 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINT-Bench: A Comprehensive Multilingual Benchmark for Instruction-Following Text-to-Speech
Apr 20, 2026Instruction-following text-to-speech (TTS) has emerged as an important capability for controllable and expressive speech generation, yet its evaluation remains underdeveloped due to limited benchmark coverage, weak diagnostic granularity, and insufficient multilingual support. We present \textbf{MINT-Bench}, a comprehensive multilingual benchmark for instruction-following TTS. MINT-Bench is built upon a hierarchical multi-axis taxonomy, a scalable multi-stage data construction pipeline, and a hierarchical hybrid evaluation protocol that jointly assesses content consistency, instruction following, and perceptual quality. Experiments across ten languages show that current systems remain far from solved: frontier commercial systems lead overall, while leading open-source models become highly competitive and can even outperform commercial counterparts in localized settings such as Chinese. The benchmark further reveals that harder compositional and paralinguistic controls remain major bottlenecks for current systems. We release MINT-Bench together with the data construction and evaluation toolkit to support future research on controllable, multilingual, and diagnostically grounded TTS evaluation. The leaderboard and demo are available at https://longwaytog0.github.io/MINT-Bench/
VoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
FlexSpeech: Towards Stable, Controllable and Expressive Text-to-Speech
May 08, 2025Current speech generation research can be categorized into two primary classes: non-autoregressive and autoregressive. The fundamental distinction between these approaches lies in the duration prediction strategy employed for predictable-length sequences. The NAR methods ensure stability in speech generation by explicitly and independently modeling the duration of each phonetic unit. Conversely, AR methods employ an autoregressive paradigm to predict the compressed speech token by implicitly modeling duration with Markov properties. Although this approach improves prosody, it does not provide the structural guarantees necessary for stability. To simultaneously address the issues of stability and naturalness in speech generation, we propose FlexSpeech, a stable, controllable, and expressive TTS model. The motivation behind FlexSpeech is to incorporate Markov dependencies and preference optimization directly on the duration predictor to boost its naturalness while maintaining explicit modeling of the phonetic units to ensure stability. Specifically, we decompose the speech generation task into two components: an AR duration predictor and a NAR acoustic model. The acoustic model is trained on a substantial amount of data to learn to render audio more stably, given reference audio prosody and phone durations. The duration predictor is optimized in a lightweight manner for different stylistic variations, thereby enabling rapid style transfer while maintaining a decoupled relationship with the specified speaker timbre. Experimental results demonstrate that our approach achieves SOTA stability and naturalness in zero-shot TTS. More importantly, when transferring to a specific stylistic domain, we can accomplish lightweight optimization of the duration module solely with about 100 data samples, without the need to adjust the acoustic model, thereby enabling rapid and stable style transfer.
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Jun 14, 2024

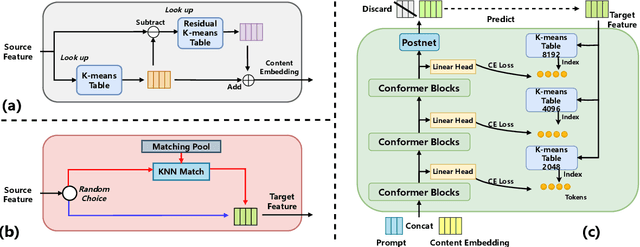

Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
Jun 11, 2024



With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains $12,800$ hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.
Accent-VITS:accent transfer for end-to-end TTS
Dec 29, 2023


Accent transfer aims to transfer an accent from a source speaker to synthetic speech in the target speaker's voice. The main challenge is how to effectively disentangle speaker timbre and accent which are entangled in speech. This paper presents a VITS-based end-to-end accent transfer model named Accent-VITS.Based on the main structure of VITS, Accent-VITS makes substantial improvements to enable effective and stable accent transfer.We leverage a hierarchical CVAE structure to model accent pronunciation information and acoustic features, respectively, using bottleneck features and mel spectrums as constraints.Moreover, the text-to-wave mapping in VITS is decomposed into text-to-accent and accent-to-wave mappings in Accent-VITS. In this way, the disentanglement of accent and speaker timbre becomes be more stable and effective.Experiments on multi-accent and Mandarin datasets show that Accent-VITS achieves higher speaker similarity, accent similarity and speech naturalness as compared with a strong baseline.