 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation-Guided Parameter-Efficient LLM Unlearning
Apr 19, 2026Large Language Models (LLMs) often memorize sensitive or harmful information, necessitating effective machine unlearning techniques. While existing parameter-efficient unlearning methods have shown promise, they still struggle with the forget-retain trade-off. This can be attributed to their reliance on parameter importance metrics to identify parameters that are important exclusively for the forget set, which is fundamentally limited by the superposition phenomenon. Due to the polysemantic nature of LLM parameters, such an importance metric may struggle to disentangle parameters associated with the forget and retain sets. In this work, we propose Representation-Guided Low-rank Unlearning (REGLU), a novel approach that leverages the geometric properties of representation spaces to achieve robust and precise unlearning. First, we develop a representation-guided initialization for LoRA that identifies the optimal subspace for selective forgetting. Second, we introduce a regularization loss that constrains the outputs of the LoRA update to lie in the orthogonal complement of the retain set's representation subspace, thereby minimizing interference with the model's performance on the retain set. We evaluate REGLU on the TOFU and WMDP benchmarks across multiple models. Our results demonstrate that REGLU consistently outperforms state-of-the-art baselines, achieving superior unlearning quality while maintaining higher model utility.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025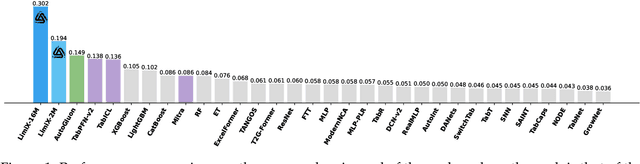
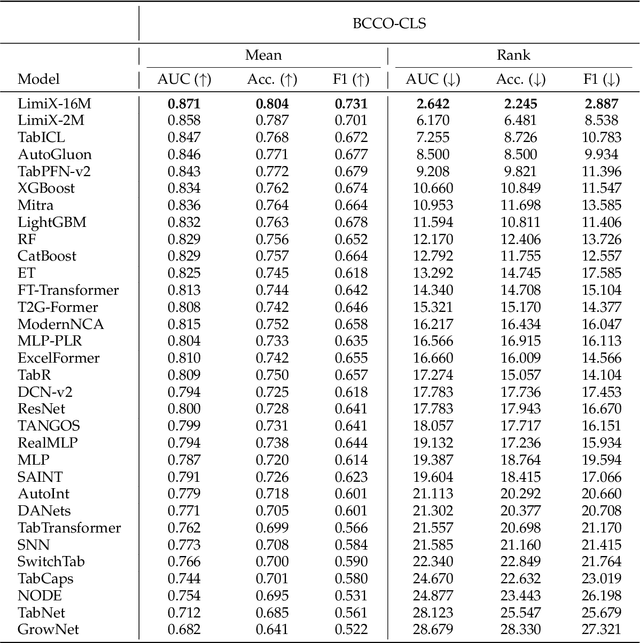
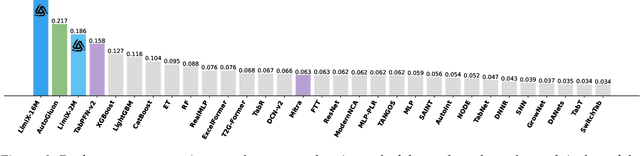
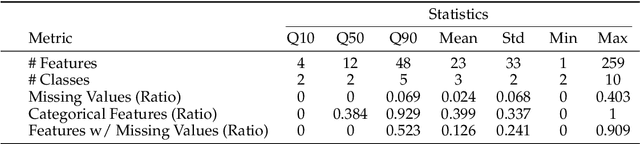
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.