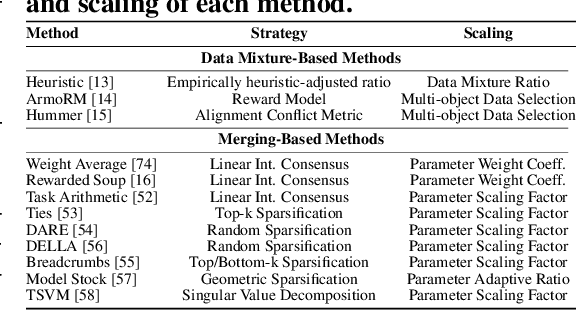
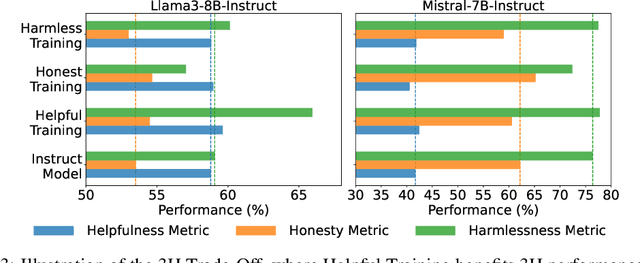
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
Let Human Sketches Help: Empowering Challenging Image Segmentation Task with Freehand Sketches
Jan 31, 2025



Sketches, with their expressive potential, allow humans to convey the essence of an object through even a rough contour. For the first time, we harness this expressive potential to improve segmentation performance in challenging tasks like camouflaged object detection (COD). Our approach introduces an innovative sketch-guided interactive segmentation framework, allowing users to intuitively annotate objects with freehand sketches (drawing a rough contour of the object) instead of the traditional bounding boxes or points used in classic interactive segmentation models like SAM. We demonstrate that sketch input can significantly improve performance in existing iterative segmentation methods, outperforming text or bounding box annotations. Additionally, we introduce key modifications to network architectures and a novel sketch augmentation technique to fully harness the power of sketch input and further boost segmentation accuracy. Remarkably, our model' s output can be directly used to train other neural networks, achieving results comparable to pixel-by-pixel annotations--while reducing annotation time by up to 120 times, which shows great potential in democratizing the annotation process and enabling model training with less reliance on resource-intensive, laborious pixel-level annotations. We also present KOSCamo+, the first freehand sketch dataset for camouflaged object detection. The dataset, code, and the labeling tool will be open sourced.