 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLip-to-Speech Synthesis for Arbitrary Speakers in the Wild
Sep 01, 2022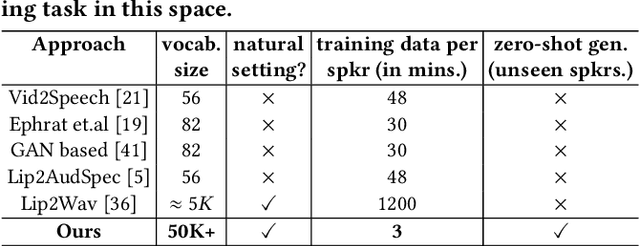
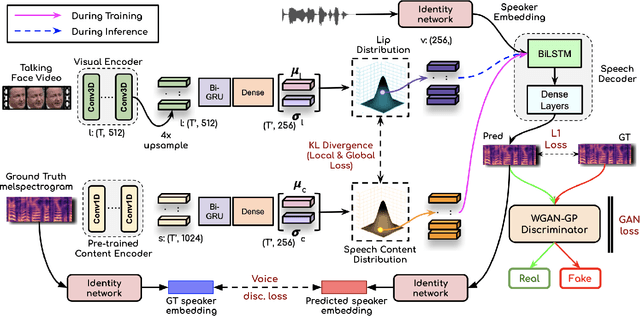
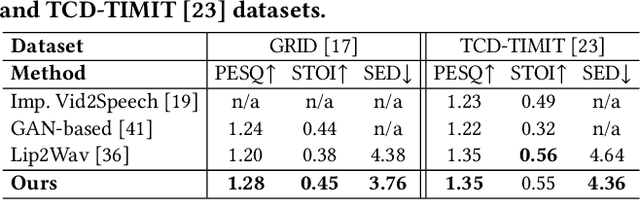
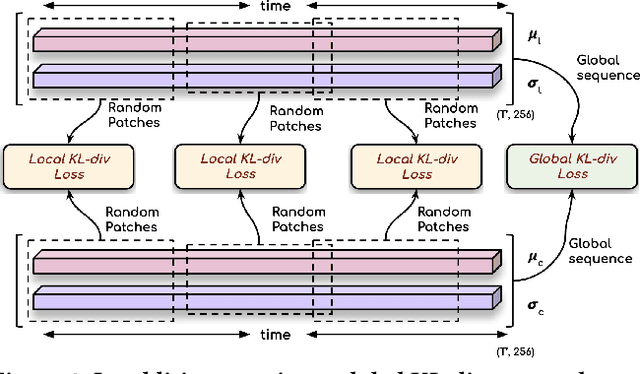
In this work, we address the problem of generating speech from silent lip videos for any speaker in the wild. In stark contrast to previous works, our method (i) is not restricted to a fixed number of speakers, (ii) does not explicitly impose constraints on the domain or the vocabulary and (iii) deals with videos that are recorded in the wild as opposed to within laboratory settings. The task presents a host of challenges, with the key one being that many features of the desired target speech, like voice, pitch and linguistic content, cannot be entirely inferred from the silent face video. In order to handle these stochastic variations, we propose a new VAE-GAN architecture that learns to associate the lip and speech sequences amidst the variations. With the help of multiple powerful discriminators that guide the training process, our generator learns to synthesize speech sequences in any voice for the lip movements of any person. Extensive experiments on multiple datasets show that we outperform all baselines by a large margin. Further, our network can be fine-tuned on videos of specific identities to achieve a performance comparable to single-speaker models that are trained on $4\times$ more data. We conduct numerous ablation studies to analyze the effect of different modules of our architecture. We also provide a demo video that demonstrates several qualitative results along with the code and trained models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/lip-to-speech-synthesis}}
FaceOff: A Video-to-Video Face Swapping System
Aug 21, 2022

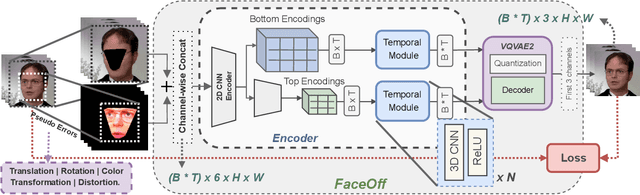
Doubles play an indispensable role in the movie industry. They take the place of the actors in dangerous stunt scenes or in scenes where the same actor plays multiple characters. The double's face is later replaced with the actor's face and expressions manually using expensive CGI technology, costing millions of dollars and taking months to complete. An automated, inexpensive, and fast way can be to use face-swapping techniques that aim to swap an identity from a source face video (or an image) to a target face video. However, such methods can not preserve the source expressions of the actor important for the scene's context. % essential for the scene. % that are essential in cinemas. To tackle this challenge, we introduce video-to-video (V2V) face-swapping, a novel task of face-swapping that can preserve (1) the identity and expressions of the source (actor) face video and (2) the background and pose of the target (double) video. We propose FaceOff, a V2V face-swapping system that operates by learning a robust blending operation to merge two face videos following the constraints above. It first reduces the videos to a quantized latent space and then blends them in the reduced space. FaceOff is trained in a self-supervised manner and robustly tackles the non-trivial challenges of V2V face-swapping. As shown in the experimental section, FaceOff significantly outperforms alternate approaches qualitatively and quantitatively.
Extreme-scale Talking-Face Video Upsampling with Audio-Visual Priors
Aug 17, 2022

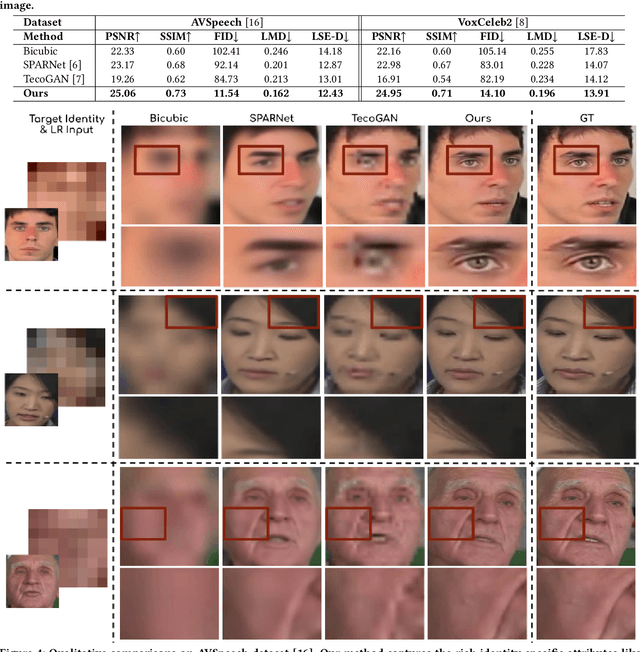
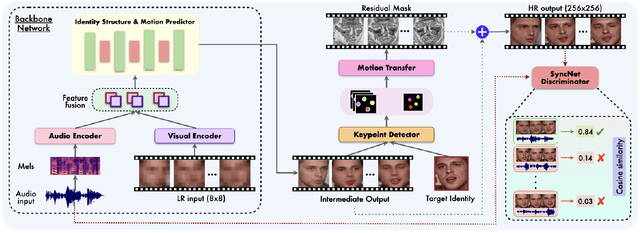
In this paper, we explore an interesting question of what can be obtained from an $8\times8$ pixel video sequence. Surprisingly, it turns out to be quite a lot. We show that when we process this $8\times8$ video with the right set of audio and image priors, we can obtain a full-length, $256\times256$ video. We achieve this $32\times$ scaling of an extremely low-resolution input using our novel audio-visual upsampling network. The audio prior helps to recover the elemental facial details and precise lip shapes and a single high-resolution target identity image prior provides us with rich appearance details. Our approach is an end-to-end multi-stage framework. The first stage produces a coarse intermediate output video that can be then used to animate single target identity image and generate realistic, accurate and high-quality outputs. Our approach is simple and performs exceedingly well (an $8\times$ improvement in FID score) compared to previous super-resolution methods. We also extend our model to talking-face video compression, and show that we obtain a $3.5\times$ improvement in terms of bits/pixel over the previous state-of-the-art. The results from our network are thoroughly analyzed through extensive ablation experiments (in the paper and supplementary material). We also provide the demo video along with code and models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/talking-face-video-upsampling}.
TRoVE: Transforming Road Scene Datasets into Photorealistic Virtual Environments
Aug 16, 2022
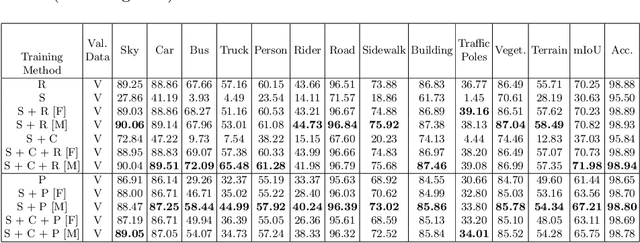
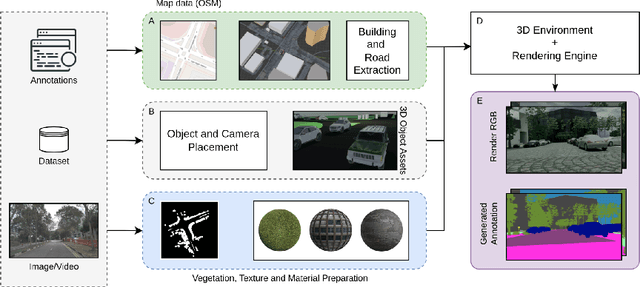
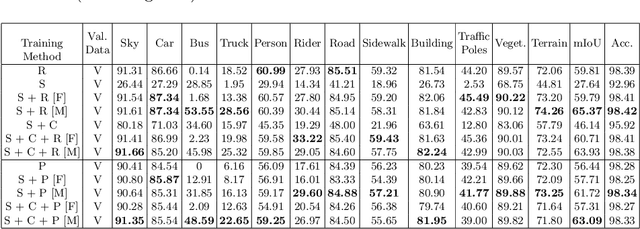
High-quality structured data with rich annotations are critical components in intelligent vehicle systems dealing with road scenes. However, data curation and annotation require intensive investments and yield low-diversity scenarios. The recently growing interest in synthetic data raises questions about the scope of improvement in such systems and the amount of manual work still required to produce high volumes and variations of simulated data. This work proposes a synthetic data generation pipeline that utilizes existing datasets, like nuScenes, to address the difficulties and domain-gaps present in simulated datasets. We show that using annotations and visual cues from existing datasets, we can facilitate automated multi-modal data generation, mimicking real scene properties with high-fidelity, along with mechanisms to diversify samples in a physically meaningful way. We demonstrate improvements in mIoU metrics by presenting qualitative and quantitative experiments with real and synthetic data for semantic segmentation on the Cityscapes and KITTI-STEP datasets. All relevant code and data is released on github (https://github.com/shubham1810/trove_toolkit).
My View is the Best View: Procedure Learning from Egocentric Videos
Jul 22, 2022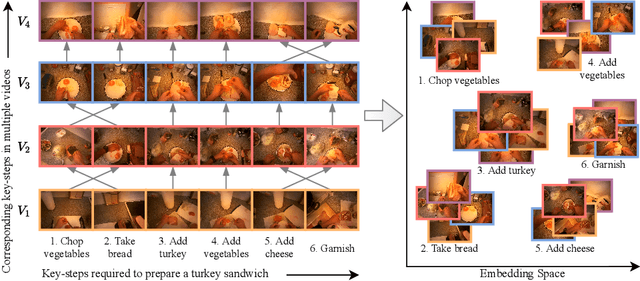


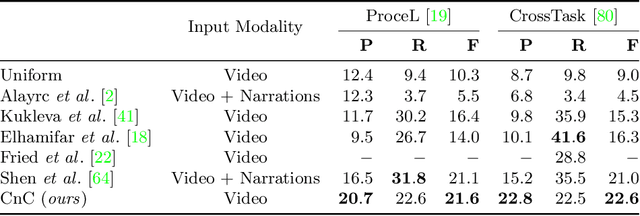
Procedure learning involves identifying the key-steps and determining their logical order to perform a task. Existing approaches commonly use third-person videos for learning the procedure, making the manipulated object small in appearance and often occluded by the actor, leading to significant errors. In contrast, we observe that videos obtained from first-person (egocentric) wearable cameras provide an unobstructed and clear view of the action. However, procedure learning from egocentric videos is challenging because (a) the camera view undergoes extreme changes due to the wearer's head motion, and (b) the presence of unrelated frames due to the unconstrained nature of the videos. Due to this, current state-of-the-art methods' assumptions that the actions occur at approximately the same time and are of the same duration, do not hold. Instead, we propose to use the signal provided by the temporal correspondences between key-steps across videos. To this end, we present a novel self-supervised Correspond and Cut (CnC) framework for procedure learning. CnC identifies and utilizes the temporal correspondences between the key-steps across multiple videos to learn the procedure. Our experiments show that CnC outperforms the state-of-the-art on the benchmark ProceL and CrossTask datasets by 5.2% and 6.3%, respectively. Furthermore, for procedure learning using egocentric videos, we propose the EgoProceL dataset consisting of 62 hours of videos captured by 130 subjects performing 16 tasks. The source code and the dataset are available on the project page https://sid2697.github.io/egoprocel/.
Detecting, Tracking and Counting Motorcycle Rider Traffic Violations on Unconstrained Roads
Apr 18, 2022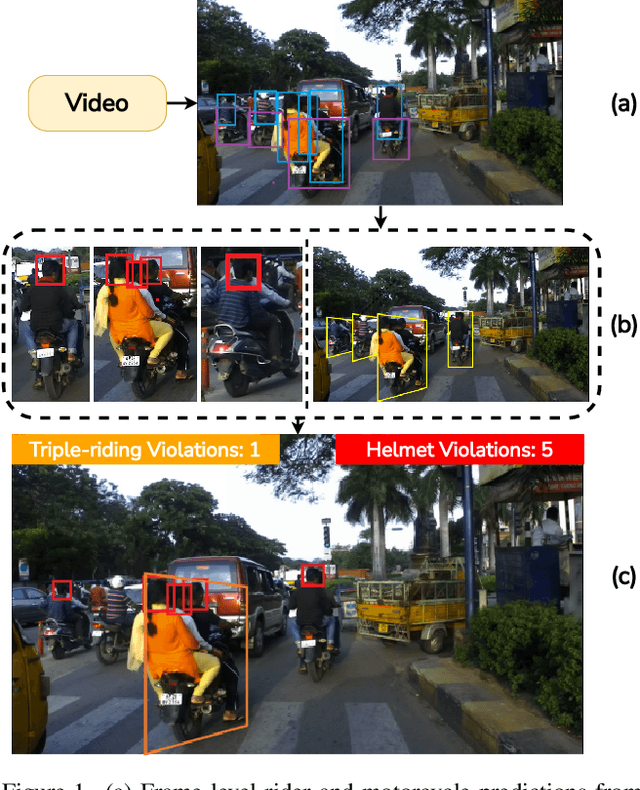
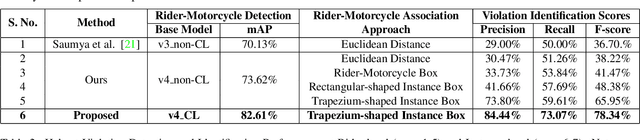
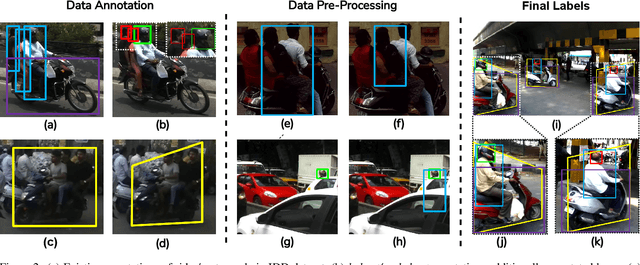
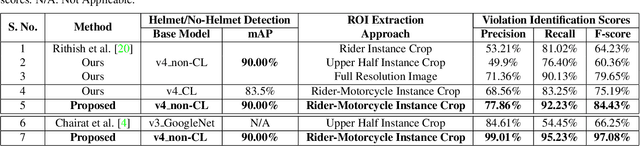
In many Asian countries with unconstrained road traffic conditions, driving violations such as not wearing helmets and triple-riding are a significant source of fatalities involving motorcycles. Identifying and penalizing such riders is vital in curbing road accidents and improving citizens' safety. With this motivation, we propose an approach for detecting, tracking, and counting motorcycle riding violations in videos taken from a vehicle-mounted dashboard camera. We employ a curriculum learning-based object detector to better tackle challenging scenarios such as occlusions. We introduce a novel trapezium-shaped object boundary representation to increase robustness and tackle the rider-motorcycle association. We also introduce an amodal regressor that generates bounding boxes for the occluded riders. Experimental results on a large-scale unconstrained driving dataset demonstrate the superiority of our approach compared to existing approaches and other ablative variants.
Classroom Slide Narration System
Jan 21, 2022

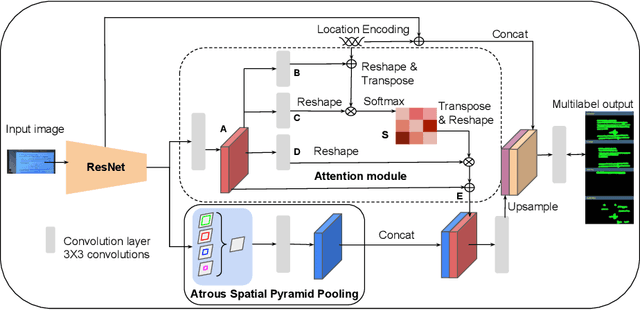
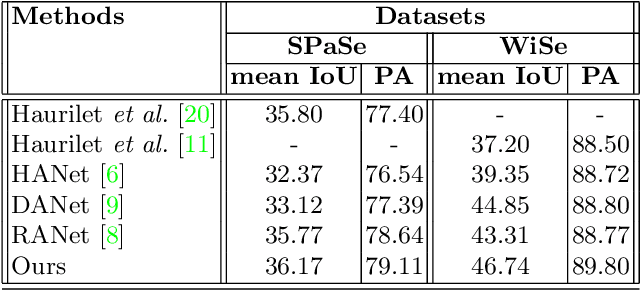
Slide presentations are an effective and efficient tool used by the teaching community for classroom communication. However, this teaching model can be challenging for blind and visually impaired (VI) students. The VI student required personal human assistance for understand the presented slide. This shortcoming motivates us to design a Classroom Slide Narration System (CSNS) that generates audio descriptions corresponding to the slide content. This problem poses as an image-to-markup language generation task. The initial step is to extract logical regions such as title, text, equation, figure, and table from the slide image. In the classroom slide images, the logical regions are distributed based on the location of the image. To utilize the location of the logical regions for slide image segmentation, we propose the architecture, Classroom Slide Segmentation Network (CSSN). The unique attributes of this architecture differs from most other semantic segmentation networks. Publicly available benchmark datasets such as WiSe and SPaSe are used to validate the performance of our segmentation architecture. We obtained 9.54 segmentation accuracy improvement in WiSe dataset. We extract content (information) from the slide using four well-established modules such as optical character recognition (OCR), figure classification, equation description, and table structure recognizer. With this information, we build a Classroom Slide Narration System (CSNS) to help VI students understand the slide content. The users have given better feedback on the quality output of the proposed CSNS in comparison to existing systems like Facebooks Automatic Alt-Text (AAT) and Tesseract.
Automatic Quantification and Visualization of Street Trees
Jan 17, 2022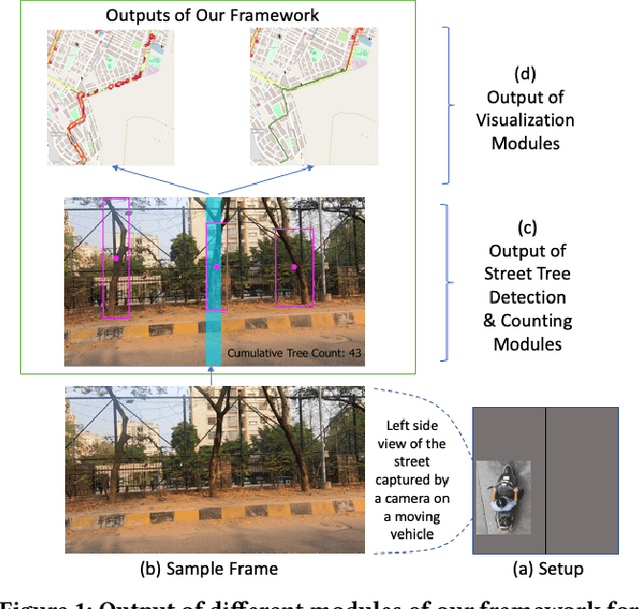

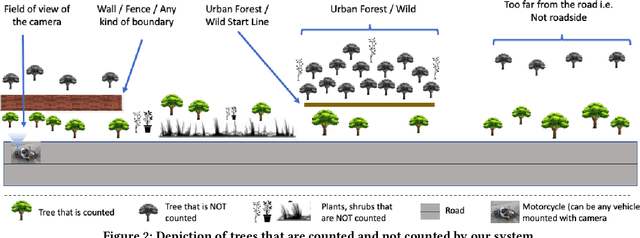
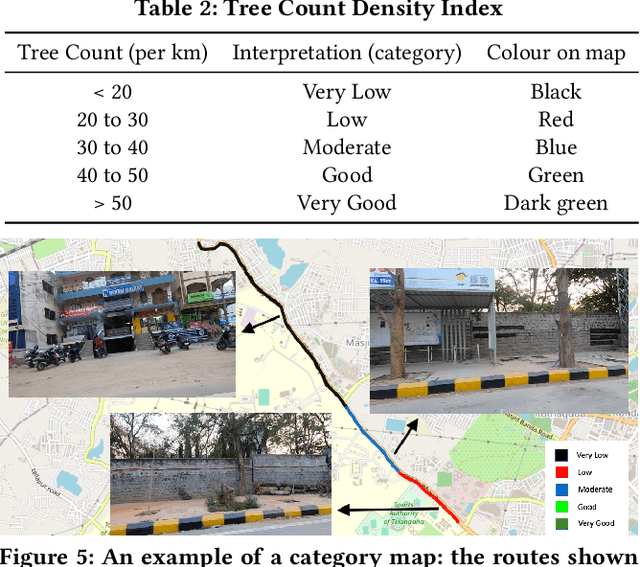
Assessing the number of street trees is essential for evaluating urban greenery and can help municipalities employ solutions to identify tree-starved streets. It can also help identify roads with different levels of deforestation and afforestation over time. Yet, there has been little work in the area of street trees quantification. This work first explains a data collection setup carefully designed for counting roadside trees. We then describe a unique annotation procedure aimed at robustly detecting and quantifying trees. We work on a dataset of around 1300 Indian road scenes annotated with over 2500 street trees. We additionally use the five held-out videos covering 25 km of roads for counting trees. We finally propose a street tree detection, counting, and visualization framework using current object detectors and a novel yet simple counting algorithm owing to the thoughtful collection setup. We find that the high-level visualizations based on the density of trees on the routes and Kernel Density Ranking (KDR) provide a quick, accurate, and inexpensive way to recognize tree-starved streets. We obtain a tree detection mAP of 83.74% on the test images, which is a 2.73% improvement over our baseline. We propose Tree Count Density Classification Accuracy (TCDCA) as an evaluation metric to measure tree density. We obtain TCDCA of 96.77% on the test videos, with a remarkable improvement of 22.58% over baseline, and demonstrate that our counting module's performance is close to human level. Source code: https://github.com/iHubData-Mobility/public-tree-counting.
Towards Boosting the Accuracy of Non-Latin Scene Text Recognition
Jan 10, 2022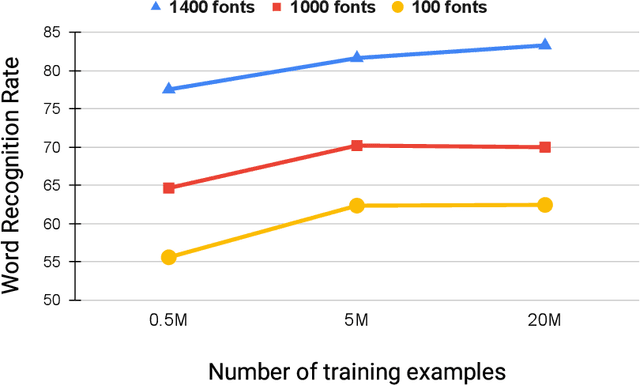

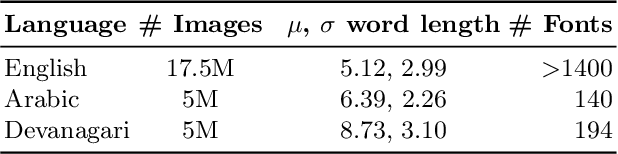

Scene-text recognition is remarkably better in Latin languages than the non-Latin languages due to several factors like multiple fonts, simplistic vocabulary statistics, updated data generation tools, and writing systems. This paper examines the possible reasons for low accuracy by comparing English datasets with non-Latin languages. We compare various features like the size (width and height) of the word images and word length statistics. Over the last decade, generating synthetic datasets with powerful deep learning techniques has tremendously improved scene-text recognition. Several controlled experiments are performed on English, by varying the number of (i) fonts to create the synthetic data and (ii) created word images. We discover that these factors are critical for the scene-text recognition systems. The English synthetic datasets utilize over 1400 fonts while Arabic and other non-Latin datasets utilize less than 100 fonts for data generation. Since some of these languages are a part of different regions, we garner additional fonts through a region-based search to improve the scene-text recognition models in Arabic and Devanagari. We improve the Word Recognition Rates (WRRs) on Arabic MLT-17 and MLT-19 datasets by 24.54% and 2.32% compared to previous works or baselines. We achieve WRR gains of 7.88% and 3.72% for IIIT-ILST and MLT-19 Devanagari datasets.
* 12 pages, 6 figures
Transfer Learning for Scene Text Recognition in Indian Languages
Jan 10, 2022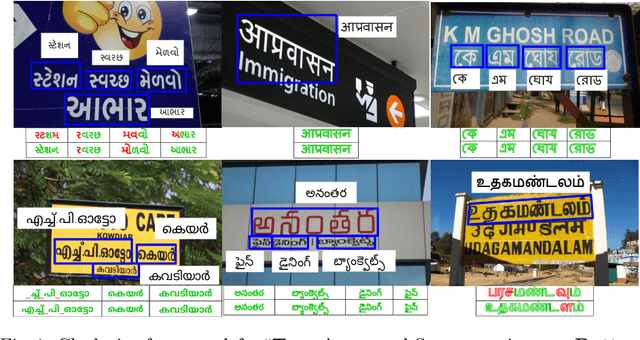
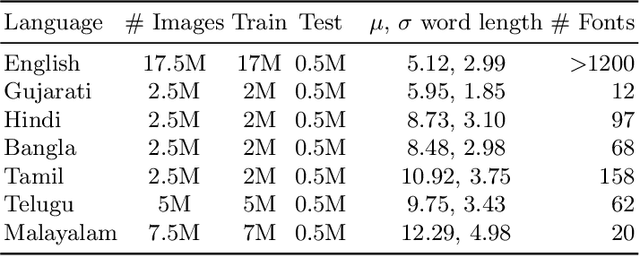

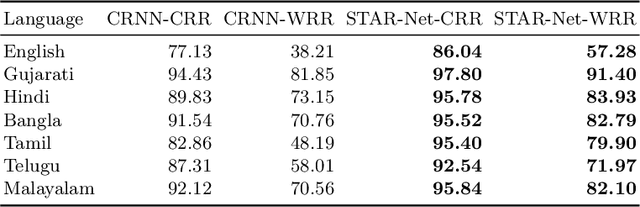
Scene text recognition in low-resource Indian languages is challenging because of complexities like multiple scripts, fonts, text size, and orientations. In this work, we investigate the power of transfer learning for all the layers of deep scene text recognition networks from English to two common Indian languages. We perform experiments on the conventional CRNN model and STAR-Net to ensure generalisability. To study the effect of change in different scripts, we initially run our experiments on synthetic word images rendered using Unicode fonts. We show that the transfer of English models to simple synthetic datasets of Indian languages is not practical. Instead, we propose to apply transfer learning techniques among Indian languages due to similarity in their n-gram distributions and visual features like the vowels and conjunct characters. We then study the transfer learning among six Indian languages with varying complexities in fonts and word length statistics. We also demonstrate that the learned features of the models transferred from other Indian languages are visually closer (and sometimes even better) to the individual model features than those transferred from English. We finally set new benchmarks for scene-text recognition on Hindi, Telugu, and Malayalam datasets from IIIT-ILST and Bangla dataset from MLT-17 by achieving 6%, 5%, 2%, and 23% gains in Word Recognition Rates (WRRs) compared to previous works. We further improve the MLT-17 Bangla results by plugging in a novel correction BiLSTM into our model. We additionally release a dataset of around 440 scene images containing 500 Gujarati and 2535 Tamil words. WRRs improve over the baselines by 8%, 4%, 5%, and 3% on the MLT-19 Hindi and Bangla datasets and the Gujarati and Tamil datasets.
* 16 pages, 5 figures