 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3D-Stereo: A Multiple-Medium and Multiple-Degradation Dataset for Stereo Image Restoration
Apr 14, 2026Image restoration under adverse conditions, such as underwater, haze or fog, and low-light environments, remains a highly challenging problem due to complex physical degradations and severe information loss. Existing datasets are predominantly limited to a single degradation type or heavily rely on synthetic data without stereo consistency, inherently restricting their applicability in real-world scenarios. To address this, we introduce M3D-Stereo, a stereo dataset with 7904 high-resolution image pairs for image restoration research acquired in multiple media with multiple controlled degradation levels. It encompasses four degradation scenarios: underwater scatter, haze/fog, underwater low-light, and haze low-light. Each scenario forms a subset, and is divided into six levels of progressive degradation, allowing fine-grained evaluations of restoration methods with increasing severity of degradation. Collected via a laboratory setup, the dataset provides aligned stereo image pairs along with their pixel-wise consistent clear ground truths. Two restoration tasks, single-level and mixed-level degradation, were performed to verify its validity. M3D-Stereo establishes a better controlled and more realistic benchmark to evaluate image restoration and stereo matching methods in complex degradation environments. It is made public under LGPLv3 license.
From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild
Mar 26, 2026The rise of micro-videos has reshaped how misinformation spreads, amplifying its speed, reach, and impact on public trust. Existing benchmarks typically focus on a single deception type, overlooking the diversity of real-world cases that involve multimodal manipulation, AI-generated content, cognitive bias, and out-of-context reuse. Meanwhile, most detection models lack fine-grained attribution, limiting interpretability and practical utility. To address these gaps, we introduce WildFakeBench, a large-scale benchmark of over 10,000 real-world micro-videos covering diverse misinformation types and sources, each annotated with expert-defined attribution labels. Building on this foundation, we develop FakeAgent, a Delphi-inspired multi-agent reasoning framework that integrates multimodal understanding with external evidence for attribution-grounded analysis. FakeAgent jointly analyzes content and retrieved evidence to identify manipulation, recognize cognitive and AI-generated patterns, and detect out-of-context misinformation. Extensive experiments show that FakeAgent consistently outperforms existing MLLMs across all misinformation types, while WildFakeBench provides a realistic and challenging testbed for advancing explainable micro-video misinformation detection. Data and code are available at: https://github.com/Aiyistan/FakeAgent.
Physics-Informed Spatial-Temporal Transformer for Terahertz Near-Field Beam Tracking
Mar 17, 2026Terahertz (THz) ultra-massive multiple-input multiple-output (UM-MIMO) promises ultra-high throughput, while its highly directional beams demand rapid and accurate beam tracking driven by precise user-state estimation. Moreover, large array apertures at high frequencies induce near-field propagation effects, where far-field modeling becomes inaccurate and near-field parametric channel estimation is costly. Bypassing near-field codebook, PAST-TT is proposed to bridge near-field tracking with low-overhead far-field codebook probing by exploiting parallax, amplified by widely spaced subarrays. With comb-type frequency-division multiplexing pilots, each subarray yields frequency-affine phase signatures whose frequency and temporal increments encode propagation delay and its variation between frames. Building on these signatures, a Parallax-Aware Spatial Transformer (PAST) compresses them and outputs per-frame position estimates with token reliability to downweight bad frames, regularized by a physics-in-the-loop consistency loss. A causal Temporal Transformer (TT) then performs reliability-aware filtering and prediction over a sliding window to initialize the beam of the next frame. Acting on short token sequences, PAST-TT avoids a monolithic spatial-temporal network over raw pilots, which keeps the model lightweight with a critical path latency of 0.61 ms. Simulations show that at 15 dB signal-to-noise ratio, PAST achieves 7.81 mm distance RMSE and 0.0588° angle RMSE. Even with a bad-frame rate of 0.1, TT reduces the distance and angle prediction RMSE by 23.1% and 32.8% compared with the best competing tracker.
CARE: A Molecular-Guided Foundation Model with Adaptive Region Modeling for Whole Slide Image Analysis
Feb 25, 2026Foundation models have recently achieved impressive success in computational pathology, demonstrating strong generalization across diverse histopathology tasks. However, existing models overlook the heterogeneous and non-uniform organization of pathological regions of interest (ROIs) because they rely on natural image backbones not tailored for tissue morphology. Consequently, they often fail to capture the coherent tissue architecture beyond isolated patches, limiting interpretability and clinical relevance. To address these challenges, we present Cross-modal Adaptive Region Encoder (CARE), a foundation model for pathology that automatically partitions WSIs into several morphologically relevant regions. Specifically, CARE employs a two-stage pretraining strategy: (1) a self-supervised unimodal pretraining stage that learns morphological representations from 34,277 whole-slide images (WSIs) without segmentation annotations, and (2) a cross-modal alignment stage that leverages RNA and protein profiles to refine the construction and representation of adaptive regions. This molecular guidance enables CARE to identify biologically relevant patterns and generate irregular yet coherent tissue regions, selecting the most representative area as ROI. CARE supports a broad range of pathology-related tasks, using either the ROI feature or the slide-level feature obtained by aggregating adaptive regions. Based on only one-tenth of the pretraining data typically used by mainstream foundation models, CARE achieves superior average performance across 33 downstream benchmarks, including morphological classification, molecular prediction, and survival analysis, and outperforms other foundation model baselines overall.
MT-Mark: Rethinking Image Watermarking via Mutual-Teacher Collaboration with Adaptive Feature Modulation
Dec 22, 2025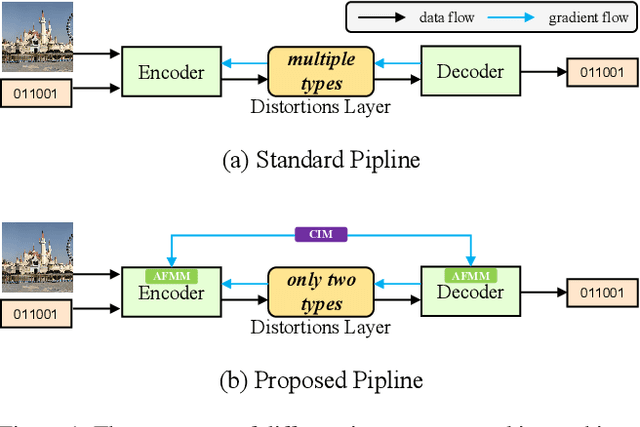
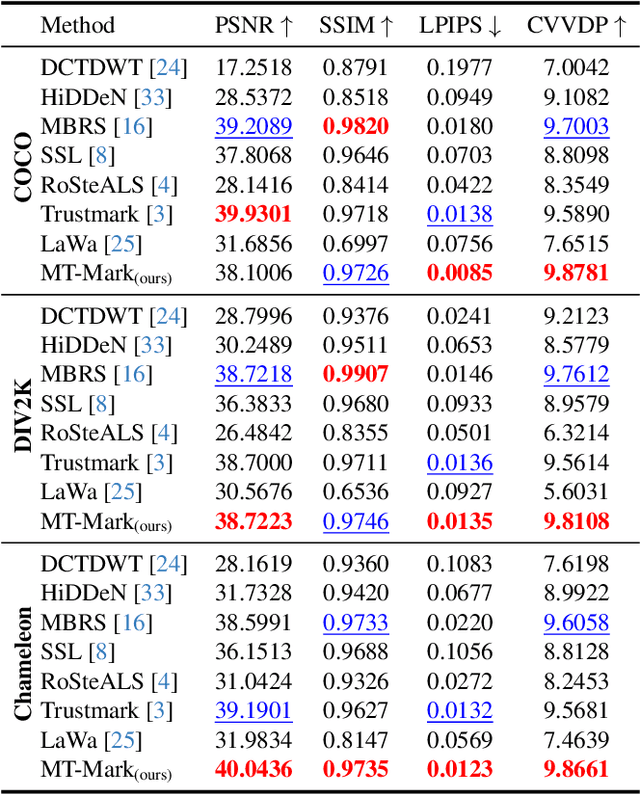
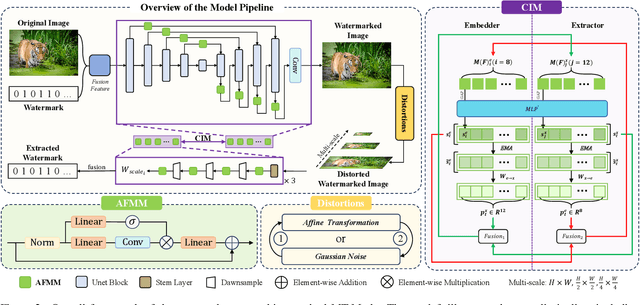
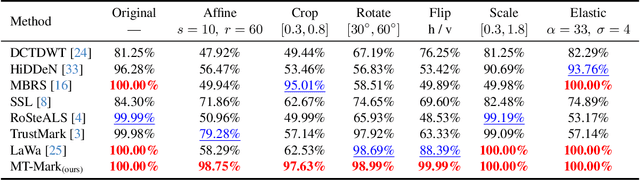
Existing deep image watermarking methods follow a fixed embedding-distortion-extraction pipeline, where the embedder and extractor are weakly coupled through a final loss and optimized in isolation. This design lacks explicit collaboration, leaving no structured mechanism for the embedder to incorporate decoding-aware cues or for the extractor to guide embedding during training. To address this architectural limitation, we rethink deep image watermarking by reformulating embedding and extraction as explicitly collaborative components. To realize this reformulation, we introduce a Collaborative Interaction Mechanism (CIM) that establishes direct, bidirectional communication between the embedder and extractor, enabling a mutual-teacher training paradigm and coordinated optimization. Built upon this explicitly collaborative architecture, we further propose an Adaptive Feature Modulation Module (AFMM) to support effective interaction. AFMM enables content-aware feature regulation by decoupling modulation structure and strength, guiding watermark embedding toward stable image features while suppressing host interference during extraction. Under CIM, the AFMMs on both sides form a closed-loop collaboration that aligns embedding behavior with extraction objectives. This architecture-level redesign changes how robustness is learned in watermarking systems. Rather than relying on exhaustive distortion simulation, robustness emerges from coordinated representation learning between embedding and extraction. Experiments on real-world and AI-generated datasets demonstrate that the proposed method consistently outperforms state-of-the-art approaches in watermark extraction accuracy while maintaining high perceptual quality, showing strong robustness and generalization.
DiFaR: Enhancing Multimodal Misinformation Detection with Diverse, Factual, and Relevant Rationales
Aug 14, 2025



Generating textual rationales from large vision-language models (LVLMs) to support trainable multimodal misinformation detectors has emerged as a promising paradigm. However, its effectiveness is fundamentally limited by three core challenges: (i) insufficient diversity in generated rationales, (ii) factual inaccuracies due to hallucinations, and (iii) irrelevant or conflicting content that introduces noise. We introduce DiFaR, a detector-agnostic framework that produces diverse, factual, and relevant rationales to enhance misinformation detection. DiFaR employs five chain-of-thought prompts to elicit varied reasoning traces from LVLMs and incorporates a lightweight post-hoc filtering module to select rationale sentences based on sentence-level factuality and relevance scores. Extensive experiments on four popular benchmarks demonstrate that DiFaR outperforms four baseline categories by up to 5.9% and boosts existing detectors by as much as 8.7%. Both automatic metrics and human evaluations confirm that DiFaR significantly improves rationale quality across all three dimensions.
RealityAvatar: Towards Realistic Loose Clothing Modeling in Animatable 3D Gaussian Avatars
Apr 02, 2025



Modeling animatable human avatars from monocular or multi-view videos has been widely studied, with recent approaches leveraging neural radiance fields (NeRFs) or 3D Gaussian Splatting (3DGS) achieving impressive results in novel-view and novel-pose synthesis. However, existing methods often struggle to accurately capture the dynamics of loose clothing, as they primarily rely on global pose conditioning or static per-frame representations, leading to oversmoothing and temporal inconsistencies in non-rigid regions. To address this, We propose RealityAvatar, an efficient framework for high-fidelity digital human modeling, specifically targeting loosely dressed avatars. Our method leverages 3D Gaussian Splatting to capture complex clothing deformations and motion dynamics while ensuring geometric consistency. By incorporating a motion trend module and a latentbone encoder, we explicitly model pose-dependent deformations and temporal variations in clothing behavior. Extensive experiments on benchmark datasets demonstrate the effectiveness of our approach in capturing fine-grained clothing deformations and motion-driven shape variations. Our method significantly enhances structural fidelity and perceptual quality in dynamic human reconstruction, particularly in non-rigid regions, while achieving better consistency across temporal frames.
Each Fake News is Fake in its Own Way: An Attribution Multi-Granularity Benchmark for Multimodal Fake News Detection
Dec 19, 2024



Social platforms, while facilitating access to information, have also become saturated with a plethora of fake news, resulting in negative consequences. Automatic multimodal fake news detection is a worthwhile pursuit. Existing multimodal fake news datasets only provide binary labels of real or fake. However, real news is alike, while each fake news is fake in its own way. These datasets fail to reflect the mixed nature of various types of multimodal fake news. To bridge the gap, we construct an attributing multi-granularity multimodal fake news detection dataset \amg, revealing the inherent fake pattern. Furthermore, we propose a multi-granularity clue alignment model \our to achieve multimodal fake news detection and attribution. Experimental results demonstrate that \amg is a challenging dataset, and its attribution setting opens up new avenues for future research.
DiffMAC: Diffusion Manifold Hallucination Correction for High Generalization Blind Face Restoration
Mar 15, 2024Blind face restoration (BFR) is a highly challenging problem due to the uncertainty of degradation patterns. Current methods have low generalization across photorealistic and heterogeneous domains. In this paper, we propose a Diffusion-Information-Diffusion (DID) framework to tackle diffusion manifold hallucination correction (DiffMAC), which achieves high-generalization face restoration in diverse degraded scenes and heterogeneous domains. Specifically, the first diffusion stage aligns the restored face with spatial feature embedding of the low-quality face based on AdaIN, which synthesizes degradation-removal results but with uncontrollable artifacts for some hard cases. Based on Stage I, Stage II considers information compression using manifold information bottleneck (MIB) and finetunes the first diffusion model to improve facial fidelity. DiffMAC effectively fights against blind degradation patterns and synthesizes high-quality faces with attribute and identity consistencies. Experimental results demonstrate the superiority of DiffMAC over state-of-the-art methods, with a high degree of generalization in real-world and heterogeneous settings. The source code and models will be public.
GO-FEAP: Global Optimal UAV Planner Using Frontier-Omission-Aware Exploration and Altitude-Stratified Planning
Oct 24, 2023Autonomous exploration is a fundamental problem for various applications of unmanned aerial vehicles(UAVs). Existing methods, however, are demonstrated to static local optima and two-dimensional exploration. To address these challenges, this paper introduces GO-FEAP (Global Optimal UAV Planner Using Frontier-Omission-Aware Exploration and Altitude-Stratified Planning), aiming to achieve efficient and complete three-dimensional exploration. Frontier-Omission-Aware Exploration module presented in this work takes into account multiple pivotal factors, encompassing frontier distance, nearby frontier count, frontier duration, and frontier categorization, for a comprehensive assessment of frontier importance. Furthermore, to tackle scenarios with substantial vertical variations, we introduce the Altitude-Stratified Planning strategy, which stratifies the three-dimensional space based on altitude, conducting global-local planning for each stratum. The objective of global planning is to identify the most optimal frontier for exploration, followed by viewpoint selection and local path optimization based on frontier type, ultimately generating dynamically feasible three-dimensional spatial exploration trajectories. We present extensive benchmark and real-world tests, in which our method completes the exploration tasks with unprecedented completeness compared to state-of-the-art approaches.