 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedCUA-Bench: A Screenshot-Only Benchmark for Clinical Computer-Use Agents
Jun 02, 2026Computer-use agents could automate repetitive screen-based clinical work, but their reliability in medical graphical user interfaces remains largely unvalidated. Existing benchmarks focus on general web or desktop tasks and underrepresent medical software, which requires domain knowledge, exhibits markedly different UI design from mainstream applications, lacks public testing environments, and demands safety validation beyond task completion. We introduce MedCUA-Bench, an interactive benchmark for clinical computer-use agents. It covers 18 clinical scenarios across 10 medical domains, reconstructed from real product manuals and open-source medical systems to capture authentic clinical interfaces while avoiding licensing and privacy constraints. Each task ships with paired intent- and step-level goals to disentangle clinical reasoning from UI execution, and is evaluated by a deterministic checker over task completion and five clinical safety dimensions. Across 23 agents, the best closed-source model reaches 54.2% strict success, while all models remain below 9% on the real OpenEMR. Open-source agents average only 2.5%, with the best reaching 16.2%. MedCUA-Bench exposes the gap between current agents and reliable clinical software use, providing a reproducible testbed for future research.
Agent-Driven Corpus Linguistics: A Framework for Autonomous Linguistic Discovery
Apr 08, 2026Corpus linguistics has traditionally relied on human researchers to formulate hypotheses, construct queries, and interpret results - a process demanding specialized technical skills and considerable time. We propose Agent-Driven Corpus Linguistics, an approach in which a large language model (LLM), connected to a corpus query engine via a structured tool-use interface, takes over the investigative cycle: generating hypotheses, querying the corpus, interpreting results, and refining analysis across multiple rounds. The human researcher sets direction and evaluates final output. Unlike unconstrained LLM generation, every finding is anchored in verifiable corpus evidence. We treat this not as a replacement for the corpus-based/corpus-driven distinction but as a complementary dimension: it concerns who conducts the inquiry, not the epistemological relationship between theory and data. We demonstrate the framework by linking an LLM agent to a CQP-indexed Gutenberg corpus (5 million tokens) via the Model Context Protocol (MCP). Given only "investigate English intensifiers," the agent identified a diachronic relay chain (so+ADJ > very > really), three pathways of semantic change (delexicalization, polarity fixation, metaphorical constraint), and register-sensitive distributions. A controlled baseline experiment shows that corpus grounding contributes quantification and falsifiability that the model cannot produce from training data alone. To test external validity, the agent replicated two published studies on the CLMET corpus (40 million tokens) - Claridge (2025) and De Smet (2013) - with close quantitative agreement. Agent-driven corpus research can thus produce empirically grounded findings at machine speed, lowering the technical barrier for a broader range of researchers.
One-shot synthesis of rare gastrointestinal lesions improves diagnostic accuracy and clinical training
Dec 30, 2025Rare gastrointestinal lesions are infrequently encountered in routine endoscopy, restricting the data available for developing reliable artificial intelligence (AI) models and training novice clinicians. Here we present EndoRare, a one-shot, retraining-free generative framework that synthesizes diverse, high-fidelity lesion exemplars from a single reference image. By leveraging language-guided concept disentanglement, EndoRare separates pathognomonic lesion features from non-diagnostic attributes, encoding the former into a learnable prototype embedding while varying the latter to ensure diversity. We validated the framework across four rare pathologies (calcifying fibrous tumor, juvenile polyposis syndrome, familial adenomatous polyposis, and Peutz-Jeghers syndrome). Synthetic images were judged clinically plausible by experts and, when used for data augmentation, significantly enhanced downstream AI classifiers, improving the true positive rate at low false-positive rates. Crucially, a blinded reader study demonstrated that novice endoscopists exposed to EndoRare-generated cases achieved a 0.400 increase in recall and a 0.267 increase in precision. These results establish a practical, data-efficient pathway to bridge the rare-disease gap in both computer-aided diagnostics and clinical education.
Evaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025
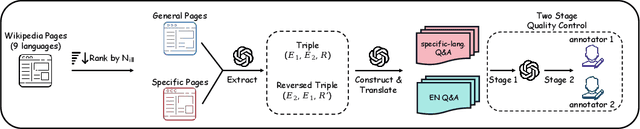


We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .
Robust Polyp Detection and Diagnosis through Compositional Prompt-Guided Diffusion Models
Feb 25, 2025Colorectal cancer (CRC) is a significant global health concern, and early detection through screening plays a critical role in reducing mortality. While deep learning models have shown promise in improving polyp detection, classification, and segmentation, their generalization across diverse clinical environments, particularly with out-of-distribution (OOD) data, remains a challenge. Multi-center datasets like PolypGen have been developed to address these issues, but their collection is costly and time-consuming. Traditional data augmentation techniques provide limited variability, failing to capture the complexity of medical images. Diffusion models have emerged as a promising solution for generating synthetic polyp images, but the image generation process in current models mainly relies on segmentation masks as the condition, limiting their ability to capture the full clinical context. To overcome these limitations, we propose a Progressive Spectrum Diffusion Model (PSDM) that integrates diverse clinical annotations-such as segmentation masks, bounding boxes, and colonoscopy reports-by transforming them into compositional prompts. These prompts are organized into coarse and fine components, allowing the model to capture both broad spatial structures and fine details, generating clinically accurate synthetic images. By augmenting training data with PSDM-generated samples, our model significantly improves polyp detection, classification, and segmentation. For instance, on the PolypGen dataset, PSDM increases the F1 score by 2.12% and the mean average precision by 3.09%, demonstrating superior performance in OOD scenarios and enhanced generalization.
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
Jan 24, 2025



This paper introduces the open-source dataset WanJuanSiLu, designed to provide high-quality training corpora for low-resource languages, thereby advancing the research and development of multilingual models. To achieve this, we have developed a systematic data processing framework tailored for low-resource languages. This framework encompasses key stages such as data extraction, corpus cleaning, content deduplication, security filtering, quality evaluation, and theme classification. Through the implementation of this framework, we have significantly improved both the quality and security of the dataset, while maintaining its linguistic diversity. As of now, data for all five languages have been fully open-sourced. The dataset can be accessed at https://opendatalab.com/applyMultilingualCorpus, and GitHub repository is available at https://github.com/opendatalab/WanJuan3.0
UIE-UnFold: Deep Unfolding Network with Color Priors and Vision Transformer for Underwater Image Enhancement
Aug 20, 2024



Underwater image enhancement (UIE) plays a crucial role in various marine applications, but it remains challenging due to the complex underwater environment. Current learning-based approaches frequently lack explicit incorporation of prior knowledge about the physical processes involved in underwater image formation, resulting in limited optimization despite their impressive enhancement results. This paper proposes a novel deep unfolding network (DUN) for UIE that integrates color priors and inter-stage feature transformation to improve enhancement performance. The proposed DUN model combines the iterative optimization and reliability of model-based methods with the flexibility and representational power of deep learning, offering a more explainable and stable solution compared to existing learning-based UIE approaches. The proposed model consists of three key components: a Color Prior Guidance Block (CPGB) that establishes a mapping between color channels of degraded and original images, a Nonlinear Activation Gradient Descent Module (NAGDM) that simulates the underwater image degradation process, and an Inter Stage Feature Transformer (ISF-Former) that facilitates feature exchange between different network stages. By explicitly incorporating color priors and modeling the physical characteristics of underwater image formation, the proposed DUN model achieves more accurate and reliable enhancement results. Extensive experiments on multiple underwater image datasets demonstrate the superiority of the proposed model over state-of-the-art methods in both quantitative and qualitative evaluations. The proposed DUN-based approach offers a promising solution for UIE, enabling more accurate and reliable scientific analysis in marine research. The code is available at https://github.com/CXH-Research/UIE-UnFold.
Unveiling the Impact of Multi-Modal Interactions on User Engagement: A Comprehensive Evaluation in AI-driven Conversations
Jun 21, 2024Large Language Models (LLMs) have significantly advanced user-bot interactions, enabling more complex and coherent dialogues. However, the prevalent text-only modality might not fully exploit the potential for effective user engagement. This paper explores the impact of multi-modal interactions, which incorporate images and audio alongside text, on user engagement in chatbot conversations. We conduct a comprehensive analysis using a diverse set of chatbots and real-user interaction data, employing metrics such as retention rate and conversation length to evaluate user engagement. Our findings reveal a significant enhancement in user engagement with multi-modal interactions compared to text-only dialogues. Notably, the incorporation of a third modality significantly amplifies engagement beyond the benefits observed with just two modalities. These results suggest that multi-modal interactions optimize cognitive processing and facilitate richer information comprehension. This study underscores the importance of multi-modality in chatbot design, offering valuable insights for creating more engaging and immersive AI communication experiences and informing the broader AI community about the benefits of multi-modal interactions in enhancing user engagement.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024



This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.