 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Quantifiable Visual Explanations Without Ground-Truth
May 18, 2026Explainable AI (XAI) techniques are increasingly important for the validation and responsible use of modern deep learning models, but are difficult to evaluate due to the lack of good ground-truth to compare against. We propose a framework that serves as a quantifiable metric for the quality of XAI methods, based on continuous input perturbation. Our metric formally considers the sufficiency and necessity of the attributed information to the model's decision-making, and we illustrate a range of cases where it aligns better with human intuitions of explanation quality than do existing metrics. To exploit the properties of this metric, we also propose a novel XAI method, considering the case where we fine-tune a model using a differentiable approximation of the metric as a supervision signal. The result is an adapter module that can be trained on top of any black-box model to output causal explanations of the model's decision process, without degrading model performance. We show that the explanations generated by this method outperform those of competing XAI techniques according to a number of quantifiable metrics.
Reading in the Dark: Low-light Scene Text Recognition
Apr 26, 2026Accurate text recognition in low-light environments is essential for intelligent systems in applications ranging from autonomous vehicles to smart surveillance. However, challenges such as poor illumination and noise interference remain underexplored. To address this gap, we introduce LSTR, a large-scale Low-light Scene Text Recognition dataset comprising 11,273 low-light images generated from well-lit datasets (ICDAR2015, IIIT5K, and WordArt), along with ESTR, which includes 60 real nighttime street-scene images in English and Spanish for exclusive evaluation. We explore two solution strategies: (1) employing Optical Character Recognition (OCR) models with fine-tuning and LoRA-based fine-tuning and (2) a joint training strategy that integrates a low-light image enhancement (LLIE) module with an OCR model. In particular, we propose a novel re-render LLIE (RLLIE) module, which demonstrates improved performance on real-world data. Through extensive experimentation, we analyze various training strategies and address a key research question: \emph{How bright is bright enough for effective scene text recognition?} Our results indicate that standalone LLIE or OCR models perform inadequately under low-light conditions, highlighting the advantages of specialized, jointly trained text-centric approaches. Additionally, we provide a comprehensive benchmark to support future research in robust low-light scene text recognition. https://huggingface.co/datasets/lumimusta/Low-light_Scene_Text_Dataset.
Enhancing Document VQA Models via Retrieval-Augmented Generation
Aug 28, 2025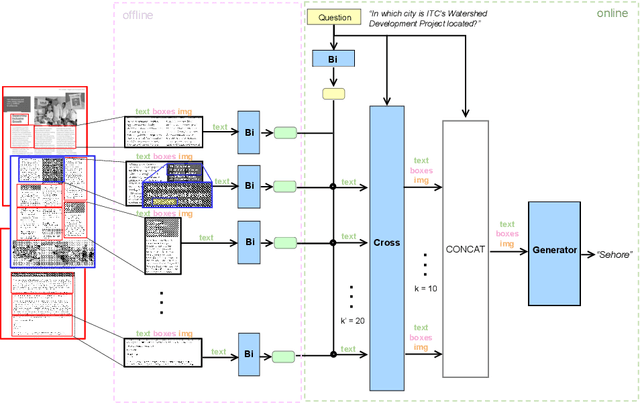
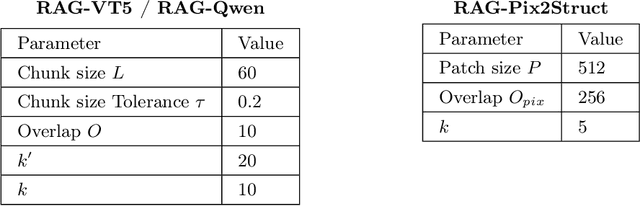
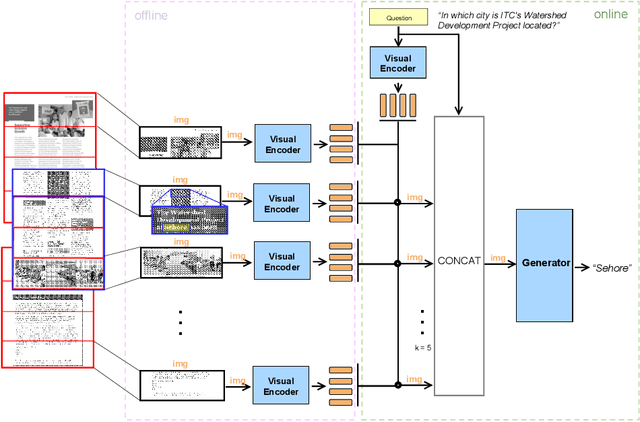
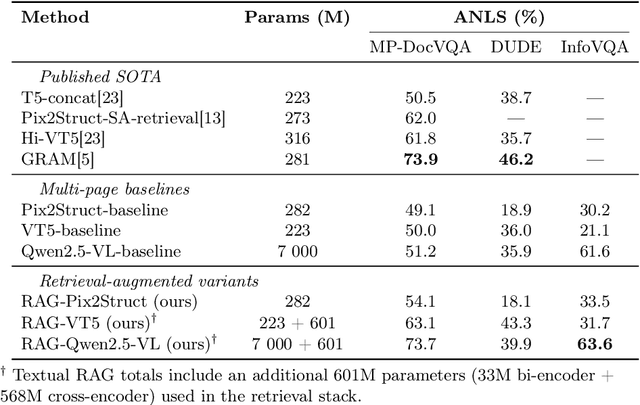
Document Visual Question Answering (Document VQA) must cope with documents that span dozens of pages, yet leading systems still concatenate every page or rely on very large vision-language models, both of which are memory-hungry. Retrieval-Augmented Generation (RAG) offers an attractive alternative, first retrieving a concise set of relevant segments before generating answers from this selected evidence. In this paper, we systematically evaluate the impact of incorporating RAG into Document VQA through different retrieval variants - text-based retrieval using OCR tokens and purely visual retrieval without OCR - across multiple models and benchmarks. Evaluated on the multi-page datasets MP-DocVQA, DUDE, and InfographicVQA, the text-centric variant improves the "concatenate-all-pages" baseline by up to +22.5 ANLS, while the visual variant achieves +5.0 ANLS improvement without requiring any text extraction. An ablation confirms that retrieval and reranking components drive most of the gain, whereas the layout-guided chunking strategy - proposed in several recent works to leverage page structure - fails to help on these datasets. Our experiments demonstrate that careful evidence selection consistently boosts accuracy across multiple model sizes and multi-page benchmarks, underscoring its practical value for real-world Document VQA.
LLM-Driven Medical Document Analysis: Enhancing Trustworthy Pathology and Differential Diagnosis
Jun 24, 2025Medical document analysis plays a crucial role in extracting essential clinical insights from unstructured healthcare records, supporting critical tasks such as differential diagnosis. Determining the most probable condition among overlapping symptoms requires precise evaluation and deep medical expertise. While recent advancements in large language models (LLMs) have significantly enhanced performance in medical document analysis, privacy concerns related to sensitive patient data limit the use of online LLMs services in clinical settings. To address these challenges, we propose a trustworthy medical document analysis platform that fine-tunes a LLaMA-v3 using low-rank adaptation, specifically optimized for differential diagnosis tasks. Our approach utilizes DDXPlus, the largest benchmark dataset for differential diagnosis, and demonstrates superior performance in pathology prediction and variable-length differential diagnosis compared to existing methods. The developed web-based platform allows users to submit their own unstructured medical documents and receive accurate, explainable diagnostic results. By incorporating advanced explainability techniques, the system ensures transparent and reliable predictions, fostering user trust and confidence. Extensive evaluations confirm that the proposed method surpasses current state-of-the-art models in predictive accuracy while offering practical utility in clinical settings. This work addresses the urgent need for reliable, explainable, and privacy-preserving artificial intelligence solutions, representing a significant advancement in intelligent medical document analysis for real-world healthcare applications. The code can be found at \href{https://github.com/leitro/Differential-Diagnosis-LoRA}{https://github.com/leitro/Differential-Diagnosis-LoRA}.
DocVXQA: Context-Aware Visual Explanations for Document Question Answering
May 12, 2025We propose DocVXQA, a novel framework for visually self-explainable document question answering. The framework is designed not only to produce accurate answers to questions but also to learn visual heatmaps that highlight contextually critical regions, thereby offering interpretable justifications for the model's decisions. To integrate explanations into the learning process, we quantitatively formulate explainability principles as explicit learning objectives. Unlike conventional methods that emphasize only the regions pertinent to the answer, our framework delivers explanations that are \textit{contextually sufficient} while remaining \textit{representation-efficient}. This fosters user trust while achieving a balance between predictive performance and interpretability in DocVQA applications. Extensive experiments, including human evaluation, provide strong evidence supporting the effectiveness of our method. The code is available at https://github.com/dali92002/DocVXQA.
xLSTM-ECG: Multi-label ECG Classification via Feature Fusion with xLSTM
Apr 14, 2025



Cardiovascular diseases (CVDs) remain the leading cause of mortality worldwide, highlighting the critical need for efficient and accurate diagnostic tools. Electrocardiograms (ECGs) are indispensable in diagnosing various heart conditions; however, their manual interpretation is time-consuming and error-prone. In this paper, we propose xLSTM-ECG, a novel approach that leverages an extended Long Short-Term Memory (xLSTM) network for multi-label classification of ECG signals, using the PTB-XL dataset. To the best of our knowledge, this work represents the first design and application of xLSTM modules specifically adapted for multi-label ECG classification. Our method employs a Short-Time Fourier Transform (STFT) to convert time-series ECG waveforms into the frequency domain, thereby enhancing feature extraction. The xLSTM architecture is specifically tailored to address the complexities of 12-lead ECG recordings by capturing both local and global signal features. Comprehensive experiments on the PTB-XL dataset reveal that our model achieves strong multi-label classification performance, while additional tests on the Georgia 12-Lead dataset underscore its robustness and efficiency. This approach significantly improves ECG classification accuracy, thereby advancing clinical diagnostics and patient care. The code will be publicly available upon acceptance.
Preserving Privacy Without Compromising Accuracy: Machine Unlearning for Handwritten Text Recognition
Apr 11, 2025



Handwritten Text Recognition (HTR) is essential for document analysis and digitization. However, handwritten data often contains user-identifiable information, such as unique handwriting styles and personal lexicon choices, which can compromise privacy and erode trust in AI services. Legislation like the ``right to be forgotten'' underscores the necessity for methods that can expunge sensitive information from trained models. Machine unlearning addresses this by selectively removing specific data from models without necessitating complete retraining. Yet, it frequently encounters a privacy-accuracy tradeoff, where safeguarding privacy leads to diminished model performance. In this paper, we introduce a novel two-stage unlearning strategy for a multi-head transformer-based HTR model, integrating pruning and random labeling. Our proposed method utilizes a writer classification head both as an indicator and a trigger for unlearning, while maintaining the efficacy of the recognition head. To our knowledge, this represents the first comprehensive exploration of machine unlearning within HTR tasks. We further employ Membership Inference Attacks (MIA) to evaluate the effectiveness of unlearning user-identifiable information. Extensive experiments demonstrate that our approach effectively preserves privacy while maintaining model accuracy, paving the way for new research directions in the document analysis community. Our code will be publicly available upon acceptance.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
GRIF-DM: Generation of Rich Impression Fonts using Diffusion Models
Aug 14, 2024



Fonts are integral to creative endeavors, design processes, and artistic productions. The appropriate selection of a font can significantly enhance artwork and endow advertisements with a higher level of expressivity. Despite the availability of numerous diverse font designs online, traditional retrieval-based methods for font selection are increasingly being supplanted by generation-based approaches. These newer methods offer enhanced flexibility, catering to specific user preferences and capturing unique stylistic impressions. However, current impression font techniques based on Generative Adversarial Networks (GANs) necessitate the utilization of multiple auxiliary losses to provide guidance during generation. Furthermore, these methods commonly employ weighted summation for the fusion of impression-related keywords. This leads to generic vectors with the addition of more impression keywords, ultimately lacking in detail generation capacity. In this paper, we introduce a diffusion-based method, termed \ourmethod, to generate fonts that vividly embody specific impressions, utilizing an input consisting of a single letter and a set of descriptive impression keywords. The core innovation of \ourmethod lies in the development of dual cross-attention modules, which process the characteristics of the letters and impression keywords independently but synergistically, ensuring effective integration of both types of information. Our experimental results, conducted on the MyFonts dataset, affirm that this method is capable of producing realistic, vibrant, and high-fidelity fonts that are closely aligned with user specifications. This confirms the potential of our approach to revolutionize font generation by accommodating a broad spectrum of user-driven design requirements. Our code is publicly available at \url{https://github.com/leitro/GRIF-DM}.
Image-text matching for large-scale book collections
Jul 29, 2024



We address the problem of detecting and mapping all books in a collection of images to entries in a given book catalogue. Instead of performing independent retrieval for each book detected, we treat the image-text mapping problem as a many-to-many matching process, looking for the best overall match between the two sets. We combine a state-of-the-art segmentation method (SAM) to detect book spines and extract book information using a commercial OCR. We then propose a two-stage approach for text-image matching, where CLIP embeddings are used first for fast matching, followed by a second slower stage to refine the matching, employing either the Hungarian Algorithm or a BERT-based model trained to cope with noisy OCR input and partial text matches. To evaluate our approach, we publish a new dataset of annotated bookshelf images that covers the whole book collection of a public library in Spain. In addition, we provide two target lists of book metadata, a closed-set of 15k book titles that corresponds to the known library inventory, and an open-set of 2.3M book titles to simulate an open-world scenario. We report results on two settings, on one hand on a matching-only task, where the book segments and OCR is given and the objective is to perform many-to-many matching against the target lists, and a combined detection and matching task, where books must be first detected and recognised before they are matched to the target list entries. We show that both the Hungarian Matching and the proposed BERT-based model outperform a fuzzy string matching baseline, and we highlight inherent limitations of the matching algorithms as the target increases in size, and when either of the two sets (detected books or target book list) is incomplete. The dataset and code are available at https://github.com/llabres/library-dataset