 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonOps: Operator Segmentation for LLM Reasoning Traces
May 28, 2026Chain-of-thought traces from large reasoning models can span tens of thousands of tokens, yet we lack a vocabulary for describing their internal structure. Previous methods developed to analyze chain-of-thought traces are either too rigid or not expressive enough, failing to capture features across domains and models. To remedy this, we develop ReasonOps, an unsupervised, expressive method for annotating chain-of-thought traces, providing succinct universal operators. Using ReasonOps, we analyze 44,662 traces from 12 thinking LLMs spanning 6 families across 8 reasoning benchmarks and discover that they share a common compositional structure: 7 recurring reasoning operators -- discourse-level moves such as backtracking, inferring, and hypothesizing -- that emerge from unsupervised clustering of sentence-initial 3-token pivots. These operators appear across every model family and benchmark domain, confirmed by three independent LLM judges who classify held-out samples at 70 -76% accuracy. We analyze the structure of operators on easy vs. hard problems, revealing that reflective operators are more helpful on hard problems and harm performance on easy problems. Operator sequences are highly model-identifying: a classifier trained on operator distributions alone recovers the source model with macro-AUC, revealing that each model family has a distinctive reasoning fingerprint. Structural operator features predict within-problem answer correctness well above baselines. Classifiers built on these operators reach WP-AUC and on AIME specifically. ReasonOps further enables early quality estimation well before the trace completes: we predict at WP-AUC for only 50% of the trace. The ReasonOps pipeline is unsupervised and annotation-free, enabling deep insights into LLM reasoning traces as well as strong downstream results on model identification and correctness prediction.
From Measurement to Mitigation: Quantifying and Reducing Identity Leakage in Image Representation Encoders with Linear Subspace Removal
Apr 07, 2026Frozen visual embeddings (e.g., CLIP, DINOv2/v3, SSCD) power retrieval and integrity systems, yet their use on face-containing data is constrained by unmeasured identity leakage and a lack of deployable mitigations. We take an attacker-aware view and contribute: (i) a benchmark of visual embeddings that reports open-set verification at low false-accept rates, a calibrated diffusion-based template inversion check, and face-context attribution with equal-area perturbations; and (ii) propose a one-shot linear projector that removes an estimated identity subspace while preserving the complementary space needed for utility, which for brevity we denote as the identity sanitization projection ISP. Across CelebA-20 and VGGFace2, we show that these encoders are robust under open-set linear probes, with CLIP exhibiting relatively higher leakage than DINOv2/v3 and SSCD, robust to template inversion, and are context-dominant. In addition, we show that ISP drives linear access to near-chance while retaining high non-biometric utility, and transfers across datasets with minor degradation. Our results establish the first attacker-calibrated facial privacy audit of non-FR encoders and demonstrate that linear subspace removal achieves strong privacy guarantees while preserving utility for visual search and retrieval.
Back to Basics: Revisiting ASR in the Age of Voice Agents
Mar 26, 2026Automatic speech recognition (ASR) systems have achieved near-human accuracy on curated benchmarks, yet still fail in real-world voice agents under conditions that current evaluations do not systematically cover. Without diagnostic tools that isolate specific failure factors, practitioners cannot anticipate which conditions, in which languages, will cause what degree of degradation. We introduce WildASR, a multilingual (four-language) diagnostic benchmark sourced entirely from real human speech that factorizes ASR robustness along three axes: environmental degradation, demographic shift, and linguistic diversity. Evaluating seven widely used ASR systems, we find severe and uneven performance degradation, and model robustness does not transfer across languages or conditions. Critically, models often hallucinate plausible but unspoken content under partial or degraded inputs, creating concrete safety risks for downstream agent behavior. Our results demonstrate that targeted, factor-isolated evaluation is essential for understanding and improving ASR reliability in production systems. Besides the benchmark itself, we also present three analytical tools that practitioners can use to guide deployment decisions.
Learning to Repair Lean Proofs from Compiler Feedback
Feb 03, 2026As neural theorem provers become increasingly agentic, the ability to interpret and act on compiler feedback is critical. However, existing Lean datasets consist almost exclusively of correct proofs, offering little supervision for understanding and repairing failures. We study Lean proof repair as a supervised learning problem: given an erroneous proof and compiler feedback, predict both a corrected proof and a natural-language diagnosis grounded in the same feedback. We introduce APRIL (Automated Proof Repair in Lean), a dataset of 260,000 supervised tuples pairing systematically generated proof failures with compiler diagnostics and aligned repair and explanation targets. Training language models on APRIL substantially improves repair accuracy and feedback-conditioned reasoning; in our single-shot repair evaluation setting, a finetuned 4B-parameter model outperforms the strongest open-source baseline. We view diagnostic-conditioned supervision as a complementary training signal for feedback-using provers. Our dataset is available at \href{https://huggingface.co/datasets/uw-math-ai/APRIL}{this link}.
SweRank+: Multilingual, Multi-Turn Code Ranking for Software Issue Localization
Dec 23, 2025Maintaining large-scale, multilingual codebases hinges on accurately localizing issues, which requires mapping natural-language error descriptions to the relevant functions that need to be modified. However, existing ranking approaches are often Python-centric and perform a single-pass search over the codebase. This work introduces SweRank+, a framework that couples SweRankMulti, a cross-lingual code ranking tool, with SweRankAgent, an agentic search setup, for iterative, multi-turn reasoning over the code repository. SweRankMulti comprises a code embedding retriever and a listwise LLM reranker, and is trained using a carefully curated large-scale issue localization dataset spanning multiple popular programming languages. SweRankAgent adopts an agentic search loop that moves beyond single-shot localization with a memory buffer to reason and accumulate relevant localization candidates over multiple turns. Our experiments on issue localization benchmarks spanning various languages demonstrate new state-of-the-art performance with SweRankMulti, while SweRankAgent further improves localization over single-pass ranking.
One-Topic-Doesn't-Fit-All: Transcreating Reading Comprehension Test for Personalized Learning
Nov 12, 2025


Personalized learning has gained attention in English as a Foreign Language (EFL) education, where engagement and motivation play crucial roles in reading comprehension. We propose a novel approach to generating personalized English reading comprehension tests tailored to students' interests. We develop a structured content transcreation pipeline using OpenAI's gpt-4o, where we start with the RACE-C dataset, and generate new passages and multiple-choice reading comprehension questions that are linguistically similar to the original passages but semantically aligned with individual learners' interests. Our methodology integrates topic extraction, question classification based on Bloom's taxonomy, linguistic feature analysis, and content transcreation to enhance student engagement. We conduct a controlled experiment with EFL learners in South Korea to examine the impact of interest-aligned reading materials on comprehension and motivation. Our results show students learning with personalized reading passages demonstrate improved comprehension and motivation retention compared to those learning with non-personalized materials.
Estimating Dimensionality of Neural Representations from Finite Samples
Sep 30, 2025



The global dimensionality of a neural representation manifold provides rich insight into the computational process underlying both artificial and biological neural networks. However, all existing measures of global dimensionality are sensitive to the number of samples, i.e., the number of rows and columns of the sample matrix. We show that, in particular, the participation ratio of eigenvalues, a popular measure of global dimensionality, is highly biased with small sample sizes, and propose a bias-corrected estimator that is more accurate with finite samples and with noise. On synthetic data examples, we demonstrate that our estimator can recover the true known dimensionality. We apply our estimator to neural brain recordings, including calcium imaging, electrophysiological recordings, and fMRI data, and to the neural activations in a large language model and show our estimator is invariant to the sample size. Finally, our estimators can additionally be used to measure the local dimensionalities of curved neural manifolds by weighting the finite samples appropriately.
ThematicPlane: Bridging Tacit User Intent and Latent Spaces for Image Generation
Aug 08, 2025
Generative AI has made image creation more accessible, yet aligning outputs with nuanced creative intent remains challenging, particularly for non-experts. Existing tools often require users to externalize ideas through prompts or references, limiting fluid exploration. We introduce ThematicPlane, a system that enables users to navigate and manipulate high-level semantic concepts (e.g., mood, style, or narrative tone) within an interactive thematic design plane. This interface bridges the gap between tacit creative intent and system control. In our exploratory study (N=6), participants engaged in divergent and convergent creative modes, often embracing unexpected results as inspiration or iteration cues. While they grounded their exploration in familiar themes, differing expectations of how themes mapped to outputs revealed a need for more explainable controls. Overall, ThematicPlane fosters expressive, iterative workflows and highlights new directions for intuitive, semantics-driven interaction in generative design tools.
PosterMate: Audience-driven Collaborative Persona Agents for Poster Design
Jul 24, 2025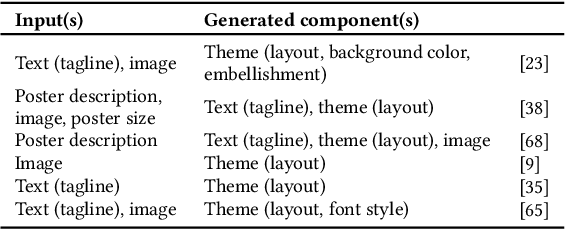
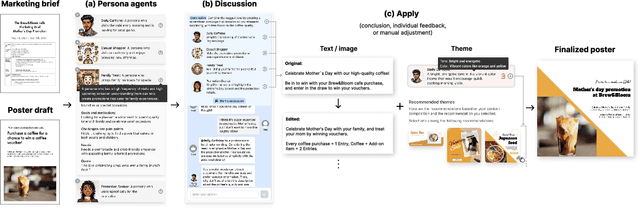
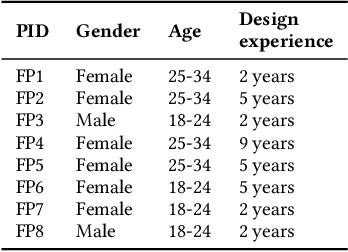
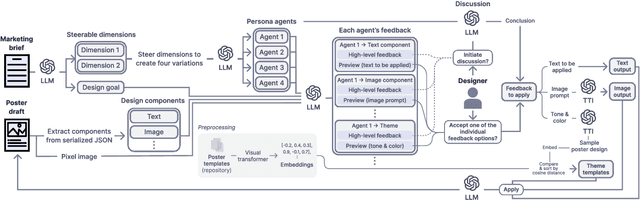
Poster designing can benefit from synchronous feedback from target audiences. However, gathering audiences with diverse perspectives and reconciling them on design edits can be challenging. Recent generative AI models present opportunities to simulate human-like interactions, but it is unclear how they may be used for feedback processes in design. We introduce PosterMate, a poster design assistant that facilitates collaboration by creating audience-driven persona agents constructed from marketing documents. PosterMate gathers feedback from each persona agent regarding poster components, and stimulates discussion with the help of a moderator to reach a conclusion. These agreed-upon edits can then be directly integrated into the poster design. Through our user study (N=12), we identified the potential of PosterMate to capture overlooked viewpoints, while serving as an effective prototyping tool. Additionally, our controlled online evaluation (N=100) revealed that the feedback from an individual persona agent is appropriate given its persona identity, and the discussion effectively synthesizes the different persona agents' perspectives.
Team ACK at SemEval-2025 Task 2: Beyond Word-for-Word Machine Translation for English-Korean Pairs
Apr 29, 2025Translating knowledge-intensive and entity-rich text between English and Korean requires transcreation to preserve language-specific and cultural nuances beyond literal, phonetic or word-for-word conversion. We evaluate 13 models (LLMs and MT models) using automatic metrics and human assessment by bilingual annotators. Our findings show LLMs outperform traditional MT systems but struggle with entity translation requiring cultural adaptation. By constructing an error taxonomy, we identify incorrect responses and entity name errors as key issues, with performance varying by entity type and popularity level. This work exposes gaps in automatic evaluation metrics and hope to enable future work in completing culturally-nuanced machine translation.