 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXray-Visual Models: Scaling Vision models on Industry Scale Data
Feb 18, 2026We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
Purification Before Fusion: Toward Mask-Free Speech Enhancement for Robust Audio-Visual Speech Recognition
Jan 18, 2026Audio-visual speech recognition (AVSR) typically improves recognition accuracy in noisy environments by integrating noise-immune visual cues with audio signals. Nevertheless, high-noise audio inputs are prone to introducing adverse interference into the feature fusion process. To mitigate this, recent AVSR methods often adopt mask-based strategies to filter audio noise during feature interaction and fusion, yet such methods risk discarding semantically relevant information alongside noise. In this work, we propose an end-to-end noise-robust AVSR framework coupled with speech enhancement, eliminating the need for explicit noise mask generation. This framework leverages a Conformer-based bottleneck fusion module to implicitly refine noisy audio features with video assistance. By reducing modality redundancy and enhancing inter-modal interactions, our method preserves speech semantic integrity to achieve robust recognition performance. Experimental evaluations on the public LRS3 benchmark suggest that our method outperforms prior advanced mask-based baselines under noisy conditions.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025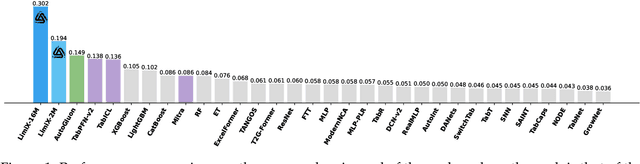
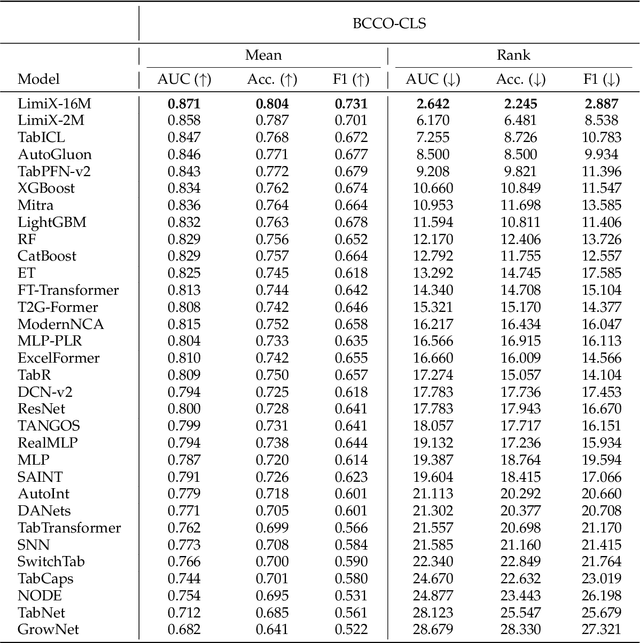
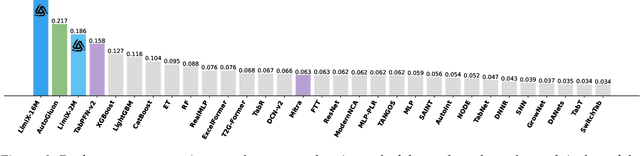
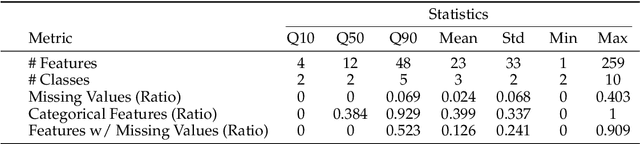
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Aug2Search: Enhancing Facebook Marketplace Search with LLM-Generated Synthetic Data Augmentation
May 21, 2025Embedding-Based Retrieval (EBR) is an important technique in modern search engines, enabling semantic match between search queries and relevant results. However, search logging data on platforms like Facebook Marketplace lacks the diversity and details needed for effective EBR model training, limiting the models' ability to capture nuanced search patterns. To address this challenge, we propose Aug2Search, an EBR-based framework leveraging synthetic data generated by Generative AI (GenAI) models, in a multimodal and multitask approach to optimize query-product relevance. This paper investigates the capabilities of GenAI, particularly Large Language Models (LLMs), in generating high-quality synthetic data, and analyzing its impact on enhancing EBR models. We conducted experiments using eight Llama models and 100 million data points from Facebook Marketplace logs. Our synthetic data generation follows three strategies: (1) generate queries, (2) enhance product listings, and (3) generate queries from enhanced listings. We train EBR models on three different datasets: sampled engagement data or original data ((e.g., "Click" and "Listing Interactions")), synthetic data, and a mixture of both engagement and synthetic data to assess their performance across various training sets. Our findings underscore the robustness of Llama models in producing synthetic queries and listings with high coherence, relevance, and diversity, while maintaining low levels of hallucination. Aug2Search achieves an improvement of up to 4% in ROC_AUC with 100 million synthetic data samples, demonstrating the effectiveness of our approach. Moreover, our experiments reveal that with the same volume of training data, models trained exclusively on synthetic data often outperform those trained on original data only or a mixture of original and synthetic data.
Cross-Organ Domain Adaptive Neural Network for Pancreatic Endoscopic Ultrasound Image Segmentation
Sep 07, 2024Accurate segmentation of lesions in pancreatic endoscopic ultrasound (EUS) images is crucial for effective diagnosis and treatment. However, the collection of enough crisp EUS images for effective diagnosis is arduous. Recently, domain adaptation (DA) has been employed to address these challenges by leveraging related knowledge from other domains. Most DA methods only focus on multi-view representations of the same organ, which makes it still tough to clearly depict the tumor lesion area with limited semantic information. Although transferring homogeneous similarity from different organs could benefit the issue, there is a lack of relevant work due to the enormous domain gap between them. To address these challenges, we propose the Cross-Organ Tumor Segmentation Networks (COTS-Nets), consisting of a universal network and an auxiliary network. The universal network utilizes boundary loss to learn common boundary information of different tumors, enabling accurate delineation of tumors in EUS despite limited and low-quality data. Simultaneously, we incorporate consistency loss in the universal network to align the prediction of pancreatic EUS with tumor boundaries from other organs to mitigate the domain gap. To further reduce the cross-organ domain gap, the auxiliary network integrates multi-scale features from different organs, aiding the universal network in acquiring domain-invariant knowledge. Systematic experiments demonstrate that COTS-Nets significantly improves the accuracy of pancreatic cancer diagnosis. Additionally, we developed the Pancreatic Cancer Endoscopic Ultrasound (PCEUS) dataset, comprising 501 pathologically confirmed pancreatic EUS images, to facilitate model development.
KwaiAgents: Generalized Information-seeking Agent System with Large Language Models
Dec 08, 2023



Driven by curiosity, humans have continually sought to explore and understand the world around them, leading to the invention of various tools to satiate this inquisitiveness. Despite not having the capacity to process and memorize vast amounts of information in their brains, humans excel in critical thinking, planning, reflection, and harnessing available tools to interact with and interpret the world, enabling them to find answers efficiently. The recent advancements in large language models (LLMs) suggest that machines might also possess the aforementioned human-like capabilities, allowing them to exhibit powerful abilities even with a constrained parameter count. In this paper, we introduce KwaiAgents, a generalized information-seeking agent system based on LLMs. Within KwaiAgents, we propose an agent system that employs LLMs as its cognitive core, which is capable of understanding a user's query, behavior guidelines, and referencing external documents. The agent can also update and retrieve information from its internal memory, plan and execute actions using a time-aware search-browse toolkit, and ultimately provide a comprehensive response. We further investigate the system's performance when powered by LLMs less advanced than GPT-4, and introduce the Meta-Agent Tuning (MAT) framework, designed to ensure even an open-sourced 7B or 13B model performs well among many agent systems. We exploit both benchmark and human evaluations to systematically validate these capabilities. Extensive experiments show the superiority of our agent system compared to other autonomous agents and highlight the enhanced generalized agent-abilities of our fine-tuned LLMs.
Comprehensive Evaluation of GNN Training Systems: A Data Management Perspective
Nov 22, 2023Many Graph Neural Network (GNN) training systems have emerged recently to support efficient GNN training. Since GNNs embody complex data dependencies between training samples, the training of GNNs should address distinct challenges different from DNN training in data management, such as data partitioning, batch preparation for mini-batch training, and data transferring between CPUs and GPUs. These factors, which take up a large proportion of training time, make data management in GNN training more significant. This paper reviews GNN training from a data management perspective and provides a comprehensive analysis and evaluation of the representative approaches. We conduct extensive experiments on various benchmark datasets and show many interesting and valuable results. We also provide some practical tips learned from these experiments, which are helpful for designing GNN training systems in the future.
NeutronOrch: Rethinking Sample-based GNN Training under CPU-GPU Heterogeneous Environments
Nov 22, 2023Graph Neural Networks (GNNs) have demonstrated outstanding performance in various applications. Existing frameworks utilize CPU-GPU heterogeneous environments to train GNN models and integrate mini-batch and sampling techniques to overcome the GPU memory limitation. In CPU-GPU heterogeneous environments, we can divide sample-based GNN training into three steps: sample, gather, and train. Existing GNN systems use different task orchestrating methods to employ each step on CPU or GPU. After extensive experiments and analysis, we find that existing task orchestrating methods fail to fully utilize the heterogeneous resources, limited by inefficient CPU processing or GPU resource contention. In this paper, we propose NeutronOrch, a system for sample-based GNN training that incorporates a layer-based task orchestrating method and ensures balanced utilization of the CPU and GPU. NeutronOrch decouples the training process by layer and pushes down the training task of the bottom layer to the CPU. This significantly reduces the computational load and memory footprint of GPU training. To avoid inefficient CPU processing, NeutronOrch only offloads the training of frequently accessed vertices to the CPU and lets GPU reuse their embeddings with bounded staleness. Furthermore, NeutronOrch provides a fine-grained pipeline design for the layer-based task orchestrating method, fully overlapping different tasks on heterogeneous resources while strictly guaranteeing bounded staleness. The experimental results show that compared with the state-of-the-art GNN systems, NeutronOrch can achieve up to 4.61x performance speedup.
A Simple Temporal Information Matching Mechanism for Entity Alignment Between Temporal Knowledge Graphs
Sep 20, 2022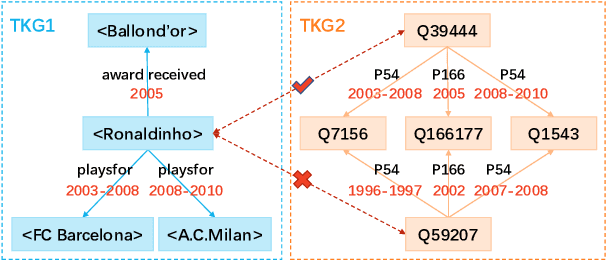

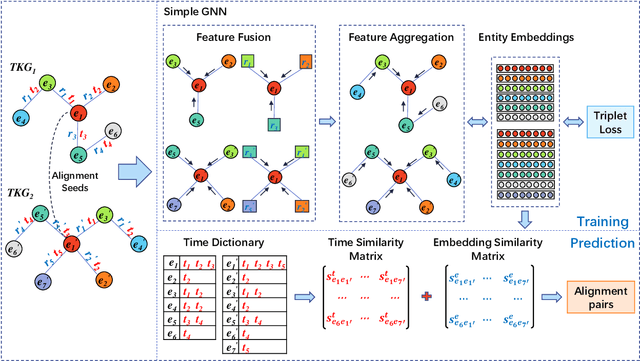
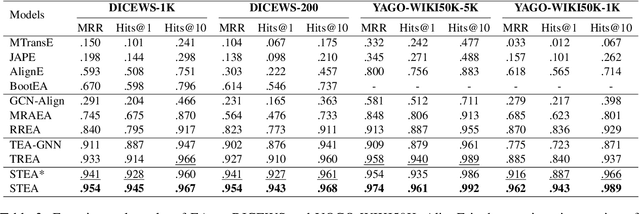
Entity alignment (EA) aims to find entities in different knowledge graphs (KGs) that refer to the same object in the real world. Recent studies incorporate temporal information to augment the representations of KGs. The existing methods for EA between temporal KGs (TKGs) utilize a time-aware attention mechanism to incorporate relational and temporal information into entity embeddings. The approaches outperform the previous methods by using temporal information. However, we believe that it is not necessary to learn the embeddings of temporal information in KGs since most TKGs have uniform temporal representations. Therefore, we propose a simple graph neural network (GNN) model combined with a temporal information matching mechanism, which achieves better performance with less time and fewer parameters. Furthermore, since alignment seeds are difficult to label in real-world applications, we also propose a method to generate unsupervised alignment seeds via the temporal information of TKG. Extensive experiments on public datasets indicate that our supervised method significantly outperforms the previous methods and the unsupervised one has competitive performance.
FlowX: Towards Explainable Graph Neural Networks via Message Flows
Jun 26, 2022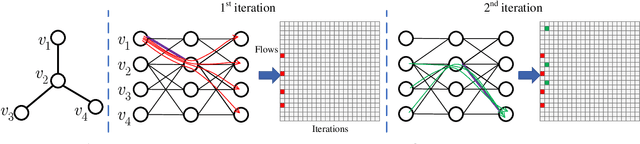
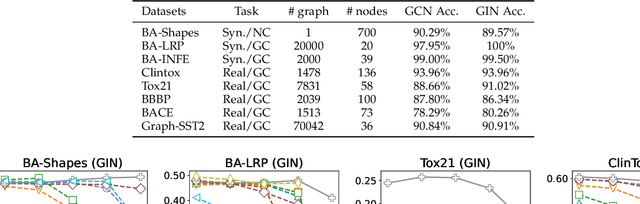
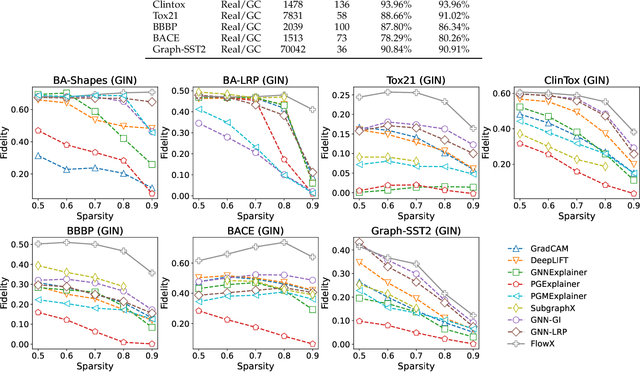
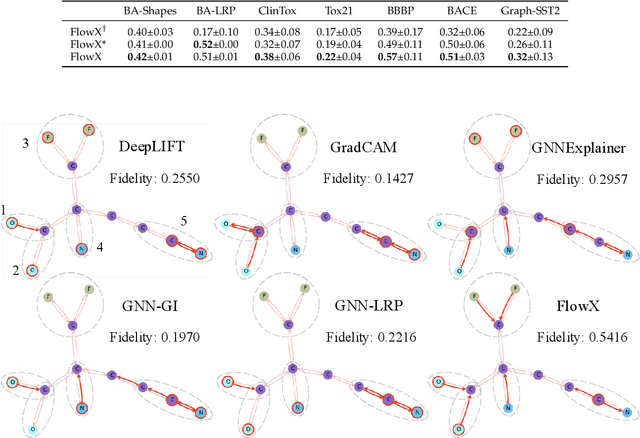
We investigate the explainability of graph neural networks (GNNs) as a step towards elucidating their working mechanisms. While most current methods focus on explaining graph nodes, edges, or features, we argue that, as the inherent functional mechanism of GNNs, message flows are more natural for performing explainability. To this end, we propose a novel method here, known as FlowX, to explain GNNs by identifying important message flows. To quantify the importance of flows, we propose to follow the philosophy of Shapley values from cooperative game theory. To tackle the complexity of computing all coalitions' marginal contributions, we propose an approximation scheme to compute Shapley-like values as initial assessments of further redistribution training. We then propose a learning algorithm to train flow scores and improve explainability. Experimental studies on both synthetic and real-world datasets demonstrate that our proposed FlowX leads to improved explainability of GNNs.