 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Audio-Visual Alignment for Generation
May 28, 2026Joint audio-video generation aims to synthesize temporally synchronized and semantically coherent visual-acoustic content. However, existing open-source methods mainly rely on either dual-tower designs with posterior alignment or fully unified tri-modal designs that mix textual context, audio and video in one shared space. The former weakens fine-grained audio-video co-evolution, while the latter couples semantic conditioning with low-level synchronization. To address these limitations, we propose NAVA, a Native Audio-Visual Alignment framework for joint audio-video generation. NAVA is built upon context-conditioned native audio-visual alignment: it first establishes audio-video correspondence in a dedicated interaction space, and then uses external context to condition the joint denoising process. Specifically, NAVA is instantiated with an Align-then-Fuse MMDiT architecture, which transitions from modality-aware audio-video alignment to modality-shared joint denoising. Furthermore, we introduce Timbre-in-Context Conditioning to associate reference timbre cues with corresponding speech spans to achieve controllable speech timbre. Experiments on Verse-Bench and Seed-TTS, together with a user study, demonstrate that NAVA achieves superior video quality, precise audio-visual synchronization, competitive audio quality, and stronger reference-timbre controllability using only 6.3B parameters.
ROSD: Reflective On-Policy Self-Distillation for Language Model Reasoning across Domains
May 27, 2026On-policy self-distillation (OPSD) improves the reasoning performance of large language models (LLMs) by providing dense token-level supervision for on-policy rollouts. However, existing OPSD methods often yield limited gains on in-domain reasoning and generalize poorly to out-of-domain problems. We identify two key causes: conditioning the self-teacher on a verified solution encourages imitation of training-domain reference trajectories rather than error-specific correction, and applying distillation to the full response can overwrite valid reasoning prefixes and reinforce overfitting. We propose Reflective On-policy Self-Distillation (ROSD), a framework that turns reference-solution imitation into targeted reasoning correction through reflection-guided, error-localized distillation. For each rollout, ROSD uses a self-reflector to extract a corrective idea and locate the first erroneous span. The corrective idea guides the self-teacher toward targeted supervision, while the localized error span restricts distillation to where correction is needed. This design corrects flawed reasoning while preserving valid prefixes. Experiments on multiple in-domain and out-of-domain reasoning benchmarks show that ROSD yields stronger in-domain reasoning performance overall and substantially better out-of-domain generalization than standard OPSD. Code is available at https://github.com/ZiqiZhao1/ROSD.
Eureka-Audio: Triggering Audio Intelligence in Compact Language Models
Feb 15, 2026We present Eureka-Audio, a compact yet high-performance audio language model that achieves competitive performance against models that are 4 to 18 times larger across a broad range of audio understanding benchmarks. Despite containing only 1.7B parameters, Eureka-Audio demonstrates strong performance on automatic speech recognition (ASR), audio understanding, and dense audio captioning, matching or surpassing multiple 7B to 30B audio and omni-modal baselines. The model adopts a unified end-to-end architecture composed of a lightweight language backbone, a Whisper-based audio encoder, and a sparsely activated Mixture-of-Experts (MoE) adapter that explicitly accounts for audio heterogeneity and alleviates cross-modal optimization conflicts under limited capacity. To further enhance paralinguistic reasoning, we introduce DataFlux, a closed loop audio instruction data synthesis and verification pipeline that constructs high quality, logically consistent supervision from raw audio. Extensive evaluations across ASR, knowledge reasoning, safety, instruction following, and paralinguistic benchmarks, demonstrate that Eureka-Audio achieves an efficient balance between computational cost and performance. These results establish Eureka Audio as a strong and practical baseline for lightweight audio understanding models.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
CORD: Bridging the Audio-Text Reasoning Gap via Weighted On-policy Cross-modal Distillation
Jan 23, 2026Large Audio Language Models (LALMs) have garnered significant research interest. Despite being built upon text-based large language models (LLMs), LALMs frequently exhibit a degradation in knowledge and reasoning capabilities. We hypothesize that this limitation stems from the failure of current training paradigms to effectively bridge the acoustic-semantic gap within the feature representation space. To address this challenge, we propose CORD, a unified alignment framework that performs online cross-modal self-distillation. Specifically, it aligns audio-conditioned reasoning with its text-conditioned counterpart within a unified model. Leveraging the text modality as an internal teacher, CORD performs multi-granularity alignment throughout the audio rollout process. At the token level, it employs on-policy reverse KL divergence with importance-aware weighting to prioritize early and semantically critical tokens. At the sequence level, CORD introduces a judge-based global reward to optimize complete reasoning trajectories via Group Relative Policy Optimization (GRPO). Empirical results across multiple benchmarks demonstrate that CORD consistently enhances audio-conditioned reasoning and substantially bridges the audio-text performance gap with only 80k synthetic training samples, validating the efficacy and data efficiency of our on-policy, multi-level cross-modal alignment approach.
MoE Adapter for Large Audio Language Models: Sparsity, Disentanglement, and Gradient-Conflict-Free
Jan 08, 2026Extending the input modality of Large Language Models~(LLMs) to the audio domain is essential for achieving comprehensive multimodal perception. However, it is well-known that acoustic information is intrinsically \textit{heterogeneous}, entangling attributes such as speech, music, and environmental context. Existing research is limited to a dense, parameter-shared adapter to model these diverse patterns, which induces \textit{gradient conflict} during optimization, as parameter updates required for distinct attributes contradict each other. To address this limitation, we introduce the \textit{\textbf{MoE-Adapter}}, a sparse Mixture-of-Experts~(MoE) architecture designed to decouple acoustic information. Specifically, it employs a dynamic gating mechanism that routes audio tokens to specialized experts capturing complementary feature subspaces while retaining shared experts for global context, thereby mitigating gradient conflicts and enabling fine-grained feature learning. Comprehensive experiments show that the MoE-Adapter achieves superior performance on both audio semantic and paralinguistic tasks, consistently outperforming dense linear baselines with comparable computational costs. Furthermore, we will release the related code and models to facilitate future research.
Pre-Training on Large-Scale Generated Docking Conformations with HelixDock to Unlock the Potential of Protein-ligand Structure Prediction Models
Oct 21, 2023Molecular docking, a pivotal computational tool for drug discovery, predicts the binding interactions between small molecules (ligands) and target proteins (receptors). Conventional physics-based docking tools, though widely used, face limitations in precision due to restricted conformational sampling and imprecise scoring functions. Recent endeavors have employed deep learning techniques to enhance docking accuracy, but their generalization remains a concern due to limited training data. Leveraging the success of extensive and diverse data in other domains, we introduce HelixDock, a novel approach for site-specific molecular docking. Hundreds of millions of binding poses are generated by traditional docking tools, encompassing diverse protein targets and small molecules. Our deep learning-based docking model, a SE(3)-equivariant network, is pre-trained with this large-scale dataset and then fine-tuned with a small number of precise receptor-ligand complex structures. Comparative analyses against physics-based and deep learning-based baseline methods highlight HelixDock's superiority, especially on challenging test sets. Our study elucidates the scaling laws of the pre-trained molecular docking models, showcasing consistent improvements with increased model parameters and pre-train data quantities. Harnessing the power of extensive and diverse generated data holds promise for advancing AI-driven drug discovery.
GEM-2: Next Generation Molecular Property Prediction Network with Many-body and Full-range Interaction Modeling
Aug 15, 2022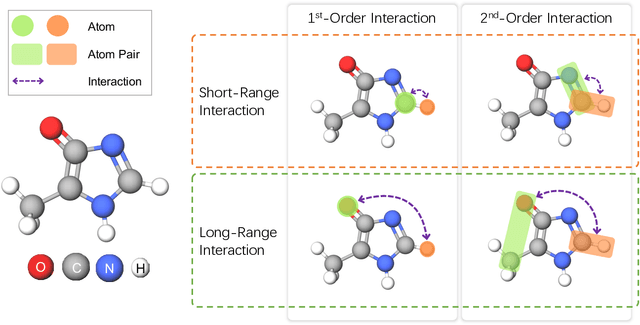
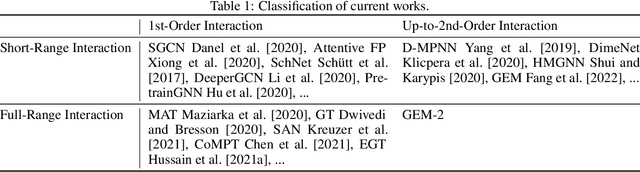
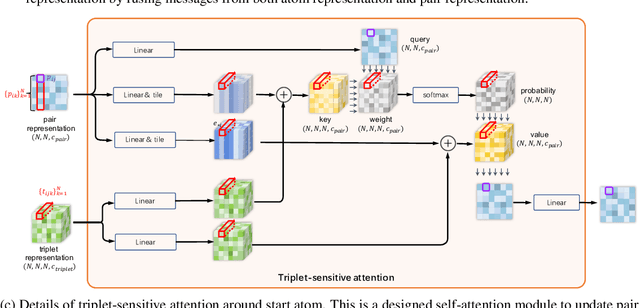
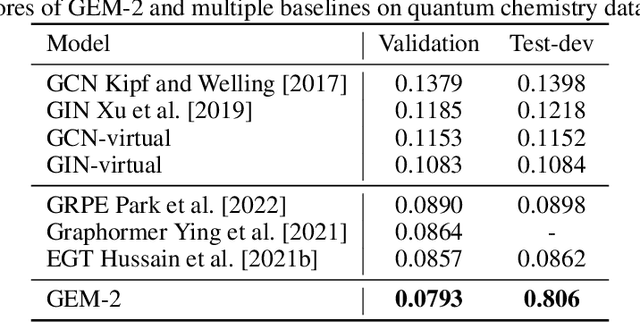
Molecular property prediction is a fundamental task in the drug and material industries. Physically, the properties of a molecule are determined by its own electronic structure, which can be exactly described by the Schr\"odinger equation. However, solving the Schr\"odinger equation for most molecules is extremely challenging due to long-range interactions in the behavior of a quantum many-body system. While deep learning methods have proven to be effective in molecular property prediction, we design a novel method, namely GEM-2, which comprehensively considers both the long-range and many-body interactions in molecules. GEM-2 consists of two interacted tracks: an atom-level track modeling both the local and global correlation between any two atoms, and a pair-level track modeling the correlation between all atom pairs, which embed information between any 3 or 4 atoms. Extensive experiments demonstrated the superiority of GEM-2 over multiple baseline methods in quantum chemistry and drug discovery tasks.
HelixFold-Single: MSA-free Protein Structure Prediction by Using Protein Language Model as an Alternative
Aug 09, 2022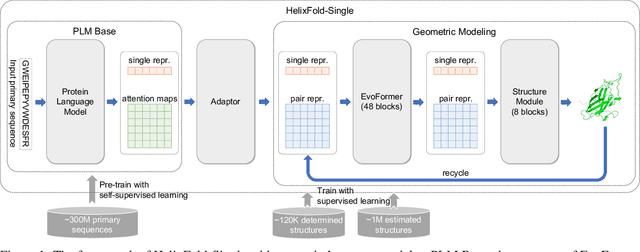

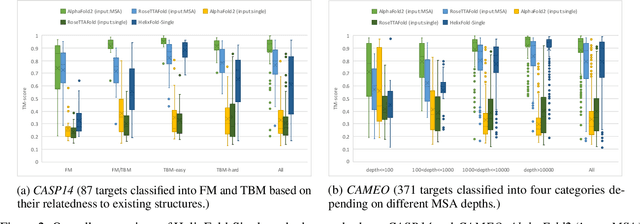
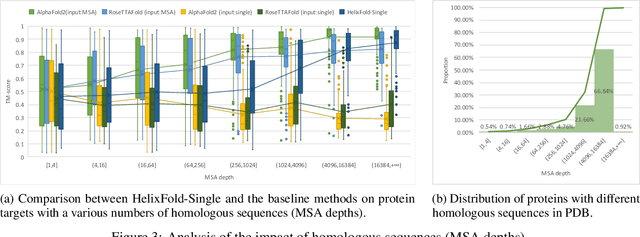
AI-based protein structure prediction pipelines, such as AlphaFold2, have achieved near-experimental accuracy. These advanced pipelines mainly rely on Multiple Sequence Alignments (MSAs) as inputs to learn the co-evolution information from the homologous sequences. Nonetheless, searching MSAs from protein databases is time-consuming, usually taking dozens of minutes. Consequently, we attempt to explore the limits of fast protein structure prediction by using only primary sequences of proteins. HelixFold-Single is proposed to combine a large-scale protein language model with the superior geometric learning capability of AlphaFold2. Our proposed method, HelixFold-Single, first pre-trains a large-scale protein language model (PLM) with thousands of millions of primary sequences utilizing the self-supervised learning paradigm, which will be used as an alternative to MSAs for learning the co-evolution information. Then, by combining the pre-trained PLM and the essential components of AlphaFold2, we obtain an end-to-end differentiable model to predict the 3D coordinates of atoms from only the primary sequence. HelixFold-Single is validated in datasets CASP14 and CAMEO, achieving competitive accuracy with the MSA-based methods on the targets with large homologous families. Furthermore, HelixFold-Single consumes much less time than the mainstream pipelines for protein structure prediction, demonstrating its potential in tasks requiring many predictions. The code of HelixFold-Single is available at https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold-single, and we also provide stable web services on https://paddlehelix.baidu.com/app/drug/protein-single/forecast.