 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Expectation Policy Optimization for Stable Heterogeneous Reinforcement Learning in LLMs
Aug 25, 2025As single-center computing approaches power constraints, decentralized training is becoming essential. Reinforcement Learning (RL) post-training enhances Large Language Models (LLMs) but faces challenges in heterogeneous distributed environments due to its tightly-coupled sampling-learning alternation. We propose HeteroRL, an asynchronous RL architecture that decouples rollout sampling from parameter learning, enabling robust deployment across geographically distributed nodes under network delays. We identify that latency-induced KL divergence causes importance sampling failure due to high variance. To address this, we propose Group Expectation Policy Optimization (GEPO), which reduces importance weight variance through a refined sampling mechanism. Theoretically, GEPO achieves exponential variance reduction. Experiments show it maintains superior stability over methods like GRPO, with less than 3% performance degradation under 1800-second delays, demonstrating strong potential for decentralized RL in heterogeneous networks.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021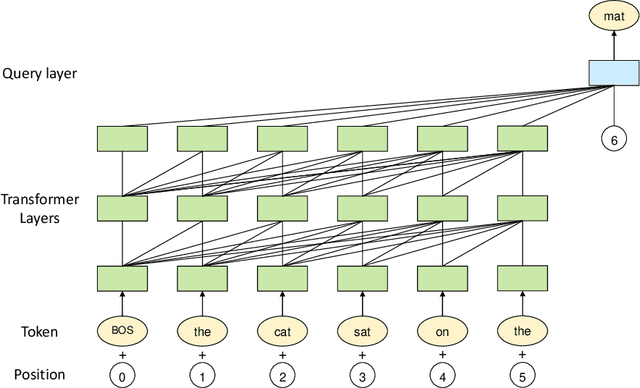
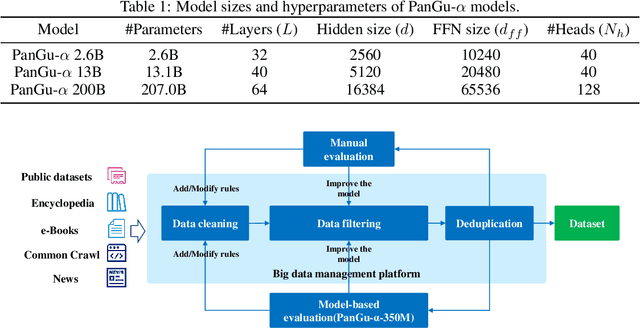
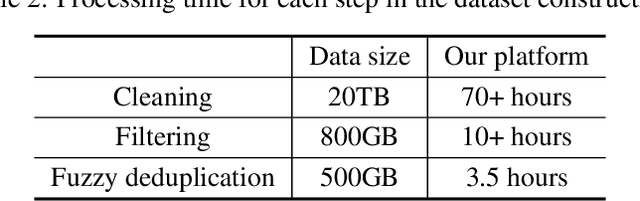
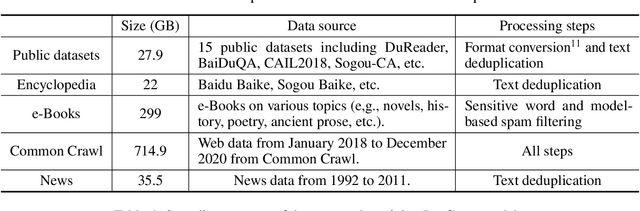
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.