 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftSignSGD(S3): An Enhanced Optimizer for Practical DNN Training and Loss Spikes Minimization Beyond Adam
Jul 09, 2025Adam has proven remarkable successful in training deep neural networks, but the mechanisms underlying its empirical successes and limitations remain underexplored. In this study, we demonstrate that the effectiveness of Adam stems largely from its similarity to SignSGD in robustly handling large gradient fluctuations, yet it is also vulnerable to destabilizing loss spikes due to its uncontrolled update scaling. To enhance the advantage of Adam and mitigate its limitation, we propose SignSoftSGD (S3), a novel optimizer with three key innovations. \emph{First}, S3 generalizes the sign-like update by employing a flexible $p$-th order momentum ($p \geq 1$) in the denominator, departing from the conventional second-order momentum (variance) preconditioning. This design enables enhanced performance while achieving stable training even with aggressive learning rates. \emph{Second}, S3 minimizes the occurrences of loss spikes through unified exponential moving average coefficients for numerator and denominator momenta, which inherently bound updates to $[-1, 1]$ and simplify hyperparameter tuning. \emph{Third}, S3 incorporates an equivalent Nesterov's accelerated gradient(NAG) module, accelerating convergence without memory overhead. Theoretically, we prove that S3 achieves the optimal convergence rate of $O\left(\frac{1}{T^{\sfrac{1}{4}}}\right)$ for general nonconvex stochastic optimization under weak assumptions. Extensive experiments across a range of vision and language tasks show that \textsf{\small S3} not only converges more rapidly and improves performance but also rarely experiences loss spikes, even with a \textbf{$\bm{10 \times}$} larger learning rate. In fact, S3 delivers performance comparable to or better than AdamW with \textbf{$2 \times$} the training steps, establishing its efficacy in both efficiency and final task performance.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021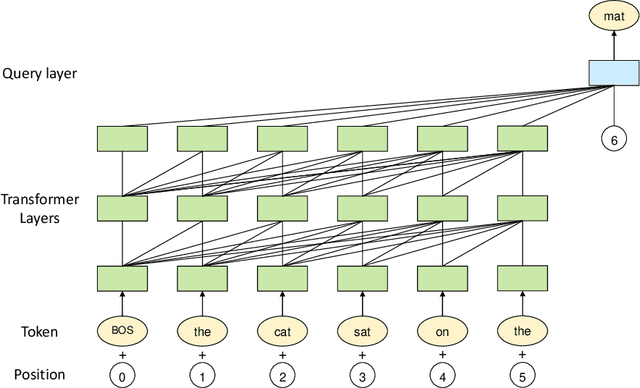
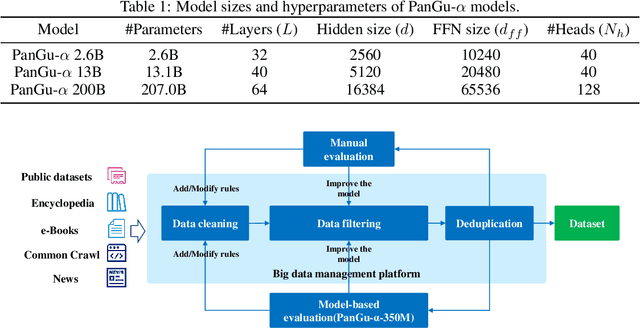
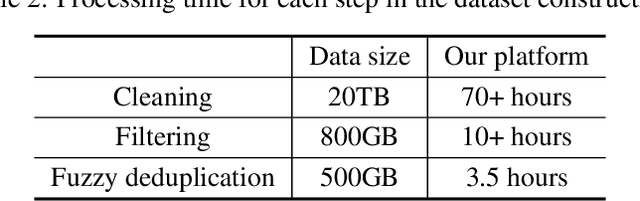
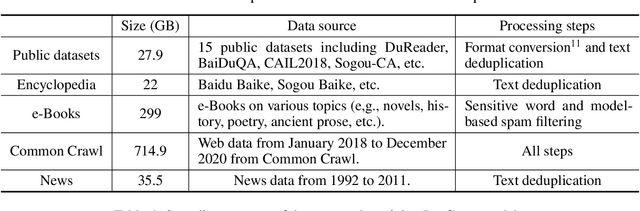
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.