 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-Mark: Rethinking Image Watermarking via Mutual-Teacher Collaboration with Adaptive Feature Modulation
Dec 22, 2025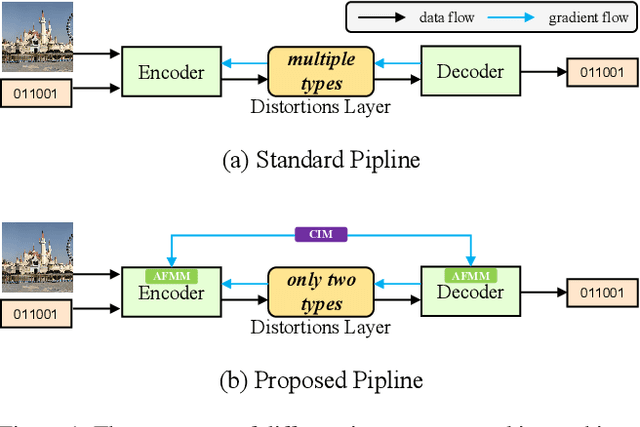
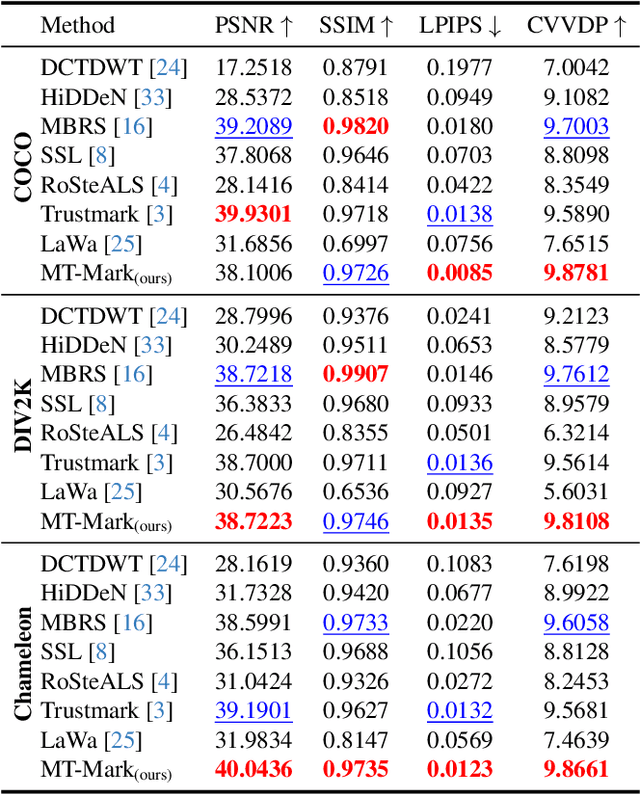
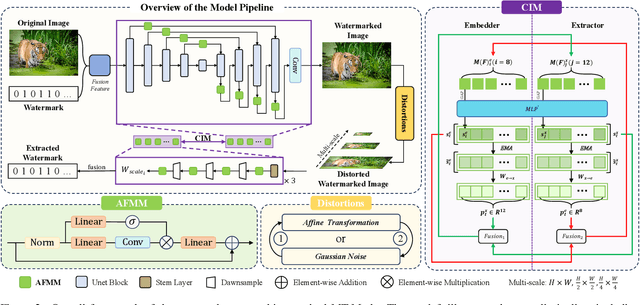
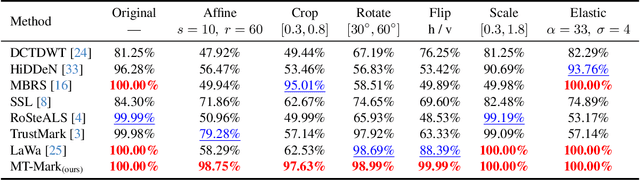
Existing deep image watermarking methods follow a fixed embedding-distortion-extraction pipeline, where the embedder and extractor are weakly coupled through a final loss and optimized in isolation. This design lacks explicit collaboration, leaving no structured mechanism for the embedder to incorporate decoding-aware cues or for the extractor to guide embedding during training. To address this architectural limitation, we rethink deep image watermarking by reformulating embedding and extraction as explicitly collaborative components. To realize this reformulation, we introduce a Collaborative Interaction Mechanism (CIM) that establishes direct, bidirectional communication between the embedder and extractor, enabling a mutual-teacher training paradigm and coordinated optimization. Built upon this explicitly collaborative architecture, we further propose an Adaptive Feature Modulation Module (AFMM) to support effective interaction. AFMM enables content-aware feature regulation by decoupling modulation structure and strength, guiding watermark embedding toward stable image features while suppressing host interference during extraction. Under CIM, the AFMMs on both sides form a closed-loop collaboration that aligns embedding behavior with extraction objectives. This architecture-level redesign changes how robustness is learned in watermarking systems. Rather than relying on exhaustive distortion simulation, robustness emerges from coordinated representation learning between embedding and extraction. Experiments on real-world and AI-generated datasets demonstrate that the proposed method consistently outperforms state-of-the-art approaches in watermark extraction accuracy while maintaining high perceptual quality, showing strong robustness and generalization.
Frequency-Integrated Transformer for Arbitrary-Scale Super-Resolution
Apr 26, 2025Methods based on implicit neural representation have demonstrated remarkable capabilities in arbitrary-scale super-resolution (ASSR) tasks, but they neglect the potential value of the frequency domain, leading to sub-optimal performance. We proposes a novel network called Frequency-Integrated Transformer (FIT) to incorporate and utilize frequency information to enhance ASSR performance. FIT employs Frequency Incorporation Module (FIM) to introduce frequency information in a lossless manner and Frequency Utilization Self-Attention module (FUSAM) to efficiently leverage frequency information by exploiting spatial-frequency interrelationship and global nature of frequency. FIM enriches detail characterization by incorporating frequency information through a combination of Fast Fourier Transform (FFT) with real-imaginary mapping. In FUSAM, Interaction Implicit Self-Attention (IISA) achieves cross-domain information synergy by interacting spatial and frequency information in subspace, while Frequency Correlation Self-attention (FCSA) captures the global context by computing correlation in frequency. Experimental results demonstrate FIT yields superior performance compared to existing methods across multiple benchmark datasets. Visual feature map proves the superiority of FIM in enriching detail characterization. Frequency error map validates IISA productively improve the frequency fidelity. Local attribution map validates FCSA effectively captures global context.