 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternalizing Research Synthesis and Validation in AI Scientists through a Research Harness
Jun 17, 2026AI systems can increasingly automate scientific workflows, but the reasoning that links prior evidence, generated ideas, experiments and final claims often remains implicit inside model inference. Here we introduce Xcientist, a research harness that externalizes research synthesis and experimental validation into inspectable, contract-governed processes. Xcientist organizes literature evidence, idea states, implementation plans, ablation records and repair traces as persistent research artifacts, so that generated mechanisms can be grounded, executed, tested and revised without losing their evidential basis. We identify claim drift as a failure mode of automated research, where runnable artifacts no longer support the mechanism originally claimed. Across training-free memory systems, graph-structured traffic forecasting and multi-scale physics-informed neural networks, Xcientist preserves traceable trajectories from problem formulation to mechanism design, validation and bounded revision. These results suggest that AI scientists should be evaluated not only by their final artifacts, but by whether their synthesis and validation processes remain attributable, inspectable and scientifically accountable.
IEA: Amateur-Friendly Conversational Image Editing Agent via Three Stages of Multitask Alignment
Jun 06, 2026Current image editing software often hinges on fixed filters or expert tuning, leaving a gap between amateur users' intent and outcomes. Creations by generative models may contain artifacts, implausible details, or stylistic drift away from photorealism and offer little insight into why an edit was made. We propose IEA, a conversational Image Editing Agent that learns to operate parameterized tools in an explicit, interpretable action space. IEA is trained via a three-stage multitask pipeline: (1) SFT on distilled expert edits, (2) GRPO with rewards for likeness improvement, tool usefulness, and intent summarization, and (3) large-scale synthetic fine-tuning to jointly master image editing, refinement, and user intent summarization. By manipulating 16 editing tools step by step, IEA produces transparent edit traces that can be inspected and debugged. In quantitative experiments, it attains a lower pixel distance on the edit task and a higher ROUGE-L on the summary task than strong baselines. In user studies, it ranks best among tool-calling methods for instruction following while surpassing generative methods in overall perceptual quality. Our results validate interpretable, tool-centric VLMs as a reliable path to human instruction-guided image retouching.
DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation
May 28, 2026As scientific literature grows rapidly, automated survey generation has become a key capability for AI scientists and human researchers. However, existing systems suffer from limited analytical depth due to reliance on abstracts and isolated paper processing, and unreliable citations from imprecise retrieval and post-hoc grounding, producing superficial surveys and may mislead researchers. We present DeepSurvey, an agentic system that addresses both. To enhance depth, DeepSurvey extracts structured keynotes from full-text papers, models cross-paper relationships through clustering and comparative analysis, and integrates code-repository analysis to recover implementation-level details. To fortify reliability, it combines citation-graph expansion with hybrid filtering for topic-focussed retrieval, enforces evidence-constrained citation assignment, and deploys multi-granularity agentic refinement to validate citation-claim alignment. Experiments show that DeepSurvey achieves the highest content score (8.644/10) and citation quality (12.3% and 9.3% recall and precision gains over the strongest baseline), generalizes more robustly across domains (0.14 vs 0.22 to 0.69 CS-to-non-CS drop), and is preferred over human-written surveys by domain experts (83.3% overall quality, 100% content depth).
TokenDance: Token-to-Token Music-to-Dance Generation with Bidirectional Mamba
Mar 28, 2026Music-to-dance generation has broad applications in virtual reality, dance education, and digital character animation. However, the limited coverage of existing 3D dance datasets confines current models to a narrow subset of music styles and choreographic patterns, resulting in poor generalization to real-world music. Consequently, generated dances often become overly simplistic and repetitive, substantially degrading expressiveness and realism. To tackle this problem, we present TokenDance, a two-stage music-to-dance generation framework that explicitly addresses this limitation through dual-modality tokenization and efficient token-level generation. In the first stage, we discretize both dance and music using Finite Scalar Quantization, where dance motions are factorized into upper and lower-body components with kinematic-dynamic constraints, and music is decomposed into semantic and acoustic features with dedicated codebooks to capture choreography-specific structures. In the second stage, we introduce a Local-Global-Local token-to-token generator built on a Bidirectional Mamba backbone, enabling coherent motion synthesis, strong music-dance alignment, and efficient non-autoregressive inference. Extensive experiments demonstrate that TokenDance achieves overall state-of-the-art (SOTA) performance in both generation quality and inference speed, highlighting its effectiveness and practical value for real-world music-to-dance applications.
Sigma-MoE-Tiny Technical Report
Dec 19, 2025



Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025



An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
ProgRM: Build Better GUI Agents with Progress Rewards
May 23, 2025LLM-based (Large Language Model) GUI (Graphical User Interface) agents can potentially reshape our daily lives significantly. However, current LLM-based GUI agents suffer from the scarcity of high-quality training data owing to the difficulties of trajectory collection and reward annotation. Existing works have been exploring LLMs to collect trajectories for imitation learning or to offer reward signals for online RL training. However, the Outcome Reward Model (ORM) used in existing works cannot provide finegrained feedback and can over-penalize the valuable steps in finally failed trajectories. To this end, we propose Progress Reward Model (ProgRM) to provide dense informative intermediate rewards by predicting a task completion progress for each step in online training. To handle the challenge of progress reward label annotation, we further design an efficient LCS-based (Longest Common Subsequence) self-annotation algorithm to discover the key steps in trajectories and assign progress labels accordingly. ProgRM is evaluated with extensive experiments and analyses. Actors trained with ProgRM outperform leading proprietary LLMs and ORM-trained actors, illustrating the effectiveness of ProgRM. The codes for experiments will be made publicly available upon acceptance.
MSCCL++: Rethinking GPU Communication Abstractions for Cutting-edge AI Applications
Apr 11, 2025

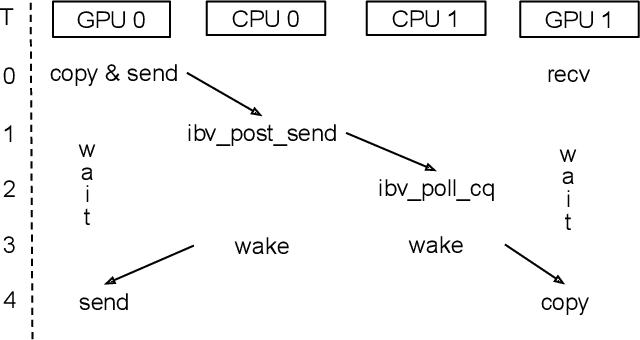
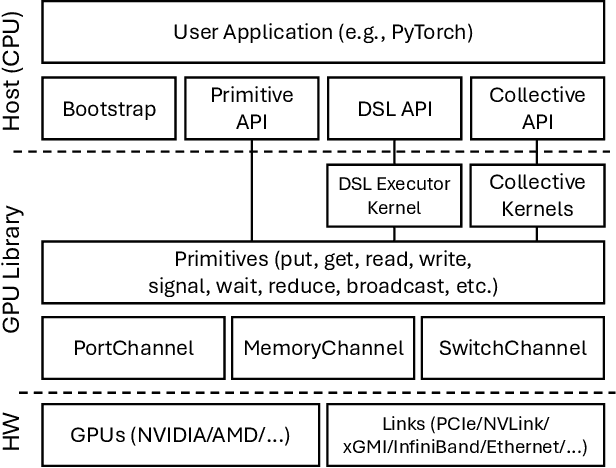
Modern cutting-edge AI applications are being developed over fast-evolving, heterogeneous, nascent hardware devices. This requires frequent reworking of the AI software stack to adopt bottom-up changes from new hardware, which takes time for general-purpose software libraries. Consequently, real applications often develop custom software stacks optimized for their specific workloads and hardware. Custom stacks help quick development and optimization, but incur a lot of redundant efforts across applications in writing non-portable code. This paper discusses an alternative communication library interface for AI applications that offers both portability and performance by reducing redundant efforts while maintaining flexibility for customization. We present MSCCL++, a novel abstraction of GPU communication based on separation of concerns: (1) a primitive interface provides a minimal hardware abstraction as a common ground for software and hardware developers to write custom communication, and (2) higher-level portable interfaces and specialized implementations enable optimization for different hardware environments. This approach makes the primitive interface reusable across applications while enabling highly flexible optimization. Compared to state-of-the-art baselines (NCCL, RCCL, and MSCCL), MSCCL++ achieves speedups of up to 3.8$\times$ for collective communication and up to 15\% for real-world AI inference workloads. MSCCL++ is in production of multiple AI services provided by Microsoft Azure, and is also adopted by RCCL, the GPU collective communication library maintained by AMD. MSCCL++ is open-source and available at https://github.com/microsoft/mscclpp.
Uncertainty Aware Human-machine Collaboration in Camouflaged Object Detection
Feb 12, 2025



Camouflaged Object Detection (COD), the task of identifying objects concealed within their environments, has seen rapid growth due to its wide range of practical applications. A key step toward developing trustworthy COD systems is the estimation and effective utilization of uncertainty. In this work, we propose a human-machine collaboration framework for classifying the presence of camouflaged objects, leveraging the complementary strengths of computer vision (CV) models and noninvasive brain-computer interfaces (BCIs). Our approach introduces a multiview backbone to estimate uncertainty in CV model predictions, utilizes this uncertainty during training to improve efficiency, and defers low-confidence cases to human evaluation via RSVP-based BCIs during testing for more reliable decision-making. We evaluated the framework in the CAMO dataset, achieving state-of-the-art results with an average improvement of 4.56\% in balanced accuracy (BA) and 3.66\% in the F1 score compared to existing methods. For the best-performing participants, the improvements reached 7.6\% in BA and 6.66\% in the F1 score. Analysis of the training process revealed a strong correlation between our confidence measures and precision, while an ablation study confirmed the effectiveness of the proposed training policy and the human-machine collaboration strategy. In general, this work reduces human cognitive load, improves system reliability, and provides a strong foundation for advancements in real-world COD applications and human-computer interaction. Our code and data are available at: https://github.com/ziyuey/Uncertainty-aware-human-machine-collaboration-in-camouflaged-object-identification.
Optimizing Large Language Model Training Using FP4 Quantization
Jan 28, 2025



The growing computational demands of training large language models (LLMs) necessitate more efficient methods. Quantized training presents a promising solution by enabling low-bit arithmetic operations to reduce these costs. While FP8 precision has demonstrated feasibility, leveraging FP4 remains a challenge due to significant quantization errors and limited representational capacity. This work introduces the first FP4 training framework for LLMs, addressing these challenges with two key innovations: a differentiable quantization estimator for precise weight updates and an outlier clamping and compensation strategy to prevent activation collapse. To ensure stability, the framework integrates a mixed-precision training scheme and vector-wise quantization. Experimental results demonstrate that our FP4 framework achieves accuracy comparable to BF16 and FP8, with minimal degradation, scaling effectively to 13B-parameter LLMs trained on up to 100B tokens. With the emergence of next-generation hardware supporting FP4, our framework sets a foundation for efficient ultra-low precision training.