 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
Benchmarking Egocentric Clinical Intent Understanding Capability for Medical Multimodal Large Language Models
Jan 11, 2026Medical Multimodal Large Language Models (Med-MLLMs) require egocentric clinical intent understanding for real-world deployment, yet existing benchmarks fail to evaluate this critical capability. To address these challenges, we introduce MedGaze-Bench, the first benchmark leveraging clinician gaze as a Cognitive Cursor to assess intent understanding across surgery, emergency simulation, and diagnostic interpretation. Our benchmark addresses three fundamental challenges: visual homogeneity of anatomical structures, strict temporal-causal dependencies in clinical workflows, and implicit adherence to safety protocols. We propose a Three-Dimensional Clinical Intent Framework evaluating: (1) Spatial Intent: discriminating precise targets amid visual noise, (2) Temporal Intent: inferring causal rationale through retrospective and prospective reasoning, and (3) Standard Intent: verifying protocol compliance through safety checks. Beyond accuracy metrics, we introduce Trap QA mechanisms to stress-test clinical reliability by penalizing hallucinations and cognitive sycophancy. Experiments reveal current MLLMs struggle with egocentric intent due to over-reliance on global features, leading to fabricated observations and uncritical acceptance of invalid instructions.
GARDO: Reinforcing Diffusion Models without Reward Hacking
Dec 30, 2025Fine-tuning diffusion models via online reinforcement learning (RL) has shown great potential for enhancing text-to-image alignment. However, since precisely specifying a ground-truth objective for visual tasks remains challenging, the models are often optimized using a proxy reward that only partially captures the true goal. This mismatch often leads to reward hacking, where proxy scores increase while real image quality deteriorates and generation diversity collapses. While common solutions add regularization against the reference policy to prevent reward hacking, they compromise sample efficiency and impede the exploration of novel, high-reward regions, as the reference policy is usually sub-optimal. To address the competing demands of sample efficiency, effective exploration, and mitigation of reward hacking, we propose Gated and Adaptive Regularization with Diversity-aware Optimization (GARDO), a versatile framework compatible with various RL algorithms. Our key insight is that regularization need not be applied universally; instead, it is highly effective to selectively penalize a subset of samples that exhibit high uncertainty. To address the exploration challenge, GARDO introduces an adaptive regularization mechanism wherein the reference model is periodically updated to match the capabilities of the online policy, ensuring a relevant regularization target. To address the mode collapse issue in RL, GARDO amplifies the rewards for high-quality samples that also exhibit high diversity, encouraging mode coverage without destabilizing the optimization process. Extensive experiments across diverse proxy rewards and hold-out unseen metrics consistently show that GARDO mitigates reward hacking and enhances generation diversity without sacrificing sample efficiency or exploration, highlighting its effectiveness and robustness.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
MT-Mark: Rethinking Image Watermarking via Mutual-Teacher Collaboration with Adaptive Feature Modulation
Dec 22, 2025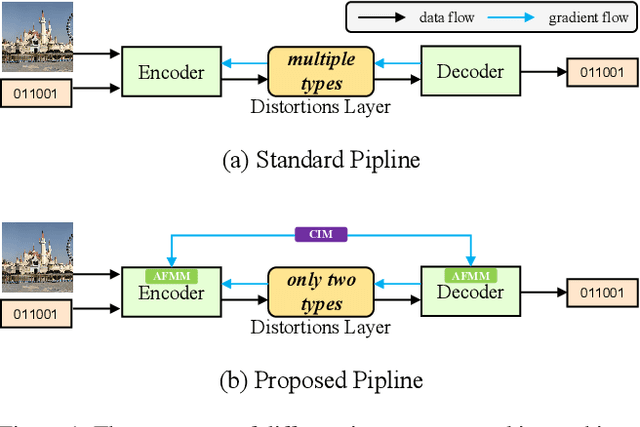
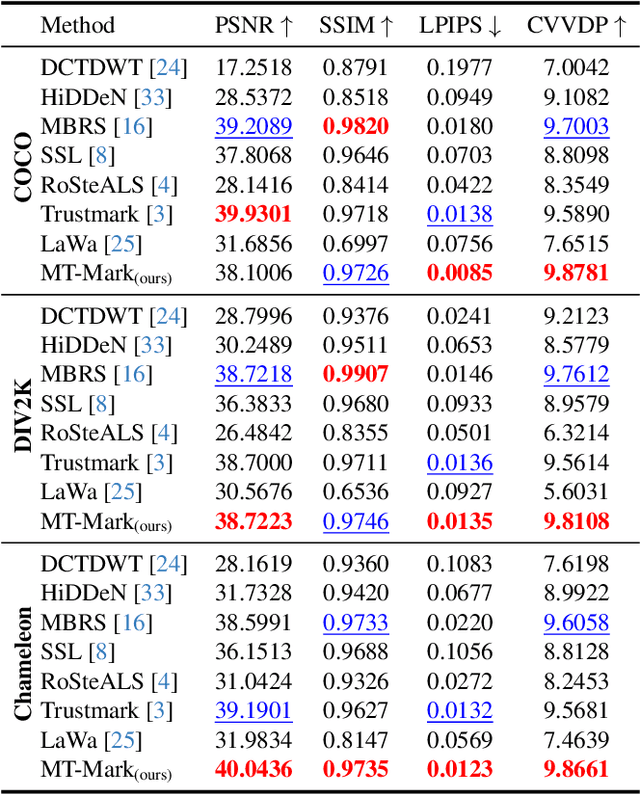
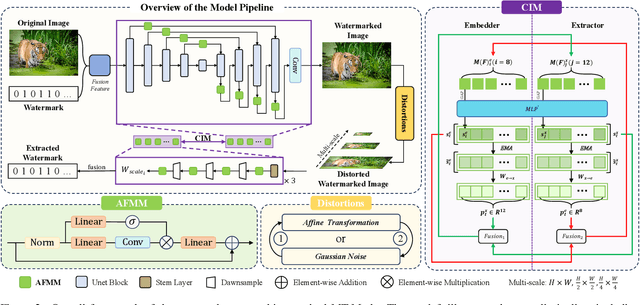
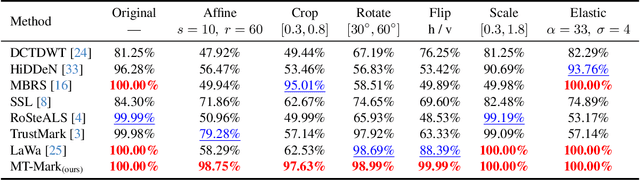
Existing deep image watermarking methods follow a fixed embedding-distortion-extraction pipeline, where the embedder and extractor are weakly coupled through a final loss and optimized in isolation. This design lacks explicit collaboration, leaving no structured mechanism for the embedder to incorporate decoding-aware cues or for the extractor to guide embedding during training. To address this architectural limitation, we rethink deep image watermarking by reformulating embedding and extraction as explicitly collaborative components. To realize this reformulation, we introduce a Collaborative Interaction Mechanism (CIM) that establishes direct, bidirectional communication between the embedder and extractor, enabling a mutual-teacher training paradigm and coordinated optimization. Built upon this explicitly collaborative architecture, we further propose an Adaptive Feature Modulation Module (AFMM) to support effective interaction. AFMM enables content-aware feature regulation by decoupling modulation structure and strength, guiding watermark embedding toward stable image features while suppressing host interference during extraction. Under CIM, the AFMMs on both sides form a closed-loop collaboration that aligns embedding behavior with extraction objectives. This architecture-level redesign changes how robustness is learned in watermarking systems. Rather than relying on exhaustive distortion simulation, robustness emerges from coordinated representation learning between embedding and extraction. Experiments on real-world and AI-generated datasets demonstrate that the proposed method consistently outperforms state-of-the-art approaches in watermark extraction accuracy while maintaining high perceptual quality, showing strong robustness and generalization.
MELDAE: A Framework for Micro-Expression Spotting, Detection, and Automatic Evaluation in In-the-Wild Conversational Scenes
Oct 26, 2025Accurately analyzing spontaneous, unconscious micro-expressions is crucial for revealing true human emotions, but this task remains challenging in wild scenarios, such as natural conversation. Existing research largely relies on datasets from controlled laboratory environments, and their performance degrades dramatically in the real world. To address this issue, we propose three contributions: the first micro-expression dataset focused on conversational-in-the-wild scenarios; an end-to-end localization and detection framework, MELDAE; and a novel boundary-aware loss function that improves temporal accuracy by penalizing onset and offset errors. Extensive experiments demonstrate that our framework achieves state-of-the-art results on the WDMD dataset, improving the key F1_{DR} localization metric by 17.72% over the strongest baseline, while also demonstrating excellent generalization capabilities on existing benchmarks.
GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.
Pure-Pass: Fine-Grained, Adaptive Masking for Dynamic Token-Mixing Routing in Lightweight Image Super-Resolution
Oct 02, 2025Image Super-Resolution (SR) aims to reconstruct high-resolution images from low-resolution counterparts, but the computational complexity of deep learning-based methods often hinders practical deployment. CAMixer is the pioneering work to integrate the advantages of existing lightweight SR methods and proposes a content-aware mixer to route token mixers of varied complexities according to the difficulty of content recovery. However, several limitations remain, such as poor adaptability, coarse-grained masking and spatial inflexibility, among others. We propose Pure-Pass (PP), a pixel-level masking mechanism that identifies pure pixels and exempts them from expensive computations. PP utilizes fixed color center points to classify pixels into distinct categories, enabling fine-grained, spatially flexible masking while maintaining adaptive flexibility. Integrated into the state-of-the-art ATD-light model, PP-ATD-light achieves superior SR performance with minimal overhead, outperforming CAMixer-ATD-light in reconstruction quality and parameter efficiency when saving a similar amount of computation.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
RewardDance: Reward Scaling in Visual Generation
Sep 10, 2025Reward Models (RMs) are critical for improving generation models via Reinforcement Learning (RL), yet the RM scaling paradigm in visual generation remains largely unexplored. It primarily due to fundamental limitations in existing approaches: CLIP-based RMs suffer from architectural and input modality constraints, while prevalent Bradley-Terry losses are fundamentally misaligned with the next-token prediction mechanism of Vision-Language Models (VLMs), hindering effective scaling. More critically, the RLHF optimization process is plagued by Reward Hacking issue, where models exploit flaws in the reward signal without improving true quality. To address these challenges, we introduce RewardDance, a scalable reward modeling framework that overcomes these barriers through a novel generative reward paradigm. By reformulating the reward score as the model's probability of predicting a "yes" token, indicating that the generated image outperforms a reference image according to specific criteria, RewardDance intrinsically aligns reward objectives with VLM architectures. This alignment unlocks scaling across two dimensions: (1) Model Scaling: Systematic scaling of RMs up to 26 billion parameters; (2) Context Scaling: Integration of task-specific instructions, reference examples, and chain-of-thought (CoT) reasoning. Extensive experiments demonstrate that RewardDance significantly surpasses state-of-the-art methods in text-to-image, text-to-video, and image-to-video generation. Crucially, we resolve the persistent challenge of "reward hacking": Our large-scale RMs exhibit and maintain high reward variance during RL fine-tuning, proving their resistance to hacking and ability to produce diverse, high-quality outputs. It greatly relieves the mode collapse problem that plagues smaller models.