 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-Coder-Next Technical Report
Feb 28, 2026We present Qwen3-Coder-Next, an open-weight language model specialized for coding agents. Qwen3-Coder-Next is an 80-billion-parameter model that activates only 3 billion parameters during inference, enabling strong coding capability with efficient inference. In this work, we explore how far strong training recipes can push the capability limits of models with small parameter footprints. To achieve this, we perform agentic training through large-scale synthesis of verifiable coding tasks paired with executable environments, allowing learning directly from environment feedback via mid-training and reinforcement learning. Across agent-centric benchmarks including SWE-Bench and Terminal-Bench, Qwen3-Coder-Next achieves competitive performance relative to its active parameter count. We release both base and instruction-tuned open-weight versions to support research and real-world coding agent development.
SWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
Each Rank Could be an Expert: Single-Ranked Mixture of Experts LoRA for Multi-Task Learning
Jan 25, 2025



Low-Rank Adaptation (LoRA) is widely used for adapting large language models (LLMs) to specific domains due to its efficiency and modularity. Meanwhile, vanilla LoRA struggles with task conflicts in multi-task scenarios. Recent works adopt Mixture of Experts (MoE) by treating each LoRA module as an expert, thereby mitigating task interference through multiple specialized LoRA modules. While effective, these methods often isolate knowledge within individual tasks, failing to fully exploit the shared knowledge across related tasks. In this paper, we establish a connection between single LoRA and multi-LoRA MoE, integrating them into a unified framework. We demonstrate that the dynamic routing of multiple LoRAs is functionally equivalent to rank partitioning and block-level activation within a single LoRA. We further empirically demonstrate that finer-grained LoRA partitioning, within the same total and activated parameter constraints, leads to better performance gains across heterogeneous tasks. Building on these findings, we propose Single-ranked Mixture of Experts LoRA (\textbf{SMoRA}), which embeds MoE into LoRA by \textit{treating each rank as an independent expert}. With a \textit{dynamic rank-wise activation} mechanism, SMoRA promotes finer-grained knowledge sharing while mitigating task conflicts. Experiments demonstrate that SMoRA activates fewer parameters yet achieves better performance in multi-task scenarios.
BabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.
Merging LoRAs like Playing LEGO: Pushing the Modularity of LoRA to Extremes Through Rank-Wise Clustering
Sep 24, 2024



Low-Rank Adaptation (LoRA) has emerged as a popular technique for fine-tuning large language models (LLMs) to various domains due to its modular design and widespread availability on platforms like Huggingface. This modularity has sparked interest in combining multiple LoRAs to enhance LLM capabilities. However, existing methods for LoRA composition primarily focus on task-specific adaptations that require additional training, and current model merging techniques often fail to fully leverage LoRA's modular nature, leading to parameter interference and performance degradation. In this paper, we investigate the feasibility of disassembling and reassembling multiple LoRAs at a finer granularity, analogous to assembling LEGO blocks. We introduce the concept of Minimal Semantic Units (MSUs), where the parameters corresponding to each rank in LoRA function as independent units. These MSUs demonstrate permutation invariance and concatenation-summation equivalence properties, enabling flexible combinations to create new LoRAs. Building on these insights, we propose the LoRA-LEGO framework. This framework conducts rank-wise parameter clustering by grouping MSUs from different LoRAs into $k$ clusters. The centroid of each cluster serves as a representative MSU, enabling the assembly of a merged LoRA with an adjusted rank of $k$. Additionally, we apply a dual reweighting strategy to optimize the scale of the merged LoRA. Experiments across various benchmarks demonstrate that our method outperforms existing approaches in LoRA merging.
Flickr30K-CFQ: A Compact and Fragmented Query Dataset for Text-image Retrieval
Apr 01, 2024With the explosive growth of multi-modal information on the Internet, unimodal search cannot satisfy the requirement of Internet applications. Text-image retrieval research is needed to realize high-quality and efficient retrieval between different modalities. Existing text-image retrieval research is mostly based on general vision-language datasets (e.g. MS-COCO, Flickr30K), in which the query utterance is rigid and unnatural (i.e. verbosity and formality). To overcome the shortcoming, we construct a new Compact and Fragmented Query challenge dataset (named Flickr30K-CFQ) to model text-image retrieval task considering multiple query content and style, including compact and fine-grained entity-relation corpus. We propose a novel query-enhanced text-image retrieval method using prompt engineering based on LLM. Experiments show that our proposed Flickr30-CFQ reveals the insufficiency of existing vision-language datasets in realistic text-image tasks. Our LLM-based Query-enhanced method applied on different existing text-image retrieval models improves query understanding performance both on public dataset and our challenge set Flickr30-CFQ with over 0.9% and 2.4% respectively. Our project can be available anonymously in https://sites.google.com/view/Flickr30K-cfq.
An Expert is Worth One Token: Synergizing Multiple Expert LLMs as Generalist via Expert Token Routing
Mar 25, 2024



We present Expert-Token-Routing, a unified generalist framework that facilitates seamless integration of multiple expert LLMs. Our framework represents expert LLMs as special expert tokens within the vocabulary of a meta LLM. The meta LLM can route to an expert LLM like generating new tokens. Expert-Token-Routing not only supports learning the implicit expertise of expert LLMs from existing instruction dataset but also allows for dynamic extension of new expert LLMs in a plug-and-play manner. It also conceals the detailed collaboration process from the user's perspective, facilitating interaction as though it were a singular LLM. Our framework outperforms various existing multi-LLM collaboration paradigms across benchmarks that incorporate six diverse expert domains, demonstrating effectiveness and robustness in building generalist LLM system via synergizing multiple expert LLMs.
OVEL: Large Language Model as Memory Manager for Online Video Entity Linking
Mar 03, 2024



In recent years, multi-modal entity linking (MEL) has garnered increasing attention in the research community due to its significance in numerous multi-modal applications. Video, as a popular means of information transmission, has become prevalent in people's daily lives. However, most existing MEL methods primarily focus on linking textual and visual mentions or offline videos's mentions to entities in multi-modal knowledge bases, with limited efforts devoted to linking mentions within online video content. In this paper, we propose a task called Online Video Entity Linking OVEL, aiming to establish connections between mentions in online videos and a knowledge base with high accuracy and timeliness. To facilitate the research works of OVEL, we specifically concentrate on live delivery scenarios and construct a live delivery entity linking dataset called LIVE. Besides, we propose an evaluation metric that considers timelessness, robustness, and accuracy. Furthermore, to effectively handle OVEL task, we leverage a memory block managed by a Large Language Model and retrieve entity candidates from the knowledge base to augment LLM performance on memory management. The experimental results prove the effectiveness and efficiency of our method.
InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks
Jan 10, 2024



In this paper, we introduce "InfiAgent-DABench", the first benchmark specifically designed to evaluate LLM-based agents in data analysis tasks. This benchmark contains DAEval, a dataset consisting of 311 data analysis questions derived from 55 CSV files, and an agent framework to evaluate LLMs as data analysis agents. We adopt a format-prompting technique, ensuring questions to be closed-form that can be automatically evaluated. Our extensive benchmarking of 23 state-of-the-art LLMs uncovers the current challenges encountered in data analysis tasks. In addition, we have developed DAAgent, a specialized agent trained on instruction-tuning datasets. Evaluation datasets and toolkits for InfiAgent-DABench are released at https://github.com/InfiAgent/InfiAgent.
WikiDiverse: A Multimodal Entity Linking Dataset with Diversified Contextual Topics and Entity Types
Apr 13, 2022
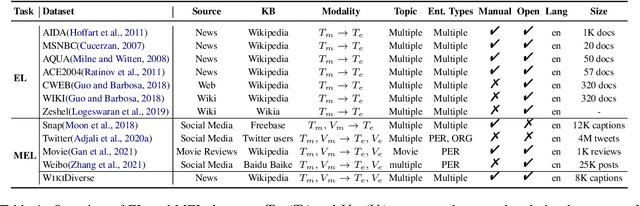
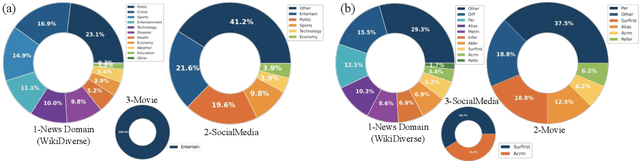

Multimodal Entity Linking (MEL) which aims at linking mentions with multimodal contexts to the referent entities from a knowledge base (e.g., Wikipedia), is an essential task for many multimodal applications. Although much attention has been paid to MEL, the shortcomings of existing MEL datasets including limited contextual topics and entity types, simplified mention ambiguity, and restricted availability, have caused great obstacles to the research and application of MEL. In this paper, we present WikiDiverse, a high-quality human-annotated MEL dataset with diversified contextual topics and entity types from Wikinews, which uses Wikipedia as the corresponding knowledge base. A well-tailored annotation procedure is adopted to ensure the quality of the dataset. Based on WikiDiverse, a sequence of well-designed MEL models with intra-modality and inter-modality attentions are implemented, which utilize the visual information of images more adequately than existing MEL models do. Extensive experimental analyses are conducted to investigate the contributions of different modalities in terms of MEL, facilitating the future research on this task. The dataset and baseline models are available at https://github.com/wangxw5/wikiDiverse.