 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal Concept Lattices are Good Semantic Scaffolds for Concept-Based Learning
Jun 03, 2026Learning semantics is essential for deep learning models to be interpretable and better aligned with human reasoning. Concept-based models approach this by representing classes through meaningful semantic abstractions, but typically treat all concepts as a flat, unstructured set learned at a single neural network layer. This overlooks a fundamental property of human semantic understanding: concepts being organized hierarchically, from general to specific. While deep networks do learn a hierarchy of visual features, this structure is rarely aligned with explicit semantic hierarchies. Drawing on Formal Concept Analysis, we demonstrate that formal concept lattices provide principled semantic scaffolds to guide neural network learning. These lattices naturally identify where in the network concepts should be learned based on their level of generality. This allows the model to develop staged, semantically grounded representations throughout its depth. Empirical results on real-world datasets show that our models produce more interpretable embeddings, support more effective interventions, and learn concept representations that are both meaningful and hierarchically structured.
Faithful GRPO: Improving Visual Spatial Reasoning in Multimodal Language Models via Constrained Policy Optimization
Apr 09, 2026Multimodal reasoning models (MRMs) trained with reinforcement learning with verifiable rewards (RLVR) show improved accuracy on visual reasoning benchmarks. However, we observe that accuracy gains often come at the cost of reasoning quality: generated Chain-of-Thought (CoT) traces are frequently inconsistent with the final answer and poorly grounded in the visual evidence. We systematically study this phenomenon across seven challenging real-world spatial reasoning benchmarks and find that it affects contemporary MRMs such as ViGoRL-Spatial, TreeVGR as well as our own models trained with standard Group Relative Policy Optimization (GRPO). We characterize CoT reasoning quality along two complementary axes: "logical consistency" (does the CoT entail the final answer?) and "visual grounding" (does each reasoning step accurately describe objects, attributes, and spatial relationships in the image?). To address this, we propose Faithful GRPO (FGRPO), a variant of GRPO that enforces consistency and grounding as constraints via Lagrangian dual ascent. FGRPO incorporates batch-level consistency and grounding constraints into the advantage computation within a group, adaptively adjusting the relative importance of constraints during optimization. We evaluate FGRPO on Qwen2.5-VL-7B and 3B backbones across seven spatial datasets. Our results show that FGRPO substantially improves reasoning quality, reducing the inconsistency rate from 24.5% to 1.7% and improving visual grounding scores by +13%. It also improves final answer accuracy over simple GRPO, demonstrating that faithful reasoning enables better answers.
Source-Free Domain Adaptation by Optimizing Batch-Wise Cosine Similarity
Jan 24, 2026Source-Free Domain Adaptation (SFDA) is an emerging area of research that aims to adapt a model trained on a labeled source domain to an unlabeled target domain without accessing the source data. Most of the successful methods in this area rely on the concept of neighborhood consistency but are prone to errors due to misleading neighborhood information. In this paper, we explore this approach from the point of view of learning more informative clusters and mitigating the effect of noisy neighbors using a concept called neighborhood signature, and demonstrate that adaptation can be achieved using just a single loss term tailored to optimize the similarity and dissimilarity of predictions of samples in the target domain. In particular, our proposed method outperforms existing methods in the challenging VisDA dataset while also yielding competitive results on other benchmark datasets.
iSHIFT: Lightweight Slow-Fast GUI Agent with Adaptive Perception
Dec 26, 2025



Multimodal Large Language Models (MLLMs) show strong potential for interpreting and interacting with complex, pixel-rich Graphical User Interface (GUI) environments. However, building agents that are both efficient for high-level tasks and precise for fine-grained interactions remains challenging. GUI agents must perform routine actions efficiently while also handling tasks that demand exact visual grounding, yet existing approaches struggle when accuracy depends on identifying specific interface elements. These MLLMs also remain large and cannot adapt their reasoning depth to the task at hand. In this work, we introduce iSHIFT: Implicit Slow-fast Hybrid Inference with Flexible Tokens, a lightweight agent that integrates latent thinking (implicit chain-of-thought) with a perception control module. iSHIFT enables an MLLM to switch between a slow mode, which leverages detailed visual grounding for high precision and a fast mode that uses global cues for efficiency. Special perception tokens guide attention to relevant screen regions, allowing the model to decide both how to reason and where to focus. Despite its compact 2.5B size, iSHIFT matches state-of-the-art performance on multiple benchmark datasets.
Foundation Model Priors Enhance Object Focus in Feature Space for Source-Free Object Detection
Dec 24, 2025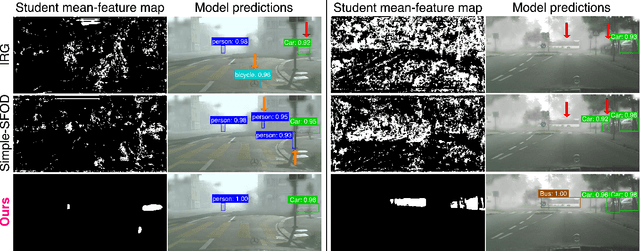
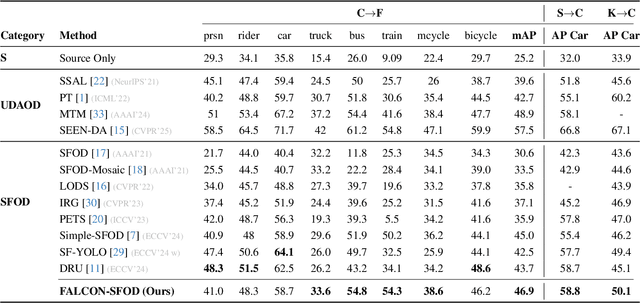
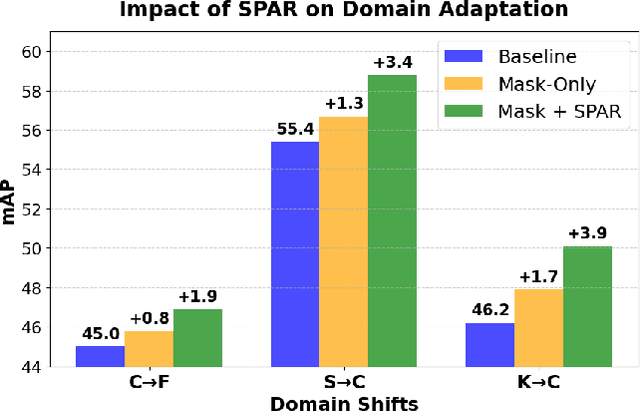
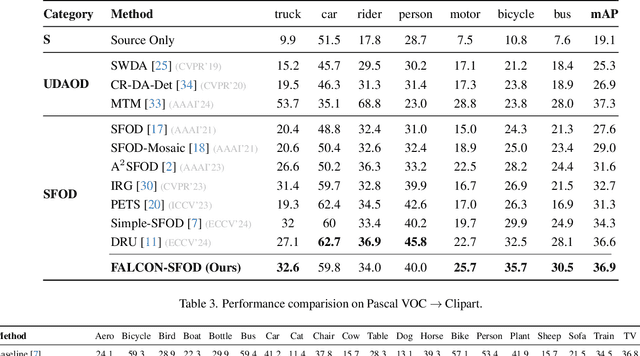
Current state-of-the-art approaches in Source-Free Object Detection (SFOD) typically rely on Mean-Teacher self-labeling. However, domain shift often reduces the detector's ability to maintain strong object-focused representations, causing high-confidence activations over background clutter. This weak object focus results in unreliable pseudo-labels from the detection head. While prior works mainly refine these pseudo-labels, they overlook the underlying need to strengthen the feature space itself. We propose FALCON-SFOD (Foundation-Aligned Learning with Clutter suppression and Noise robustness), a framework designed to enhance object-focused adaptation under domain shift. It consists of two complementary components. SPAR (Spatial Prior-Aware Regularization) leverages the generalization strength of vision foundation models to regularize the detector's feature space. Using class-agnostic binary masks derived from OV-SAM, SPAR promotes structured and foreground-focused activations by guiding the network toward object regions. IRPL (Imbalance-aware Noise Robust Pseudo-Labeling) complements SPAR by promoting balanced and noise-tolerant learning under severe foreground-background imbalance. Guided by a theoretical analysis that connects these designs to tighter localization and classification error bounds, FALCON-SFOD achieves competitive performance across SFOD benchmarks.
LogicCBMs: Logic-Enhanced Concept-Based Learning
Dec 08, 2025



Concept Bottleneck Models (CBMs) provide a basis for semantic abstractions within a neural network architecture. Such models have primarily been seen through the lens of interpretability so far, wherein they offer transparency by inferring predictions as a linear combination of semantic concepts. However, a linear combination is inherently limiting. So we propose the enhancement of concept-based learning models through propositional logic. We introduce a logic module that is carefully designed to connect the learned concepts from CBMs through differentiable logic operations, such that our proposed LogicCBM can go beyond simple weighted combinations of concepts to leverage various logical operations to yield the final predictions, while maintaining end-to-end learnability. Composing concepts using a set of logic operators enables the model to capture inter-concept relations, while simultaneously improving the expressivity of the model in terms of logic operations. Our empirical studies on well-known benchmarks and synthetic datasets demonstrate that these models have better accuracy, perform effective interventions and are highly interpretable.
Mitigate One, Skew Another? Tackling Intersectional Biases in Text-to-Image Models
May 22, 2025The biases exhibited by text-to-image (TTI) models are often treated as independent, though in reality, they may be deeply interrelated. Addressing bias along one dimension - such as ethnicity or age - can inadvertently affect another, like gender, either mitigating or exacerbating existing disparities. Understanding these interdependencies is crucial for designing fairer generative models, yet measuring such effects quantitatively remains a challenge. To address this, we introduce BiasConnect, a novel tool for analyzing and quantifying bias interactions in TTI models. BiasConnect uses counterfactual interventions along different bias axes to reveal the underlying structure of these interactions and estimates the effect of mitigating one bias axis on another. These estimates show strong correlation (+0.65) with observed post-mitigation outcomes. Building on BiasConnect, we propose InterMit, an intersectional bias mitigation algorithm guided by user-defined target distributions and priority weights. InterMit achieves lower bias (0.33 vs. 0.52) with fewer mitigation steps (2.38 vs. 3.15 average steps), and yields superior image quality compared to traditional techniques. Although our implementation is training-free, InterMit is modular and can be integrated with many existing debiasing approaches for TTI models, making it a flexible and extensible solution.
Efficient Vocabulary-Free Fine-Grained Visual Recognition in the Age of Multimodal LLMs
May 02, 2025Fine-grained Visual Recognition (FGVR) involves distinguishing between visually similar categories, which is inherently challenging due to subtle inter-class differences and the need for large, expert-annotated datasets. In domains like medical imaging, such curated datasets are unavailable due to issues like privacy concerns and high annotation costs. In such scenarios lacking labeled data, an FGVR model cannot rely on a predefined set of training labels, and hence has an unconstrained output space for predictions. We refer to this task as Vocabulary-Free FGVR (VF-FGVR), where a model must predict labels from an unconstrained output space without prior label information. While recent Multimodal Large Language Models (MLLMs) show potential for VF-FGVR, querying these models for each test input is impractical because of high costs and prohibitive inference times. To address these limitations, we introduce \textbf{Nea}rest-Neighbor Label \textbf{R}efinement (NeaR), a novel approach that fine-tunes a downstream CLIP model using labels generated by an MLLM. Our approach constructs a weakly supervised dataset from a small, unlabeled training set, leveraging MLLMs for label generation. NeaR is designed to handle the noise, stochasticity, and open-endedness inherent in labels generated by MLLMs, and establishes a new benchmark for efficient VF-FGVR.
POET: Prompt Offset Tuning for Continual Human Action Adaptation
Apr 25, 2025As extended reality (XR) is redefining how users interact with computing devices, research in human action recognition is gaining prominence. Typically, models deployed on immersive computing devices are static and limited to their default set of classes. The goal of our research is to provide users and developers with the capability to personalize their experience by adding new action classes to their device models continually. Importantly, a user should be able to add new classes in a low-shot and efficient manner, while this process should not require storing or replaying any of user's sensitive training data. We formalize this problem as privacy-aware few-shot continual action recognition. Towards this end, we propose POET: Prompt-Offset Tuning. While existing prompt tuning approaches have shown great promise for continual learning of image, text, and video modalities; they demand access to extensively pretrained transformers. Breaking away from this assumption, POET demonstrates the efficacy of prompt tuning a significantly lightweight backbone, pretrained exclusively on the base class data. We propose a novel spatio-temporal learnable prompt offset tuning approach, and are the first to apply such prompt tuning to Graph Neural Networks. We contribute two new benchmarks for our new problem setting in human action recognition: (i) NTU RGB+D dataset for activity recognition, and (ii) SHREC-2017 dataset for hand gesture recognition. We find that POET consistently outperforms comprehensive benchmarks. Source code at https://github.com/humansensinglab/POET-continual-action-recognition.
* ECCV 2024 (Oral), webpage https://humansensinglab.github.io/POET-continual-action-recognition/
FW-Shapley: Real-time Estimation of Weighted Shapley Values
Mar 09, 2025Fair credit assignment is essential in various machine learning (ML) applications, and Shapley values have emerged as a valuable tool for this purpose. However, in critical ML applications such as data valuation and feature attribution, the uniform weighting of Shapley values across subset cardinalities leads to unintuitive credit assignments. To address this, weighted Shapley values were proposed as a generalization, allowing different weights for subsets with different cardinalities. Despite their advantages, similar to Shapley values, Weighted Shapley values suffer from exponential compute costs, making them impractical for high-dimensional datasets. To tackle this issue, we present two key contributions. Firstly, we provide a weighted least squares characterization of weighted Shapley values. Next, using this characterization, we propose Fast Weighted Shapley (FW-Shapley), an amortized framework for efficiently computing weighted Shapley values using a learned estimator. We further show that our estimator's training procedure is theoretically valid even though we do not use ground truth Weighted Shapley values during training. On the feature attribution task, we outperform the learned estimator FastSHAP by $27\%$ (on average) in terms of Inclusion AUC. For data valuation, we are much faster (14 times) while being comparable to the state-of-the-art KNN Shapley.