 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACTIC: Translation Agents with Cognitive-Theoretic Interactive Collaboration
Jun 11, 2025

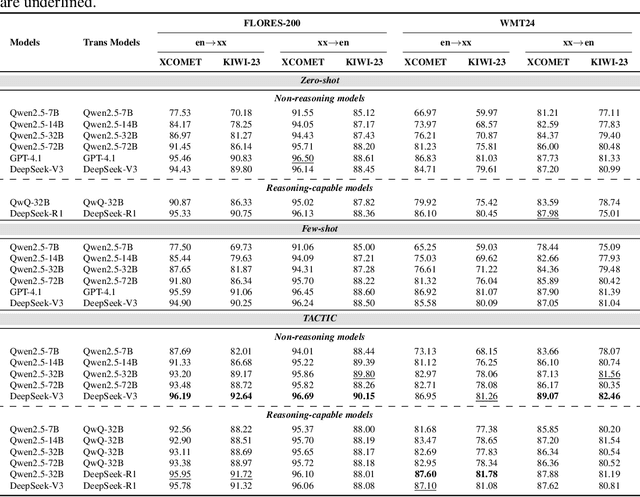

Machine translation has long been a central task in natural language processing. With the rapid advancement of large language models (LLMs), there has been remarkable progress in translation quality. However, fully realizing the translation potential of LLMs remains an open challenge. Recent studies have explored multi-agent systems to decompose complex translation tasks into collaborative subtasks, showing initial promise in enhancing translation quality through agent cooperation and specialization. Nevertheless, existing multi-agent translation frameworks largely neglect foundational insights from cognitive translation studies. These insights emphasize how human translators employ different cognitive strategies, such as balancing literal and free translation, refining expressions based on context, and iteratively evaluating outputs. To address this limitation, we propose a cognitively informed multi-agent framework called TACTIC, which stands for T ranslation A gents with Cognitive- T heoretic Interactive Collaboration. The framework comprises six functionally distinct agents that mirror key cognitive processes observed in human translation behavior. These include agents for drafting, refinement, evaluation, scoring, context reasoning, and external knowledge gathering. By simulating an interactive and theory-grounded translation workflow, TACTIC effectively leverages the full capacity of LLMs for high-quality translation. Experimental results on diverse language pairs from the FLORES-200 and WMT24 benchmarks show that our method consistently achieves state-of-the-art performance. Using DeepSeek-V3 as the base model, TACTIC surpasses GPT-4.1 by an average of +0.6 XCOMET and +1.18 COMETKIWI-23. Compared to DeepSeek-R1, it further improves by +0.84 XCOMET and +2.99 COMETKIWI-23. Code is available at https://github.com/weiyali126/TACTIC.
Gnothi Seauton: Empowering Faithful Self-Interpretability in Black-Box Models
Oct 29, 2024



The debate between self-interpretable models and post-hoc explanations for black-box models is central to Explainable AI (XAI). Self-interpretable models, such as concept-based networks, offer insights by connecting decisions to human-understandable concepts but often struggle with performance and scalability. Conversely, post-hoc methods like Shapley values, while theoretically robust, are computationally expensive and resource-intensive. To bridge the gap between these two lines of research, we propose a novel method that combines their strengths, providing theoretically guaranteed self-interpretability for black-box models without compromising prediction accuracy. Specifically, we introduce a parameter-efficient pipeline, *AutoGnothi*, which integrates a small side network into the black-box model, allowing it to generate Shapley value explanations without changing the original network parameters. This side-tuning approach significantly reduces memory, training, and inference costs, outperforming traditional parameter-efficient methods, where full fine-tuning serves as the optimal baseline. *AutoGnothi* enables the black-box model to predict and explain its predictions with minimal overhead. Extensive experiments show that *AutoGnothi* offers accurate explanations for both vision and language tasks, delivering superior computational efficiency with comparable interpretability.
DRUPI: Dataset Reduction Using Privileged Information
Oct 02, 2024



Dataset reduction (DR) seeks to select or distill samples from large datasets into smaller subsets while preserving performance on target tasks. Existing methods primarily focus on pruning or synthesizing data in the same format as the original dataset, typically the input data and corresponding labels. However, in DR settings, we find it is possible to synthesize more information beyond the data-label pair as an additional learning target to facilitate model training. In this paper, we introduce Dataset Reduction Using Privileged Information (DRUPI), which enriches DR by synthesizing privileged information alongside the reduced dataset. This privileged information can take the form of feature labels or attention labels, providing auxiliary supervision to improve model learning. Our findings reveal that effective feature labels must balance between being overly discriminative and excessively diverse, with a moderate level proving optimal for improving the reduced dataset's efficacy. Extensive experiments on ImageNet, CIFAR-10/100, and Tiny ImageNet demonstrate that DRUPI integrates seamlessly with existing dataset reduction methods, offering significant performance gains.