 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Linguistic Fragility in Vision-Language-Action Models via Diversity-Aware Red Teaming
Apr 07, 2026Vision-Language-Action (VLA) models have achieved remarkable success in robotic manipulation. However, their robustness to linguistic nuances remains a critical, under-explored safety concern, posing a significant safety risk to real-world deployment. Red teaming, or identifying environmental scenarios that elicit catastrophic behaviors, is an important step in ensuring the safe deployment of embodied AI agents. Reinforcement learning (RL) has emerged as a promising approach in automated red teaming that aims to uncover these vulnerabilities. However, standard RL-based adversaries often suffer from severe mode collapse due to their reward-maximizing nature, which tends to converge to a narrow set of trivial or repetitive failure patterns, failing to reveal the comprehensive landscape of meaningful risks. To bridge this gap, we propose a novel \textbf{D}iversity-\textbf{A}ware \textbf{E}mbodied \textbf{R}ed \textbf{T}eaming (\textbf{DAERT}) framework, to expose the vulnerabilities of VLAs against linguistic variations. Our design is based on evaluating a uniform policy, which is able to generate a diverse set of challenging instructions while ensuring its attack effectiveness, measured by execution failures in a physical simulator. We conduct extensive experiments across different robotic benchmarks against two state-of-the-art VLAs, including $π_0$ and OpenVLA. Our method consistently discovers a wider range of more effective adversarial instructions that reduce the average task success rate from 93.33\% to 5.85\%, demonstrating a scalable approach to stress-testing VLA agents and exposing critical safety blind spots before real-world deployment.
Complementary Reinforcement Learning
Mar 18, 2026Reinforcement Learning (RL) has emerged as a powerful paradigm for training LLM-based agents, yet remains limited by low sample efficiency, stemming not only from sparse outcome feedback but also from the agent's inability to leverage prior experience across episodes. While augmenting agents with historical experience offers a promising remedy, existing approaches suffer from a critical weakness: the experience distilled from history is either stored statically or fail to coevolve with the improving actor, causing a progressive misalignment between the experience and the actor's evolving capability that diminishes its utility over the course of training. Inspired by complementary learning systems in neuroscience, we present Complementary RL to achieve seamless co-evolution of an experience extractor and a policy actor within the RL optimization loop. Specifically, the actor is optimized via sparse outcome-based rewards, while the experience extractor is optimized according to whether its distilled experiences demonstrably contribute to the actor's success, thereby evolving its experience management strategy in lockstep with the actor's growing capabilities. Empirically, Complementary RL outperforms outcome-based agentic RL baselines that do not learn from experience, achieving 10% performance improvement in single-task scenarios and exhibits robust scalability in multi-task settings. These results establish Complementary RL as a paradigm for efficient experience-driven agent learning.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
GARDO: Reinforcing Diffusion Models without Reward Hacking
Dec 30, 2025Fine-tuning diffusion models via online reinforcement learning (RL) has shown great potential for enhancing text-to-image alignment. However, since precisely specifying a ground-truth objective for visual tasks remains challenging, the models are often optimized using a proxy reward that only partially captures the true goal. This mismatch often leads to reward hacking, where proxy scores increase while real image quality deteriorates and generation diversity collapses. While common solutions add regularization against the reference policy to prevent reward hacking, they compromise sample efficiency and impede the exploration of novel, high-reward regions, as the reference policy is usually sub-optimal. To address the competing demands of sample efficiency, effective exploration, and mitigation of reward hacking, we propose Gated and Adaptive Regularization with Diversity-aware Optimization (GARDO), a versatile framework compatible with various RL algorithms. Our key insight is that regularization need not be applied universally; instead, it is highly effective to selectively penalize a subset of samples that exhibit high uncertainty. To address the exploration challenge, GARDO introduces an adaptive regularization mechanism wherein the reference model is periodically updated to match the capabilities of the online policy, ensuring a relevant regularization target. To address the mode collapse issue in RL, GARDO amplifies the rewards for high-quality samples that also exhibit high diversity, encouraging mode coverage without destabilizing the optimization process. Extensive experiments across diverse proxy rewards and hold-out unseen metrics consistently show that GARDO mitigates reward hacking and enhances generation diversity without sacrificing sample efficiency or exploration, highlighting its effectiveness and robustness.
Asymmetric Proximal Policy Optimization: mini-critics boost LLM reasoning
Oct 02, 2025Most recent RL for LLMs (RL4LLM) methods avoid explicit critics, replacing them with average advantage baselines. This shift is largely pragmatic: conventional value functions are computationally expensive to train at LLM scale and often fail under sparse rewards and long reasoning horizons. We revisit this bottleneck from an architectural perspective and introduce Asymmetric Proximal Policy Optimization (AsyPPO), a simple and scalable framework that restores the critics role while remaining efficient in large-model settings. AsyPPO employs a set of lightweight mini-critics, each trained on disjoint prompt shards. This design encourages diversity while preserving calibration, reducing value-estimation bias. Beyond robust estimation, AsyPPO leverages inter-critic uncertainty to refine the policy update: (i) masking advantages in states where critics agree and gradients add little learning signal, and (ii) filtering high-divergence states from entropy regularization, suppressing spurious exploration. After training on open-source data with only 5,000 samples, AsyPPO consistently improves learning stability and performance across multiple benchmarks over strong baselines, such as GRPO, achieving performance gains of more than six percent on Qwen3-4b-Base and about three percent on Qwen3-8b-Base and Qwen3-14b-Base over classic PPO, without additional tricks. These results highlight the importance of architectural innovations for scalable, efficient algorithms.
Generative Flow Networks for Personalized Multimedia Systems: A Case Study on Short Video Feeds
Aug 23, 2025Multimedia systems underpin modern digital interactions, facilitating seamless integration and optimization of resources across diverse multimedia applications. To meet growing personalization demands, multimedia systems must efficiently manage competing resource needs, adaptive content, and user-specific data handling. This paper introduces Generative Flow Networks (GFlowNets, GFNs) as a brave new framework for enabling personalized multimedia systems. By integrating multi-candidate generative modeling with flow-based principles, GFlowNets offer a scalable and flexible solution for enhancing user-specific multimedia experiences. To illustrate the effectiveness of GFlowNets, we focus on short video feeds, a multimedia application characterized by high personalization demands and significant resource constraints, as a case study. Our proposed GFlowNet-based personalized feeds algorithm demonstrates superior performance compared to traditional rule-based and reinforcement learning methods across critical metrics, including video quality, resource utilization efficiency, and delivery cost. Moreover, we propose a unified GFlowNet-based framework generalizable to other multimedia systems, highlighting its adaptability and wide-ranging applicability. These findings underscore the potential of GFlowNets to advance personalized multimedia systems by addressing complex optimization challenges and supporting sophisticated multimedia application scenarios.
Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning
Aug 11, 2025Reinforcement learning for LLM reasoning has rapidly emerged as a prominent research area, marked by a significant surge in related studies on both algorithmic innovations and practical applications. Despite this progress, several critical challenges remain, including the absence of standardized guidelines for employing RL techniques and a fragmented understanding of their underlying mechanisms. Additionally, inconsistent experimental settings, variations in training data, and differences in model initialization have led to conflicting conclusions, obscuring the key characteristics of these techniques and creating confusion among practitioners when selecting appropriate techniques. This paper systematically reviews widely adopted RL techniques through rigorous reproductions and isolated evaluations within a unified open-source framework. We analyze the internal mechanisms, applicable scenarios, and core principles of each technique through fine-grained experiments, including datasets of varying difficulty, model sizes, and architectures. Based on these insights, we present clear guidelines for selecting RL techniques tailored to specific setups, and provide a reliable roadmap for practitioners navigating the RL for the LLM domain. Finally, we reveal that a minimalist combination of two techniques can unlock the learning capability of critic-free policies using vanilla PPO loss. The results demonstrate that our simple combination consistently improves performance, surpassing strategies like GRPO and DAPO.
The Courage to Stop: Overcoming Sunk Cost Fallacy in Deep Reinforcement Learning
Jun 16, 2025



Off-policy deep reinforcement learning (RL) typically leverages replay buffers for reusing past experiences during learning. This can help improve sample efficiency when the collected data is informative and aligned with the learning objectives; when that is not the case, it can have the effect of "polluting" the replay buffer with data which can exacerbate optimization challenges in addition to wasting environment interactions due to wasteful sampling. We argue that sampling these uninformative and wasteful transitions can be avoided by addressing the sunk cost fallacy, which, in the context of deep RL, is the tendency towards continuing an episode until termination. To address this, we propose learn to stop (LEAST), a lightweight mechanism that enables strategic early episode termination based on Q-value and gradient statistics, which helps agents recognize when to terminate unproductive episodes early. We demonstrate that our method improves learning efficiency on a variety of RL algorithms, evaluated on both the MuJoCo and DeepMind Control Suite benchmarks.
Measure gradients, not activations! Enhancing neuronal activity in deep reinforcement learning
May 29, 2025Deep reinforcement learning (RL) agents frequently suffer from neuronal activity loss, which impairs their ability to adapt to new data and learn continually. A common method to quantify and address this issue is the tau-dormant neuron ratio, which uses activation statistics to measure the expressive ability of neurons. While effective for simple MLP-based agents, this approach loses statistical power in more complex architectures. To address this, we argue that in advanced RL agents, maintaining a neuron's learning capacity, its ability to adapt via gradient updates, is more critical than preserving its expressive ability. Based on this insight, we shift the statistical objective from activations to gradients, and introduce GraMa (Gradient Magnitude Neural Activity Metric), a lightweight, architecture-agnostic metric for quantifying neuron-level learning capacity. We show that GraMa effectively reveals persistent neuron inactivity across diverse architectures, including residual networks, diffusion models, and agents with varied activation functions. Moreover, resetting neurons guided by GraMa (ReGraMa) consistently improves learning performance across multiple deep RL algorithms and benchmarks, such as MuJoCo and the DeepMind Control Suite.
Scaling Image and Video Generation via Test-Time Evolutionary Search
May 23, 2025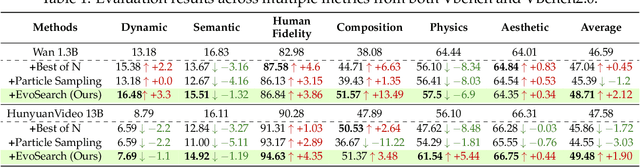

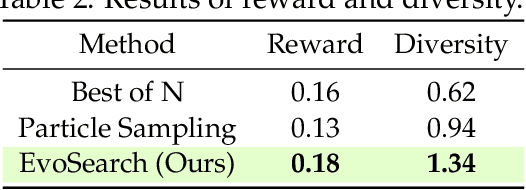
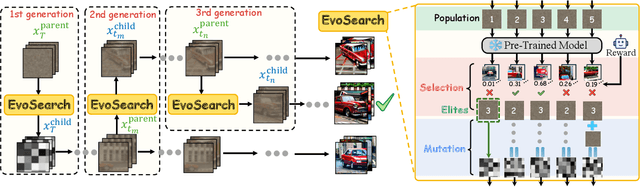
As the marginal cost of scaling computation (data and parameters) during model pre-training continues to increase substantially, test-time scaling (TTS) has emerged as a promising direction for improving generative model performance by allocating additional computation at inference time. While TTS has demonstrated significant success across multiple language tasks, there remains a notable gap in understanding the test-time scaling behaviors of image and video generative models (diffusion-based or flow-based models). Although recent works have initiated exploration into inference-time strategies for vision tasks, these approaches face critical limitations: being constrained to task-specific domains, exhibiting poor scalability, or falling into reward over-optimization that sacrifices sample diversity. In this paper, we propose \textbf{Evo}lutionary \textbf{Search} (EvoSearch), a novel, generalist, and efficient TTS method that effectively enhances the scalability of both image and video generation across diffusion and flow models, without requiring additional training or model expansion. EvoSearch reformulates test-time scaling for diffusion and flow models as an evolutionary search problem, leveraging principles from biological evolution to efficiently explore and refine the denoising trajectory. By incorporating carefully designed selection and mutation mechanisms tailored to the stochastic differential equation denoising process, EvoSearch iteratively generates higher-quality offspring while preserving population diversity. Through extensive evaluation across both diffusion and flow architectures for image and video generation tasks, we demonstrate that our method consistently outperforms existing approaches, achieves higher diversity, and shows strong generalizability to unseen evaluation metrics. Our project is available at the website https://tinnerhrhe.github.io/evosearch.