 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
May 28, 2026Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffering from diminishing transfer ratio -- the fraction of FM improvement captured by the VM -- as a single scalar cannot convey the rich intermediate knowledge that larger FMs learn. To address this bottleneck, we propose LoopFM (Learning frOm HistOrical ReP*resentations of FM), a framework that opens a high-bandwidth transfer channel by structuring FM intermediate embeddings as input features (e.g., user history sequence) for downstream VMs, without requiring real-time FM inference at serving and architectural coupling between FM and VM. We provide a theoretical framework for LoopFM with a gain decomposition and transfer-ratio analysis. On three public benchmarks, LoopFM demonstrates strong AUC improvements (e.g., 6\%+ on TaobaoAd) and complementary knowledge transfer capability with KD. On industrial-scale systems (billions of examples, trillion-parameter FMs), LoopFM approximately doubles the knowledge transfer ratio on top of KD, delivering a +0.5\% conversion improvement in Y1H1, and a +1.03\% and +1.22\% conversion improvement from two individual launches respectively in Y1H2.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
AutoML for Large Capacity Modeling of Meta's Ranking Systems
Nov 16, 2023



Web-scale ranking systems at Meta serving billions of users is complex. Improving ranking models is essential but engineering heavy. Automated Machine Learning (AutoML) can release engineers from labor intensive work of tuning ranking models; however, it is unknown if AutoML is efficient enough to meet tight production timeline in real-world and, at the same time, bring additional improvements to the strong baselines. Moreover, to achieve higher ranking performance, there is an ever-increasing demand to scale up ranking models to even larger capacity, which imposes more challenges on the efficiency. The large scale of models and tight production schedule requires AutoML to outperform human baselines by only using a small number of model evaluation trials (around 100). We presents a sampling-based AutoML method, focusing on neural architecture search and hyperparameter optimization, addressing these challenges in Meta-scale production when building large capacity models. Our approach efficiently handles large-scale data demands. It leverages a lightweight predictor-based searcher and reinforcement learning to explore vast search spaces, significantly reducing the number of model evaluations. Through experiments in large capacity modeling for CTR and CVR applications, we show that our method achieves outstanding Return on Investment (ROI) versus human tuned baselines, with up to 0.09% Normalized Entropy (NE) loss reduction or $25\%$ Query per Second (QPS) increase by only sampling one hundred models on average from a curated search space. The proposed AutoML method has already made real-world impact where a discovered Instagram CTR model with up to -0.36% NE gain (over existing production baseline) was selected for large-scale online A/B test and show statistically significant gain. These production results proved AutoML efficacy and accelerated its adoption in ranking systems at Meta.
Efficient Nonmyopic Bayesian Optimization via One-Shot Multi-Step Trees
Jun 29, 2020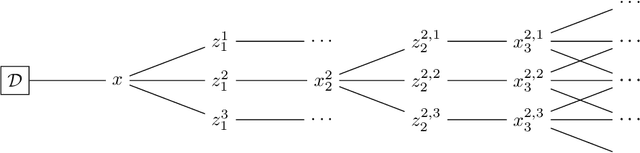

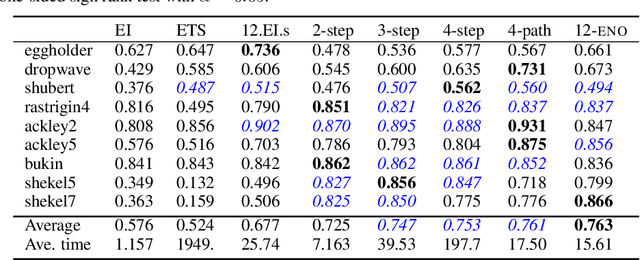
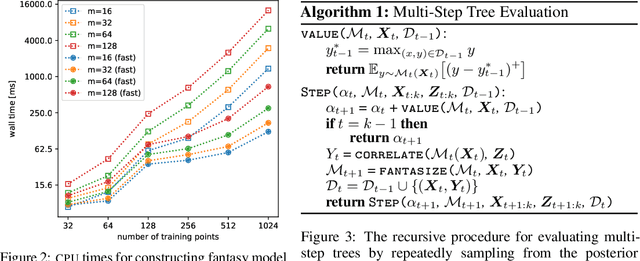
Bayesian optimization is a sequential decision making framework for optimizing expensive-to-evaluate black-box functions. Computing a full lookahead policy amounts to solving a highly intractable stochastic dynamic program. Myopic approaches, such as expected improvement, are often adopted in practice, but they ignore the long-term impact of the immediate decision. Existing nonmyopic approaches are mostly heuristic and/or computationally expensive. In this paper, we provide the first efficient implementation of general multi-step lookahead Bayesian optimization, formulated as a sequence of nested optimization problems within a multi-step scenario tree. Instead of solving these problems in a nested way, we equivalently optimize all decision variables in the full tree jointly, in a ``one-shot'' fashion. Combining this with an efficient method for implementing multi-step Gaussian process ``fantasization,'' we demonstrate that multi-step expected improvement is computationally tractable and exhibits performance superior to existing methods on a wide range of benchmarks.
Nearly Optimal Risk Bounds for Kernel K-Means
Mar 09, 2020In this paper, we study the statistical properties of the kernel $k$-means and obtain a nearly optimal excess risk bound, substantially improving the state-of-art bounds in the existing clustering risk analyses. We further analyze the statistical effect of computational approximations of the Nystr\"{o}m kernel $k$-means, and demonstrate that it achieves the same statistical accuracy as the exact kernel $k$-means considering only $\sqrt{nk}$ Nystr\"{o}m landmark points. To the best of our knowledge, such sharp excess risk bounds for kernel (or approximate kernel) $k$-means have never been seen before.
Efficient nonmyopic Bayesian optimization and quadrature
Oct 16, 2019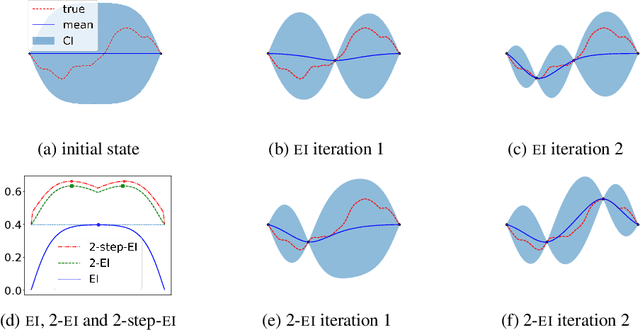
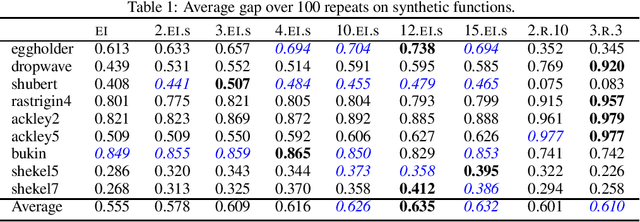
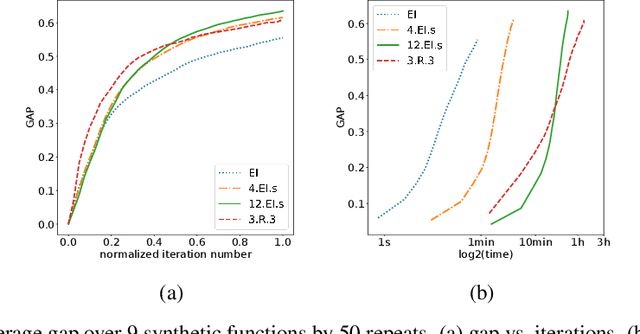
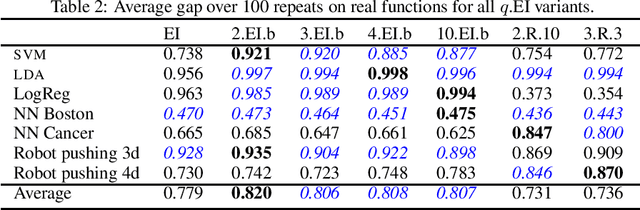
Finite-horizon sequential decision problems arise naturally in many machine learning contexts, including Bayesian optimization and Bayesian quadrature. Computing the optimal policy for such problems requires solving Bellman equations, which are generally intractable. Most existing work resorts to myopic approximations by limiting the decision horizon to only a single time-step, which can perform poorly at balancing exploration and exploitation. We propose a general framework for efficient, nonmyopic approximation of the optimal policy by drawing a connection between the optimal adaptive policy and its non-adaptive counterpart. Our proposal is to compute an optimal batch of points, then select a single point from within this batch to evaluate. We realize this idea for both Bayesian optimization and Bayesian quadrature and demonstrate that our proposed method significantly outperforms common myopic alternatives on a variety of tasks.
D-VAE: A Variational Autoencoder for Directed Acyclic Graphs
May 30, 2019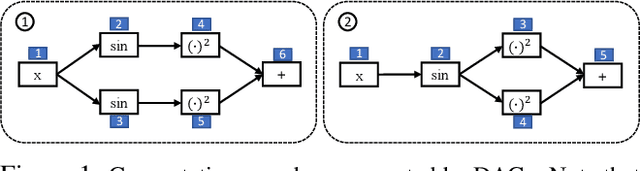
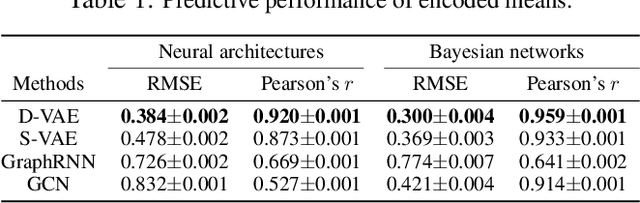
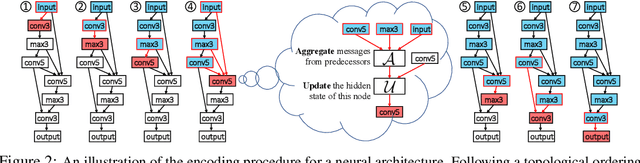
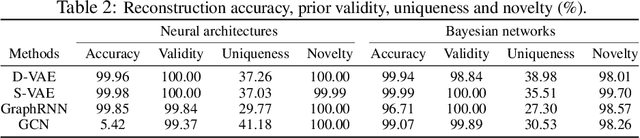
Graph structured data are abundant in the real world. Among different graph types, directed acyclic graphs (DAGs) are of particular interest to machine learning researchers, as many machine learning models are realized as computations on DAGs, including neural networks and Bayesian networks. In this paper, we study deep generative models for DAGs, and propose a novel DAG variational autoencoder (D-VAE). To encode DAGs into the latent space, we leverage graph neural networks. We propose an asynchronous message passing scheme that allows encoding the computations on DAGs, rather than using existing simultaneous message passing schemes to encode local graph structures. We demonstrate the effectiveness of our proposed D-VAE through two tasks: neural architecture search and Bayesian network structure learning. Experiments show that our model not only generates novel and valid DAGs, but also produces a smooth latent space that facilitates searching for DAGs with better performance through Bayesian optimization.
Efficient nonmyopic active search with applications in drug and materials discovery
Nov 23, 2018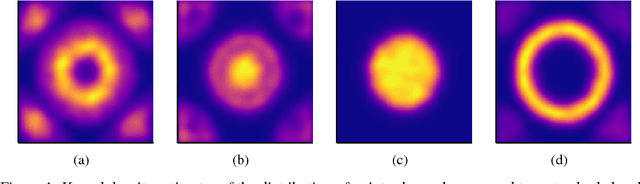


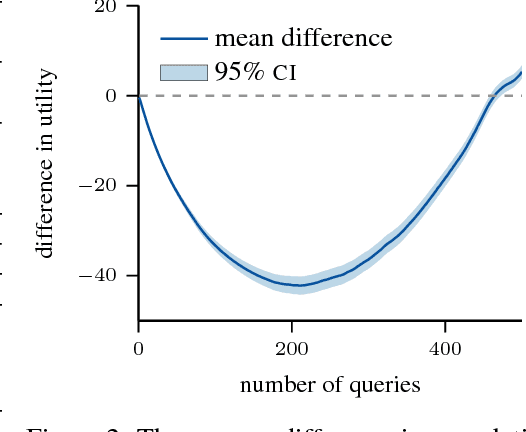
Active search is a learning paradigm for actively identifying as many members of a given class as possible. A critical target scenario is high-throughput screening for scientific discovery, such as drug or materials discovery. In this paper, we approach this problem in Bayesian decision framework. We first derive the Bayesian optimal policy under a natural utility, and establish a theoretical hardness of active search, proving that the optimal policy can not be approximated for any constant ratio. We also study the batch setting for the first time, where a batch of $b>1$ points can be queried at each iteration. We give an asymptotic lower bound, linear in batch size, on the adaptivity gap: how much we could lose if we query $b$ points at a time for $t$ iterations, instead of one point at a time for $bt$ iterations. We then introduce a novel approach to nonmyopic approximations of the optimal policy that admits efficient computation. Our proposed policy can automatically trade off exploration and exploitation, without relying on any tuning parameters. We also generalize our policy to batch setting, and propose two approaches to tackle the combinatorial search challenge. We evaluate our proposed policies on a large database of drug discovery and materials science. Results demonstrate the superior performance of our proposed policy in both sequential and batch setting; the nonmyopic behavior is also illustrated in various aspects.