 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Polyp Detection and Diagnosis through Compositional Prompt-Guided Diffusion Models
Feb 25, 2025Colorectal cancer (CRC) is a significant global health concern, and early detection through screening plays a critical role in reducing mortality. While deep learning models have shown promise in improving polyp detection, classification, and segmentation, their generalization across diverse clinical environments, particularly with out-of-distribution (OOD) data, remains a challenge. Multi-center datasets like PolypGen have been developed to address these issues, but their collection is costly and time-consuming. Traditional data augmentation techniques provide limited variability, failing to capture the complexity of medical images. Diffusion models have emerged as a promising solution for generating synthetic polyp images, but the image generation process in current models mainly relies on segmentation masks as the condition, limiting their ability to capture the full clinical context. To overcome these limitations, we propose a Progressive Spectrum Diffusion Model (PSDM) that integrates diverse clinical annotations-such as segmentation masks, bounding boxes, and colonoscopy reports-by transforming them into compositional prompts. These prompts are organized into coarse and fine components, allowing the model to capture both broad spatial structures and fine details, generating clinically accurate synthetic images. By augmenting training data with PSDM-generated samples, our model significantly improves polyp detection, classification, and segmentation. For instance, on the PolypGen dataset, PSDM increases the F1 score by 2.12% and the mean average precision by 3.09%, demonstrating superior performance in OOD scenarios and enhanced generalization.
Text-to-SQL Domain Adaptation via Human-LLM Collaborative Data Annotation
Feb 21, 2025Text-to-SQL models, which parse natural language (NL) questions to executable SQL queries, are increasingly adopted in real-world applications. However, deploying such models in the real world often requires adapting them to the highly specialized database schemas used in specific applications. We find that existing text-to-SQL models experience significant performance drops when applied to new schemas, primarily due to the lack of domain-specific data for fine-tuning. This data scarcity also limits the ability to effectively evaluate model performance in new domains. Continuously obtaining high-quality text-to-SQL data for evolving schemas is prohibitively expensive in real-world scenarios. To bridge this gap, we propose SQLsynth, a human-in-the-loop text-to-SQL data annotation system. SQLsynth streamlines the creation of high-quality text-to-SQL datasets through human-LLM collaboration in a structured workflow. A within-subjects user study comparing SQLsynth with manual annotation and ChatGPT shows that SQLsynth significantly accelerates text-to-SQL data annotation, reduces cognitive load, and produces datasets that are more accurate, natural, and diverse. Our code is available at https://github.com/adobe/nl_sql_analyzer.
InfiR : Crafting Effective Small Language Models and Multimodal Small Language Models in Reasoning
Feb 17, 2025



Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have made significant advancements in reasoning capabilities. However, they still face challenges such as high computational demands and privacy concerns. This paper focuses on developing efficient Small Language Models (SLMs) and Multimodal Small Language Models (MSLMs) that retain competitive reasoning abilities. We introduce a novel training pipeline that enhances reasoning capabilities and facilitates deployment on edge devices, achieving state-of-the-art performance while minimizing development costs. \InfR~ aims to advance AI systems by improving reasoning, reducing adoption barriers, and addressing privacy concerns through smaller model sizes. Resources are available at https://github. com/Reallm-Labs/InfiR.
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025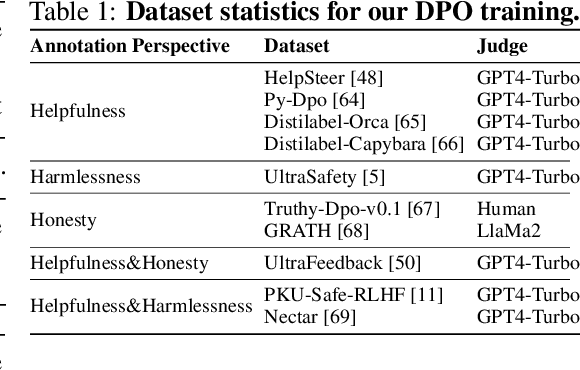
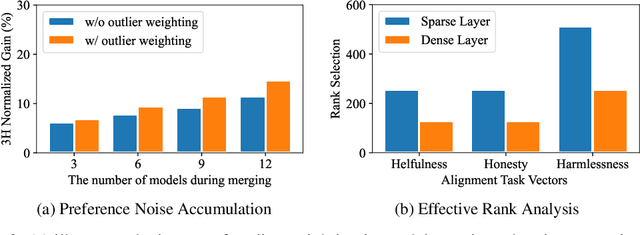
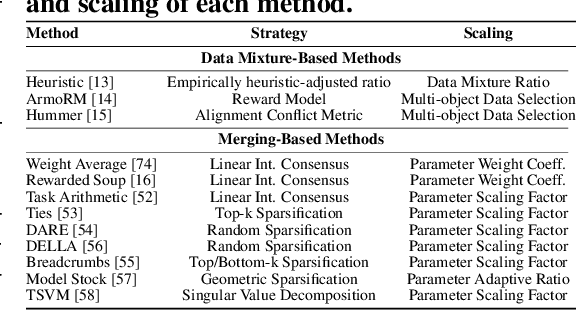
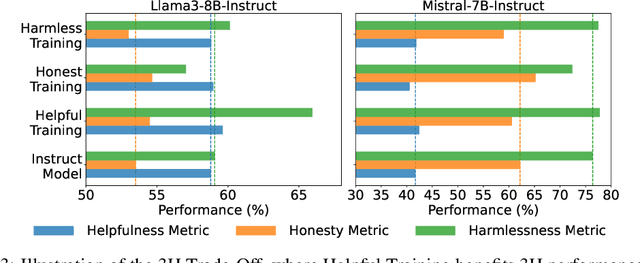
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
Knowledge is Power: Harnessing Large Language Models for Enhanced Cognitive Diagnosis
Feb 08, 2025



Cognitive Diagnosis Models (CDMs) are designed to assess students' cognitive states by analyzing their performance across a series of exercises. However, existing CDMs often struggle with diagnosing infrequent students and exercises due to a lack of rich prior knowledge. With the advancement in large language models (LLMs), which possess extensive domain knowledge, their integration into cognitive diagnosis presents a promising opportunity. Despite this potential, integrating LLMs with CDMs poses significant challenges. LLMs are not well-suited for capturing the fine-grained collaborative interactions between students and exercises, and the disparity between the semantic space of LLMs and the behavioral space of CDMs hinders effective integration. To address these issues, we propose a novel Knowledge-enhanced Cognitive Diagnosis (KCD) framework, which is a model-agnostic framework utilizing LLMs to enhance CDMs and compatible with various CDM architectures. The KCD framework operates in two stages: LLM Diagnosis and Cognitive Level Alignment. In the LLM Diagnosis stage, both students and exercises are diagnosed to achieve comprehensive and detailed modeling. In the Cognitive Level Alignment stage, we bridge the gap between the CDMs' behavioral space and the LLMs' semantic space using contrastive learning and mask-reconstruction approaches. Experiments on several real-world datasets demonstrate the effectiveness of our proposed framework.
Each Rank Could be an Expert: Single-Ranked Mixture of Experts LoRA for Multi-Task Learning
Jan 25, 2025



Low-Rank Adaptation (LoRA) is widely used for adapting large language models (LLMs) to specific domains due to its efficiency and modularity. Meanwhile, vanilla LoRA struggles with task conflicts in multi-task scenarios. Recent works adopt Mixture of Experts (MoE) by treating each LoRA module as an expert, thereby mitigating task interference through multiple specialized LoRA modules. While effective, these methods often isolate knowledge within individual tasks, failing to fully exploit the shared knowledge across related tasks. In this paper, we establish a connection between single LoRA and multi-LoRA MoE, integrating them into a unified framework. We demonstrate that the dynamic routing of multiple LoRAs is functionally equivalent to rank partitioning and block-level activation within a single LoRA. We further empirically demonstrate that finer-grained LoRA partitioning, within the same total and activated parameter constraints, leads to better performance gains across heterogeneous tasks. Building on these findings, we propose Single-ranked Mixture of Experts LoRA (\textbf{SMoRA}), which embeds MoE into LoRA by \textit{treating each rank as an independent expert}. With a \textit{dynamic rank-wise activation} mechanism, SMoRA promotes finer-grained knowledge sharing while mitigating task conflicts. Experiments demonstrate that SMoRA activates fewer parameters yet achieves better performance in multi-task scenarios.
Adaptive Rank Allocation for Federated Parameter-Efficient Fine-Tuning of Language Models
Jan 24, 2025



Pre-trained Language Models (PLMs) have demonstrated their superiority and versatility in modern Natural Language Processing (NLP), effectively adapting to various downstream tasks through further fine-tuning. Federated Parameter-Efficient Fine-Tuning (FedPEFT) has emerged as a promising solution to address privacy and efficiency challenges in distributed training for PLMs on mobile devices. However, our measurements reveal two key limitations of FedPEFT: heterogeneous data leads to significant performance degradation, and a fixed parameter configuration results in communication inefficiency. To overcome these limitations, we propose FedARA, a novel Federated Adaptive Rank Allocation for parameter-efficient fine-tuning of language models. Specifically, FedARA employs truncated singular value decomposition (SVD) adaptation to enhance flexibility and expressiveness, significantly mitigating the adverse effects of data heterogeneity. Subsequently, it utilizes dynamic rank allocation to progressively identify critical ranks, effectively improving communication efficiency. Lastly, it leverages rank-based module pruning to remove inactive modules, steadily reducing local training time and peak memory usage in each round. Extensive experiments show that FedARA consistently outperforms weak baselines by an average of 8.49\% and strong baselines by 6.95\% across various datasets under data heterogeneity while significantly improving communication efficiency by 2.40\(\times\). Moreover, experiments on AGX Orin, Orin Nano and Raspberry Pi 5 devices demonstrate substantial decreases in total training time and energy consumption by up to 48.90\% and 46.95\%, respectively.
Cascaded Self-Evaluation Augmented Training for Efficient Multimodal Large Language Models
Jan 10, 2025



Efficient Multimodal Large Language Models (EMLLMs) have rapidly advanced recently. Incorporating Chain-of-Thought (CoT) reasoning and step-by-step self-evaluation has improved their performance. However, limited parameters often hinder EMLLMs from effectively using self-evaluation during inference. Key challenges include synthesizing evaluation data, determining its quantity, optimizing training and inference strategies, and selecting appropriate prompts. To address these issues, we introduce Self-Evaluation Augmented Training (SEAT). SEAT uses more powerful EMLLMs for CoT reasoning, data selection, and evaluation generation, then trains EMLLMs with the synthesized data. However, handling long prompts and maintaining CoT reasoning quality are problematic. Therefore, we propose Cascaded Self-Evaluation Augmented Training (Cas-SEAT), which breaks down lengthy prompts into shorter, task-specific cascaded prompts and reduces costs for resource-limited settings. During data synthesis, we employ open-source 7B-parameter EMLLMs and annotate a small dataset with short prompts. Experiments demonstrate that Cas-SEAT significantly boosts EMLLMs' self-evaluation abilities, improving performance by 19.68%, 55.57%, and 46.79% on the MathVista, Math-V, and We-Math datasets, respectively. Additionally, our Cas-SEAT Dataset serves as a valuable resource for future research in enhancing EMLLM self-evaluation.
Collaboration of Large Language Models and Small Recommendation Models for Device-Cloud Recommendation
Jan 10, 2025Large Language Models (LLMs) for Recommendation (LLM4Rec) is a promising research direction that has demonstrated exceptional performance in this field. However, its inability to capture real-time user preferences greatly limits the practical application of LLM4Rec because (i) LLMs are costly to train and infer frequently, and (ii) LLMs struggle to access real-time data (its large number of parameters poses an obstacle to deployment on devices). Fortunately, small recommendation models (SRMs) can effectively supplement these shortcomings of LLM4Rec diagrams by consuming minimal resources for frequent training and inference, and by conveniently accessing real-time data on devices. In light of this, we designed the Device-Cloud LLM-SRM Collaborative Recommendation Framework (LSC4Rec) under a device-cloud collaboration setting. LSC4Rec aims to integrate the advantages of both LLMs and SRMs, as well as the benefits of cloud and edge computing, achieving a complementary synergy. We enhance the practicability of LSC4Rec by designing three strategies: collaborative training, collaborative inference, and intelligent request. During training, LLM generates candidate lists to enhance the ranking ability of SRM in collaborative scenarios and enables SRM to update adaptively to capture real-time user interests. During inference, LLM and SRM are deployed on the cloud and on the device, respectively. LLM generates candidate lists and initial ranking results based on user behavior, and SRM get reranking results based on the candidate list, with final results integrating both LLM's and SRM's scores. The device determines whether a new candidate list is needed by comparing the consistency of the LLM's and SRM's sorted lists. Our comprehensive and extensive experimental analysis validates the effectiveness of each strategy in LSC4Rec.
Optimize Incompatible Parameters through Compatibility-aware Knowledge Integration
Jan 10, 2025



Deep neural networks have become foundational to advancements in multiple domains, including recommendation systems, natural language processing, and so on. Despite their successes, these models often contain incompatible parameters that can be underutilized or detrimental to model performance, particularly when faced with specific, varying data distributions. Existing research excels in removing such parameters or merging the outputs of multiple different pretrained models. However, the former focuses on efficiency rather than performance, while the latter requires several times more computing and storage resources to support inference. In this paper, we set the goal to explicitly improve these incompatible parameters by leveraging the complementary strengths of different models, thereby directly enhancing the models without any additional parameters. Specifically, we propose Compatibility-aware Knowledge Integration (CKI), which consists of Parameter Compatibility Assessment and Parameter Splicing, which are used to evaluate the knowledge content of multiple models and integrate the knowledge into one model, respectively. The integrated model can be used directly for inference or for further fine-tuning. We conduct extensive experiments on various datasets for recommendation and language tasks, and the results show that Compatibility-aware Knowledge Integration can effectively optimize incompatible parameters under multiple tasks and settings to break through the training limit of the original model without increasing the inference cost.