 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipation-VLA: Solving Long-Horizon Embodied Tasks via Anticipation-based Subgoal Generation
May 03, 2026Vision-Language-Action (VLA) models have emerged as a powerful paradigm for embodied intelligence, enabling robots to perform tasks based on natural language instructions and current visual input. However, existing VLA models struggle with long-horizon tasks due to compounding errors. Prior methods decompose tasks into subtasks of fixed granularity, which cannot adapt to the varying complexity of execution states, limiting their robustness in long-horizon tasks. To overcome this, we introduce Anticipation Model, which adaptively and recursively generates future subgoals. This model continuously adapts as the task unfolds, adjusting future subgoals in response to evolving dynamics, facilitating more reliable planning paths. Building on this concept, we propose Anticipation-VLA, a hierarchical VLA model that leverages the anticipation model to generate actionable subgoals that guide VLA policy execution. We implement Anticipation-VLA with finetuning a Unified Multimodal Model (UMM) for high-level subgoal generation and a goal-conditioned VLA policy for low-level action execution. Experiments in both simulated and real-world robotic tasks demonstrate the effectiveness of Anticipation-VLA, highlighting the importance of adaptive and recursive subgoal generation for robust policy execution.
PCR-CA: Parallel Codebook Representations with Contrastive Alignment for Multiple-Category App Recommendation
Aug 25, 2025Modern app store recommender systems struggle with multiple-category apps, as traditional taxonomies fail to capture overlapping semantics, leading to suboptimal personalization. We propose PCR-CA (Parallel Codebook Representations with Contrastive Alignment), an end-to-end framework for improved CTR prediction. PCR-CA first extracts compact multimodal embeddings from app text, then introduces a Parallel Codebook VQ-AE module that learns discrete semantic representations across multiple codebooks in parallel -- unlike hierarchical residual quantization (RQ-VAE). This design enables independent encoding of diverse aspects (e.g., gameplay, art style), better modeling multiple-category semantics. To bridge semantic and collaborative signals, we employ a contrastive alignment loss at both the user and item levels, enhancing representation learning for long-tail items. Additionally, a dual-attention fusion mechanism combines ID-based and semantic features to capture user interests, especially for long-tail apps. Experiments on a large-scale dataset show PCR-CA achieves a +0.76% AUC improvement over strong baselines, with +2.15% AUC gains for long-tail apps. Online A/B testing further validates our approach, showing a +10.52% lift in CTR and a +16.30% improvement in CVR, demonstrating PCR-CA's effectiveness in real-world deployment. The new framework has now been fully deployed on the Microsoft Store.
ImagineBench: Evaluating Reinforcement Learning with Large Language Model Rollouts
May 15, 2025A central challenge in reinforcement learning (RL) is its dependence on extensive real-world interaction data to learn task-specific policies. While recent work demonstrates that large language models (LLMs) can mitigate this limitation by generating synthetic experience (noted as imaginary rollouts) for mastering novel tasks, progress in this emerging field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ImagineBench, the first comprehensive benchmark for evaluating offline RL algorithms that leverage both real rollouts and LLM-imaginary rollouts. The key features of ImagineBench include: (1) datasets comprising environment-collected and LLM-imaginary rollouts; (2) diverse domains of environments covering locomotion, robotic manipulation, and navigation tasks; and (3) natural language task instructions with varying complexity levels to facilitate language-conditioned policy learning. Through systematic evaluation of state-of-the-art offline RL algorithms, we observe that simply applying existing offline RL algorithms leads to suboptimal performance on unseen tasks, achieving 35.44% success rate in hard tasks in contrast to 64.37% of method training on real rollouts for hard tasks. This result highlights the need for algorithm advancements to better leverage LLM-imaginary rollouts. Additionally, we identify key opportunities for future research: including better utilization of imaginary rollouts, fast online adaptation and continual learning, and extension to multi-modal tasks. Our code is publicly available at https://github.com/LAMDA-RL/ImagineBench.
Fine-grained Graph Learning for Multi-view Subspace Clustering
Jan 13, 2022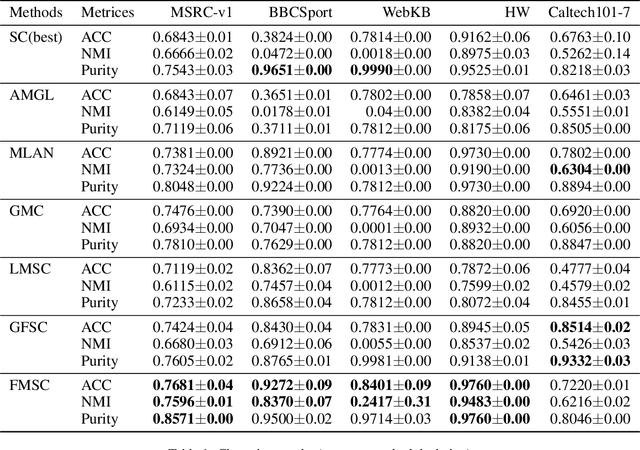
Multi-view subspace clustering has conventionally focused on integrating heterogeneous feature descriptions to capture higher-dimensional information. One popular strategy is to generate a common subspace from different views and then apply graph-based approaches to deal with clustering. However, the performance of these methods is still subject to two limitations, namely the multiple views fusion pattern and the connection between the fusion process and clustering tasks. To address these problems, we propose a novel multi-view subspace clustering framework via fine-grained graph learning, which can tell the consistency of local structures between different views and integrate all views more delicately than previous weight regularizations. Different from other models in the literature, the point-level graph regularization and the reformulation of spectral clustering are introduced to perform graphs fusion and learn the shared cluster structure together. Extensive experiments on five real-world datasets show that the proposed framework has comparable performance to the SOTA algorithms.