 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025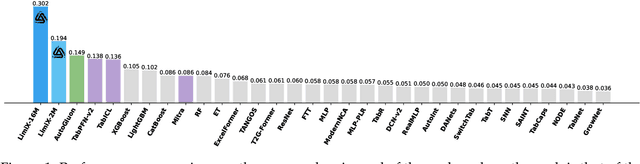
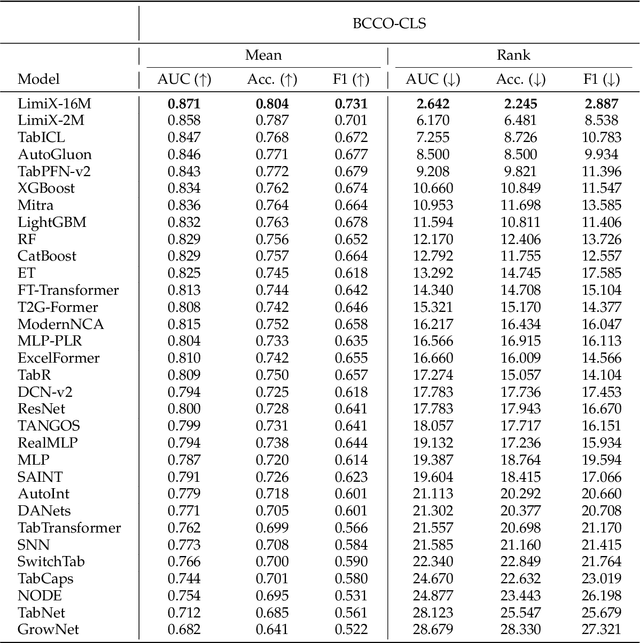
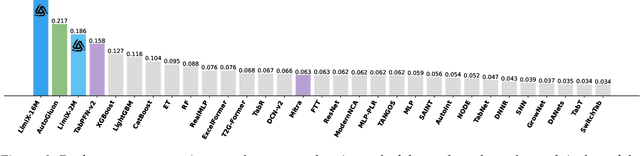
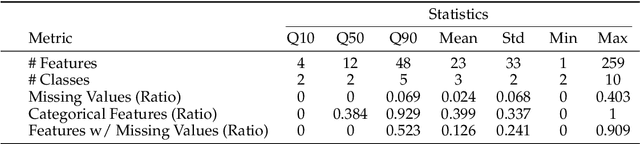
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Group Expectation Policy Optimization for Stable Heterogeneous Reinforcement Learning in LLMs
Aug 25, 2025As single-center computing approaches power constraints, decentralized training is becoming essential. Reinforcement Learning (RL) post-training enhances Large Language Models (LLMs) but faces challenges in heterogeneous distributed environments due to its tightly-coupled sampling-learning alternation. We propose HeteroRL, an asynchronous RL architecture that decouples rollout sampling from parameter learning, enabling robust deployment across geographically distributed nodes under network delays. We identify that latency-induced KL divergence causes importance sampling failure due to high variance. To address this, we propose Group Expectation Policy Optimization (GEPO), which reduces importance weight variance through a refined sampling mechanism. Theoretically, GEPO achieves exponential variance reduction. Experiments show it maintains superior stability over methods like GRPO, with less than 3% performance degradation under 1800-second delays, demonstrating strong potential for decentralized RL in heterogeneous networks.
PCR-CA: Parallel Codebook Representations with Contrastive Alignment for Multiple-Category App Recommendation
Aug 25, 2025Modern app store recommender systems struggle with multiple-category apps, as traditional taxonomies fail to capture overlapping semantics, leading to suboptimal personalization. We propose PCR-CA (Parallel Codebook Representations with Contrastive Alignment), an end-to-end framework for improved CTR prediction. PCR-CA first extracts compact multimodal embeddings from app text, then introduces a Parallel Codebook VQ-AE module that learns discrete semantic representations across multiple codebooks in parallel -- unlike hierarchical residual quantization (RQ-VAE). This design enables independent encoding of diverse aspects (e.g., gameplay, art style), better modeling multiple-category semantics. To bridge semantic and collaborative signals, we employ a contrastive alignment loss at both the user and item levels, enhancing representation learning for long-tail items. Additionally, a dual-attention fusion mechanism combines ID-based and semantic features to capture user interests, especially for long-tail apps. Experiments on a large-scale dataset show PCR-CA achieves a +0.76% AUC improvement over strong baselines, with +2.15% AUC gains for long-tail apps. Online A/B testing further validates our approach, showing a +10.52% lift in CTR and a +16.30% improvement in CVR, demonstrating PCR-CA's effectiveness in real-world deployment. The new framework has now been fully deployed on the Microsoft Store.
LGE-Guided Cross-Modality Contrastive Learning for Gadolinium-Free Cardiomyopathy Screening in Cine CMR
Aug 23, 2025Cardiomyopathy, a principal contributor to heart failure and sudden cardiac mortality, demands precise early screening. Cardiac Magnetic Resonance (CMR), recognized as the diagnostic 'gold standard' through multiparametric protocols, holds the potential to serve as an accurate screening tool. However, its reliance on gadolinium contrast and labor-intensive interpretation hinders population-scale deployment. We propose CC-CMR, a Contrastive Learning and Cross-Modal alignment framework for gadolinium-free cardiomyopathy screening using cine CMR sequences. By aligning the latent spaces of cine CMR and Late Gadolinium Enhancement (LGE) sequences, our model encodes fibrosis-specific pathology into cine CMR embeddings. A Feature Interaction Module concurrently optimizes diagnostic precision and cross-modal feature congruence, augmented by an uncertainty-guided adaptive training mechanism that dynamically calibrates task-specific objectives to ensure model generalizability. Evaluated on multi-center data from 231 subjects, CC-CMR achieves accuracy of 0.943 (95% CI: 0.886-0.986), outperforming state-of-the-art cine-CMR-only models by 4.3% while eliminating gadolinium dependency, demonstrating its clinical viability for wide range of populations and healthcare environments.
SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models
Aug 08, 2025The Speaker Diarization and Recognition (SDR) task aims to predict "who spoke when and what" within an audio clip, which is a crucial task in various real-world multi-speaker scenarios such as meeting transcription and dialogue systems. Existing SDR systems typically adopt a cascaded framework, combining multiple modules such as speaker diarization (SD) and automatic speech recognition (ASR). The cascaded systems suffer from several limitations, such as error propagation, difficulty in handling overlapping speech, and lack of joint optimization for exploring the synergy between SD and ASR tasks. To address these limitations, we introduce SpeakerLM, a unified multimodal large language model for SDR that jointly performs SD and ASR in an end-to-end manner. Moreover, to facilitate diverse real-world scenarios, we incorporate a flexible speaker registration mechanism into SpeakerLM, enabling SDR under different speaker registration settings. SpeakerLM is progressively developed with a multi-stage training strategy on large-scale real data. Extensive experiments show that SpeakerLM demonstrates strong data scaling capability and generalizability, outperforming state-of-the-art cascaded baselines on both in-domain and out-of-domain public SDR benchmarks. Furthermore, experimental results show that the proposed speaker registration mechanism effectively ensures robust SDR performance of SpeakerLM across diverse speaker registration conditions and varying numbers of registered speakers.
SoftSignSGD(S3): An Enhanced Optimizer for Practical DNN Training and Loss Spikes Minimization Beyond Adam
Jul 09, 2025Adam has proven remarkable successful in training deep neural networks, but the mechanisms underlying its empirical successes and limitations remain underexplored. In this study, we demonstrate that the effectiveness of Adam stems largely from its similarity to SignSGD in robustly handling large gradient fluctuations, yet it is also vulnerable to destabilizing loss spikes due to its uncontrolled update scaling. To enhance the advantage of Adam and mitigate its limitation, we propose SignSoftSGD (S3), a novel optimizer with three key innovations. \emph{First}, S3 generalizes the sign-like update by employing a flexible $p$-th order momentum ($p \geq 1$) in the denominator, departing from the conventional second-order momentum (variance) preconditioning. This design enables enhanced performance while achieving stable training even with aggressive learning rates. \emph{Second}, S3 minimizes the occurrences of loss spikes through unified exponential moving average coefficients for numerator and denominator momenta, which inherently bound updates to $[-1, 1]$ and simplify hyperparameter tuning. \emph{Third}, S3 incorporates an equivalent Nesterov's accelerated gradient(NAG) module, accelerating convergence without memory overhead. Theoretically, we prove that S3 achieves the optimal convergence rate of $O\left(\frac{1}{T^{\sfrac{1}{4}}}\right)$ for general nonconvex stochastic optimization under weak assumptions. Extensive experiments across a range of vision and language tasks show that \textsf{\small S3} not only converges more rapidly and improves performance but also rarely experiences loss spikes, even with a \textbf{$\bm{10 \times}$} larger learning rate. In fact, S3 delivers performance comparable to or better than AdamW with \textbf{$2 \times$} the training steps, establishing its efficacy in both efficiency and final task performance.
SecFwT: Efficient Privacy-Preserving Fine-Tuning of Large Language Models Using Forward-Only Passes
Jun 18, 2025Large language models (LLMs) have transformed numerous fields, yet their adaptation to specialized tasks in privacy-sensitive domains, such as healthcare and finance, is constrained by the scarcity of accessible training data due to stringent privacy requirements. Secure multi-party computation (MPC)-based privacy-preserving machine learning offers a powerful approach to protect both model parameters and user data, but its application to LLMs has been largely limited to inference, as fine-tuning introduces significant computational challenges, particularly in privacy-preserving backward propagation and optimizer operations. This paper identifies two primary obstacles to MPC-based privacy-preserving fine-tuning of LLMs: (1) the substantial computational overhead of backward and optimizer processes, and (2) the inefficiency of softmax-based attention mechanisms in MPC settings. To address these challenges, we propose SecFwT, the first MPC-based framework designed for efficient, privacy-preserving LLM fine-tuning. SecFwT introduces a forward-only tuning paradigm to eliminate backward and optimizer computations and employs MPC-friendly Random Feature Attention to approximate softmax attention, significantly reducing costly non-linear operations and computational complexity. Experimental results demonstrate that SecFwT delivers substantial improvements in efficiency and privacy preservation, enabling scalable and secure fine-tuning of LLMs for privacy-critical applications.
StreamMel: Real-Time Zero-shot Text-to-Speech via Interleaved Continuous Autoregressive Modeling
Jun 14, 2025Recent advances in zero-shot text-to-speech (TTS) synthesis have achieved high-quality speech generation for unseen speakers, but most systems remain unsuitable for real-time applications because of their offline design. Current streaming TTS paradigms often rely on multi-stage pipelines and discrete representations, leading to increased computational cost and suboptimal system performance. In this work, we propose StreamMel, a pioneering single-stage streaming TTS framework that models continuous mel-spectrograms. By interleaving text tokens with acoustic frames, StreamMel enables low-latency, autoregressive synthesis while preserving high speaker similarity and naturalness. Experiments on LibriSpeech demonstrate that StreamMel outperforms existing streaming TTS baselines in both quality and latency. It even achieves performance comparable to offline systems while supporting efficient real-time generation, showcasing broad prospects for integration with real-time speech large language models. Audio samples are available at: https://aka.ms/StreamMel.
OmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Jun 11, 2025Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
TC-GS: A Faster Gaussian Splatting Module Utilizing Tensor Cores
May 30, 20253D Gaussian Splatting (3DGS) renders pixels by rasterizing Gaussian primitives, where conditional alpha-blending dominates the time cost in the rendering pipeline. This paper proposes TC-GS, an algorithm-independent universal module that expands Tensor Core (TCU) applicability for 3DGS, leading to substantial speedups and seamless integration into existing 3DGS optimization frameworks. The key innovation lies in mapping alpha computation to matrix multiplication, fully utilizing otherwise idle TCUs in existing 3DGS implementations. TC-GS provides plug-and-play acceleration for existing top-tier acceleration algorithms tightly coupled with rendering pipeline designs, like Gaussian compression and redundancy elimination algorithms. Additionally, we introduce a global-to-local coordinate transformation to mitigate rounding errors from quadratic terms of pixel coordinates caused by Tensor Core half-precision computation. Extensive experiments demonstrate that our method maintains rendering quality while providing an additional 2.18x speedup over existing Gaussian acceleration algorithms, thus reaching up to a total 5.6x acceleration. The code is currently available at anonymous \href{https://github.com/TensorCore3DGS/3DGSTensorCore}