 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDrive: A Unified Vision-Language and Grounding Framework for Interpretable Risk Understanding in Autonomous Driving
Jun 23, 2026Recent multimodal large language models (MLLMs) have shown strong potential for autonomous driving scene understanding, yet existing methods still face a fundamental trade-off between temporal reasoning and spatial precision. Models that rely on single-frame or low-resolution inputs often miss small, distant, or partially occluded hazards, while language-centric driving models frequently provide limited grounded evidence for their explanations. To address this gap, we propose UniDrive, a unified visual-language and grounding framework for interpretable risk understanding in autonomous driving. UniDrive combines a temporal reasoning branch that models scene dynamics from multi-frame visual input with a high-resolution perception branch that preserves fine-grained spatial details from the latest frame. The two branches are integrated through a gated cross-attention fusion module, enabling dynamic context to be aligned with precise spatial evidence. Based on the fused representation, UniDrive jointly generates natural-language risk descriptions and grounded bounding-box outputs for risk objects. Experiments on the DRAMA-Reasoning benchmark show that UniDrive outperforms representative image-based and video-based baselines in both captioning and risk-object grounding. In particular, UniDrive achieves the best overall performance on the validation split and demonstrates clear advantages in small-object localization, zero-shot generalization to NuScenes and BDD100K, and human-rated interpretability and trustworthiness. These results suggest that explicitly combining temporal semantics and high-resolution perception provides a stronger foundation for interpretable and safety-oriented autonomous driving systems. The code is available at https://github.com/pixeli99/unidrive-dev.
ReflectDrive-2: Reinforcement-Learning-Aligned Self-Editing for Discrete Diffusion Driving
May 06, 2026We introduce ReflectDrive-2, a masked discrete diffusion planner with separate action expert for autonomous driving that represents plans as discrete trajectory tokens and generates them through parallel masked decoding. This discrete token space enables in-place trajectory revision: AutoEdit rewrites selected tokens using the same model, without requiring an auxiliary refinement network. To train this capability, we use a two-stage procedure. First, we construct structure-aware perturbations of expert trajectories along longitudinal progress and lateral heading directions and supervise the model to recover the original expert trajectory. We then fine-tune the full decision--draft--reflect rollout with reinforcement learning (RL), assigning terminal driving reward to the final post-edit trajectory and propagating policy-gradient credit through full-rollout transitions. Full-rollout RL proves crucial for coupling drafting and editing: under supervised training alone, inference-time AutoEdit improves PDMS by at most $0.3$, whereas RL increases its gain to $1.9$. We also co-design an efficient reflective decoding stack for the decision--draft--reflect pipeline, combining shared-prefix KV reuse, Alternating Step Decode, and fused on-device unmasking. On NAVSIM, ReflectDrive-2 achieves $91.0$ PDMS with camera-only input and $94.8$ PDMS in a best-of-6 oracle setting, while running at $31.8$ ms average latency on NVIDIA Thor.
Beyond Scattered Acceptance: Fast and Coherent Inference for DLMs via Longest Stable Prefixes
Mar 05, 2026Diffusion Language Models (DLMs) promise highly parallel text generation, yet their practical inference speed is often bottlenecked by suboptimal decoding schedulers. Standard approaches rely on 'scattered acceptance'-committing high confidence tokens at disjoint positions throughout the sequence. This approach inadvertently fractures the Key-Value (KV) cache, destroys memory locality, and forces the model into costly, repeated repairs across unstable token boundaries. To resolve this, we present the Longest Stable Prefix (LSP) scheduler, a training-free and model-agnostic inference paradigm based on monolithic prefix absorption. In each denoising step, LSP evaluates token stability via a single forward pass, dynamically identifies a contiguous left-aligned block of stable predictions, and snaps its boundary to natural linguistic or structural delimiters before an atomic commitment. This prefix-first topology yields dual benefits: systemically, it converts fragmented KV cache updates into efficient, contiguous appends; algorithmically, it preserves bidirectional lookahead over a geometrically shrinking active suffix, drastically reducing token flip rates and denoiser calls. Extensive evaluations on LLaDA-8B and Dream-7B demonstrate that LSP accelerates inference by up to 3.4x across rigorous benchmarks including mathematical reasoning, code generation, multilingual (CJK) tasks, and creative writing while matching or slightly improving output quality. By fundamentally restructuring the commitment topology, LSP bridges the gap between the theoretical parallelism of DLMs and practical hardware efficiency.
Why Diffusion Language Models Struggle with Truly Parallel (Non-Autoregressive) Decoding?
Feb 26, 2026Diffusion Language Models (DLMs) are often advertised as enabling parallel token generation, yet practical fast DLMs frequently converge to left-to-right, autoregressive (AR)-like decoding dynamics. In contrast, genuinely non-AR generation is promising because it removes AR's sequential bottleneck, better exploiting parallel hardware to reduce synchronization/communication overhead and improve latency scaling with output length. We argue that a primary driver of AR-like decoding is a mismatch between DLM objectives and the highly sequential structure of widely used training data, including standard pretraining corpora and long chain-of-thought (CoT) supervision. Motivated by this diagnosis, we propose NAP (Non-Autoregressive Parallel DLMs), a proof-of-concept, data-centric approach that better aligns supervision with non-AR parallel decoding. NAP curates examples as multiple independent reasoning trajectories and couples them with a parallel-forced decoding strategy that encourages multi-token parallel updates. Across math reasoning benchmarks, NAP yields stronger performance under parallel decoding than DLMs trained on standard long CoT data, with gains growing as parallelism increases. Our results suggest that revisiting data and supervision is a principled direction for mitigating AR-like behavior and moving toward genuinely non-autoregressive parallel generation in DLMs. Our code is available at https://github.com/pixeli99/NAP.
Modality Alignment across Trees on Heterogeneous Hyperbolic Manifolds
Oct 31, 2025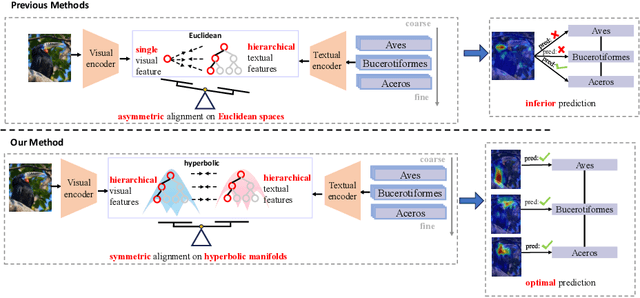
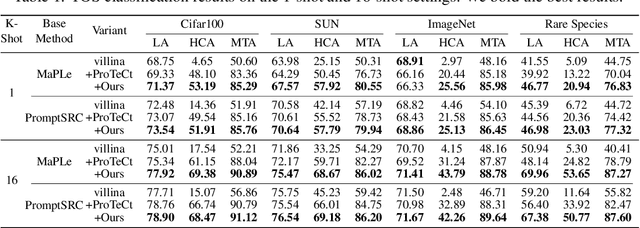
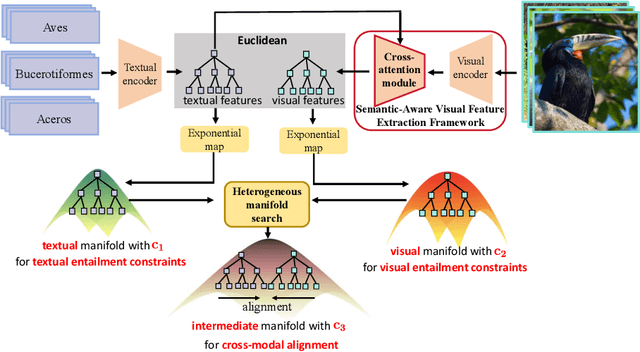

Modality alignment is critical for vision-language models (VLMs) to effectively integrate information across modalities. However, existing methods extract hierarchical features from text while representing each image with a single feature, leading to asymmetric and suboptimal alignment. To address this, we propose Alignment across Trees, a method that constructs and aligns tree-like hierarchical features for both image and text modalities. Specifically, we introduce a semantic-aware visual feature extraction framework that applies a cross-attention mechanism to visual class tokens from intermediate Transformer layers, guided by textual cues to extract visual features with coarse-to-fine semantics. We then embed the feature trees of the two modalities into hyperbolic manifolds with distinct curvatures to effectively model their hierarchical structures. To align across the heterogeneous hyperbolic manifolds with different curvatures, we formulate a KL distance measure between distributions on heterogeneous manifolds, and learn an intermediate manifold for manifold alignment by minimizing the distance. We prove the existence and uniqueness of the optimal intermediate manifold. Experiments on taxonomic open-set classification tasks across multiple image datasets demonstrate that our method consistently outperforms strong baselines under few-shot and cross-domain settings.
Diffusion Language Models Know the Answer Before Decoding
Aug 27, 2025



Diffusion language models (DLMs) have recently emerged as an alternative to autoregressive approaches, offering parallel sequence generation and flexible token orders. However, their inference remains slower than that of autoregressive models, primarily due to the cost of bidirectional attention and the large number of refinement steps required for high quality outputs. In this work, we highlight and leverage an overlooked property of DLMs early answer convergence: in many cases, the correct answer can be internally identified by half steps before the final decoding step, both under semi-autoregressive and random remasking schedules. For example, on GSM8K and MMLU, up to 97% and 99% of instances, respectively, can be decoded correctly using only half of the refinement steps. Building on this observation, we introduce Prophet, a training-free fast decoding paradigm that enables early commit decoding. Specifically, Prophet dynamically decides whether to continue refinement or to go "all-in" (i.e., decode all remaining tokens in one step), using the confidence gap between the top-2 prediction candidates as the criterion. It integrates seamlessly into existing DLM implementations, incurs negligible overhead, and requires no additional training. Empirical evaluations of LLaDA-8B and Dream-7B across multiple tasks show that Prophet reduces the number of decoding steps by up to 3.4x while preserving high generation quality. These results recast DLM decoding as a problem of when to stop sampling, and demonstrate that early decode convergence provides a simple yet powerful mechanism for accelerating DLM inference, complementary to existing speedup techniques. Our code is publicly available at https://github.com/pixeli99/Prophet.
DriveAgent-R1: Advancing VLM-based Autonomous Driving with Hybrid Thinking and Active Perception
Jul 28, 2025Vision-Language Models (VLMs) are advancing autonomous driving, yet their potential is constrained by myopic decision-making and passive perception, limiting reliability in complex environments. We introduce DriveAgent-R1 to tackle these challenges in long-horizon, high-level behavioral decision-making. DriveAgent-R1 features two core innovations: a Hybrid-Thinking framework that adaptively switches between efficient text-based and in-depth tool-based reasoning, and an Active Perception mechanism with a vision toolkit to proactively resolve uncertainties, thereby balancing decision-making efficiency and reliability. The agent is trained using a novel, three-stage progressive reinforcement learning strategy designed to master these hybrid capabilities. Extensive experiments demonstrate that DriveAgent-R1 achieves state-of-the-art performance, outperforming even leading proprietary large multimodal models, such as Claude Sonnet 4. Ablation studies validate our approach and confirm that the agent's decisions are robustly grounded in actively perceived visual evidence, paving a path toward safer and more intelligent autonomous systems.
From Objects to Anywhere: A Holistic Benchmark for Multi-level Visual Grounding in 3D Scenes
Jun 05, 2025



3D visual grounding has made notable progress in localizing objects within complex 3D scenes. However, grounding referring expressions beyond objects in 3D scenes remains unexplored. In this paper, we introduce Anywhere3D-Bench, a holistic 3D visual grounding benchmark consisting of 2,632 referring expression-3D bounding box pairs spanning four different grounding levels: human-activity areas, unoccupied space beyond objects, objects in the scene, and fine-grained object parts. We assess a range of state-of-the-art 3D visual grounding methods alongside large language models (LLMs) and multimodal LLMs (MLLMs) on Anywhere3D-Bench. Experimental results reveal that space-level and part-level visual grounding pose the greatest challenges: space-level tasks require a more comprehensive spatial reasoning ability, for example, modeling distances and spatial relations within 3D space, while part-level tasks demand fine-grained perception of object composition. Even the best performance model, OpenAI o4-mini, achieves only 23.57% accuracy on space-level tasks and 33.94% on part-level tasks, significantly lower than its performance on area-level and object-level tasks. These findings underscore a critical gap in current models' capacity to understand and reason about 3D scene beyond object-level semantics.
Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking
May 26, 2025Classifier-Free Guidance (CFG) significantly enhances controllability in generative models by interpolating conditional and unconditional predictions. However, standard CFG often employs a static unconditional input, which can be suboptimal for iterative generation processes where model uncertainty varies dynamically. We introduce Adaptive Classifier-Free Guidance (A-CFG), a novel method that tailors the unconditional input by leveraging the model's instantaneous predictive confidence. At each step of an iterative (masked) diffusion language model, A-CFG identifies tokens in the currently generated sequence for which the model exhibits low confidence. These tokens are temporarily re-masked to create a dynamic, localized unconditional input. This focuses CFG's corrective influence precisely on areas of ambiguity, leading to more effective guidance. We integrate A-CFG into a state-of-the-art masked diffusion language model and demonstrate its efficacy. Experiments on diverse language generation benchmarks show that A-CFG yields substantial improvements over standard CFG, achieving, for instance, a 3.9 point gain on GPQA. Our work highlights the benefit of dynamically adapting guidance mechanisms to model uncertainty in iterative generation.
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL
May 21, 2025



Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.