 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinGRAV: Learning a Generative Radiance Volume from a Single Natural Scene
Oct 08, 2022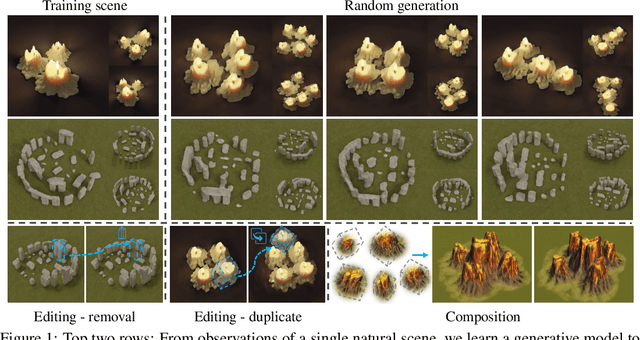
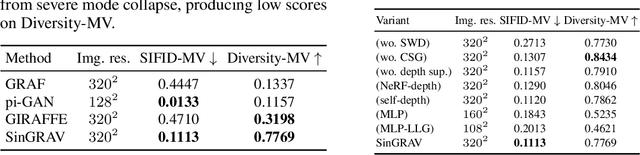
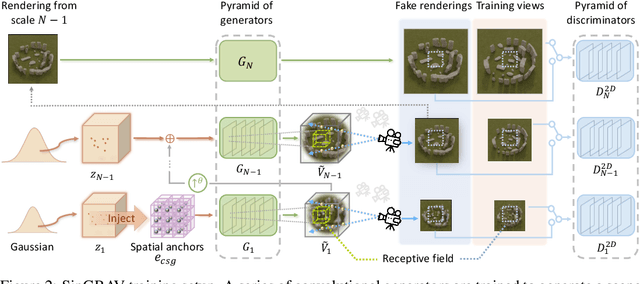
We present a 3D generative model for general natural scenes. Lacking necessary volumes of 3D data characterizing the target scene, we propose to learn from a single scene. Our key insight is that a natural scene often contains multiple constituents whose geometry, texture, and spatial arrangements follow some clear patterns, but still exhibit rich variations over different regions within the same scene. This suggests localizing the learning of a generative model on substantial local regions. Hence, we exploit a multi-scale convolutional network, which possesses the spatial locality bias in nature, to learn from the statistics of local regions at multiple scales within a single scene. In contrast to existing methods, our learning setup bypasses the need to collect data from many homogeneous 3D scenes for learning common features. We coin our method SinGRAV, for learning a Generative RAdiance Volume from a Single natural scene. We demonstrate the ability of SinGRAV in generating plausible and diverse variations from a single scene, the merits of SinGRAV over state-of-the-art generative neural scene methods, as well as the versatility of SinGRAV by its use in a variety of applications, spanning 3D scene editing, composition, and animation. Code and data will be released to facilitate further research.
Rhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings
Oct 05, 2022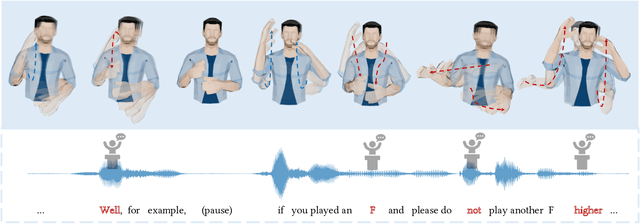
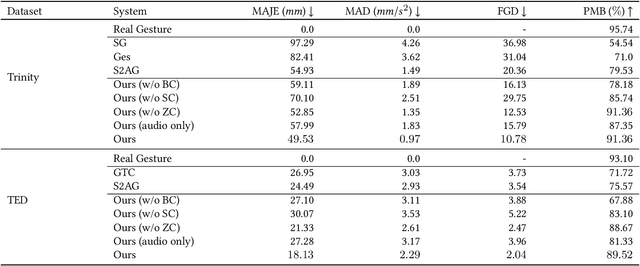
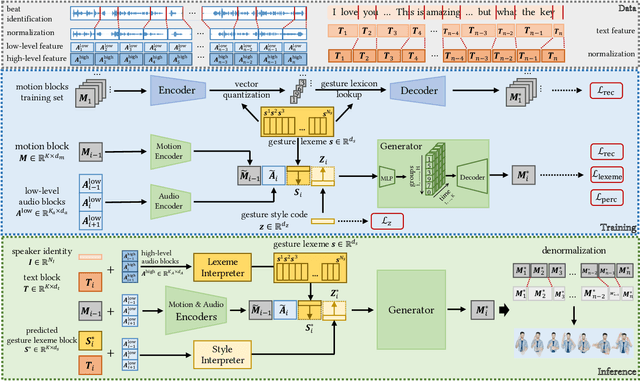
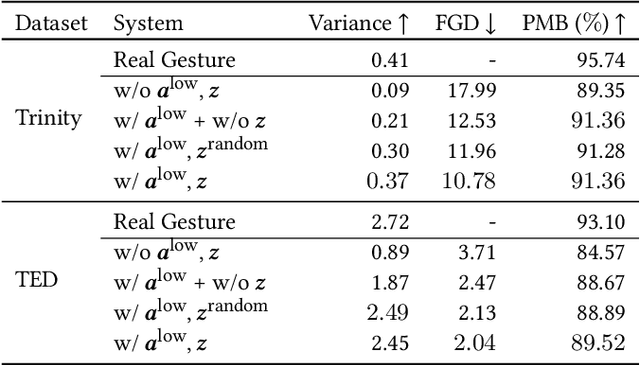
Automatic synthesis of realistic co-speech gestures is an increasingly important yet challenging task in artificial embodied agent creation. Previous systems mainly focus on generating gestures in an end-to-end manner, which leads to difficulties in mining the clear rhythm and semantics due to the complex yet subtle harmony between speech and gestures. We present a novel co-speech gesture synthesis method that achieves convincing results both on the rhythm and semantics. For the rhythm, our system contains a robust rhythm-based segmentation pipeline to ensure the temporal coherence between the vocalization and gestures explicitly. For the gesture semantics, we devise a mechanism to effectively disentangle both low- and high-level neural embeddings of speech and motion based on linguistic theory. The high-level embedding corresponds to semantics, while the low-level embedding relates to subtle variations. Lastly, we build correspondence between the hierarchical embeddings of the speech and the motion, resulting in rhythm- and semantics-aware gesture synthesis. Evaluations with existing objective metrics, a newly proposed rhythmic metric, and human feedback show that our method outperforms state-of-the-art systems by a clear margin.
Neural Novel Actor: Learning a Generalized Animatable Neural Representation for Human Actors
Aug 25, 2022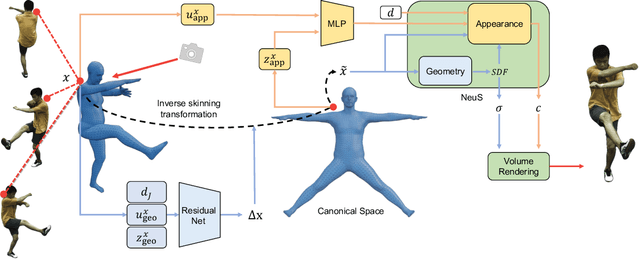

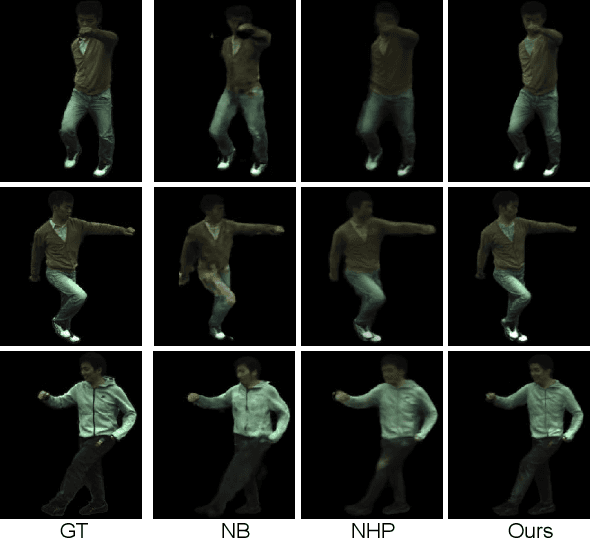

We propose a new method for learning a generalized animatable neural human representation from a sparse set of multi-view imagery of multiple persons. The learned representation can be used to synthesize novel view images of an arbitrary person from a sparse set of cameras, and further animate them with the user's pose control. While existing methods can either generalize to new persons or synthesize animations with user control, none of them can achieve both at the same time. We attribute this accomplishment to the employment of a 3D proxy for a shared multi-person human model, and further the warping of the spaces of different poses to a shared canonical pose space, in which we learn a neural field and predict the person- and pose-dependent deformations, as well as appearance with the features extracted from input images. To cope with the complexity of the large variations in body shapes, poses, and clothing deformations, we design our neural human model with disentangled geometry and appearance. Furthermore, we utilize the image features both at the spatial point and on the surface points of the 3D proxy for predicting person- and pose-dependent properties. Experiments show that our method significantly outperforms the state-of-the-arts on both tasks. The video and code are available at https://talegqz.github.io/neural_novel_actor.
Visual Localization via Few-Shot Scene Region Classification
Aug 14, 2022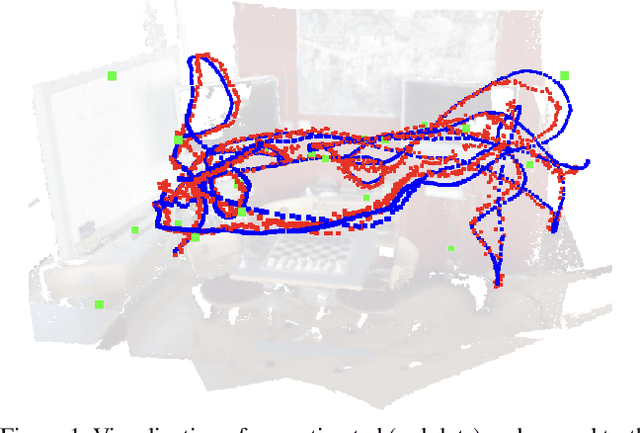
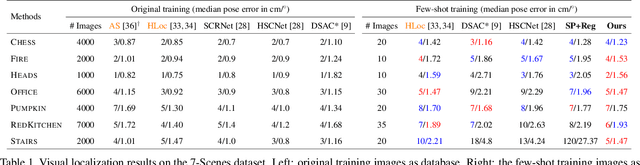

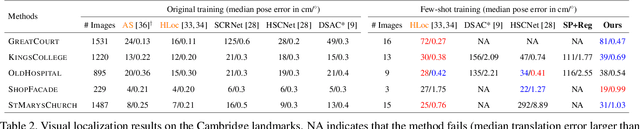
Visual (re)localization addresses the problem of estimating the 6-DoF (Degree of Freedom) camera pose of a query image captured in a known scene, which is a key building block of many computer vision and robotics applications. Recent advances in structure-based localization solve this problem by memorizing the mapping from image pixels to scene coordinates with neural networks to build 2D-3D correspondences for camera pose optimization. However, such memorization requires training by amounts of posed images in each scene, which is heavy and inefficient. On the contrary, few-shot images are usually sufficient to cover the main regions of a scene for a human operator to perform visual localization. In this paper, we propose a scene region classification approach to achieve fast and effective scene memorization with few-shot images. Our insight is leveraging a) pre-learned feature extractor, b) scene region classifier, and c) meta-learning strategy to accelerate training while mitigating overfitting. We evaluate our method on both indoor and outdoor benchmarks. The experiments validate the effectiveness of our method in the few-shot setting, and the training time is significantly reduced to only a few minutes. Code available at: \url{https://github.com/siyandong/SRC}
Multi-Robot Active Mapping via Neural Bipartite Graph Matching
Apr 01, 2022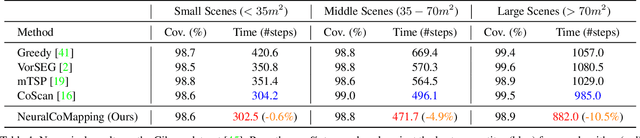
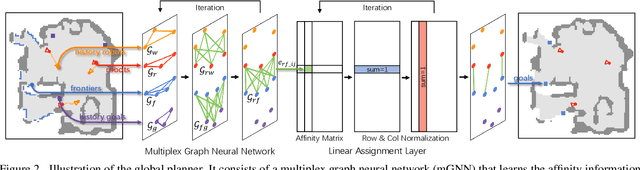
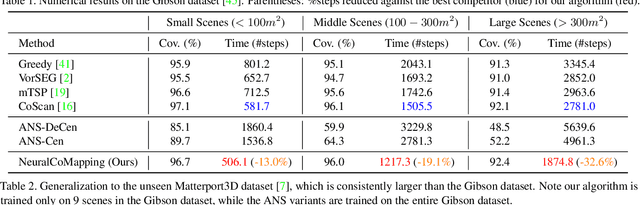
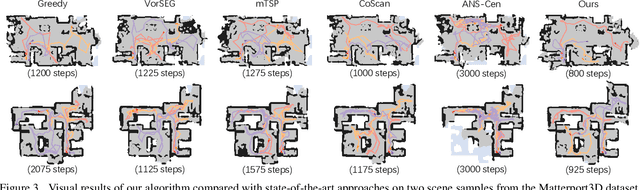
We study the problem of multi-robot active mapping, which aims for complete scene map construction in minimum time steps. The key to this problem lies in the goal position estimation to enable more efficient robot movements. Previous approaches either choose the frontier as the goal position via a myopic solution that hinders the time efficiency, or maximize the long-term value via reinforcement learning to directly regress the goal position, but does not guarantee the complete map construction. In this paper, we propose a novel algorithm, namely NeuralCoMapping, which takes advantage of both approaches. We reduce the problem to bipartite graph matching, which establishes the node correspondences between two graphs, denoting robots and frontiers. We introduce a multiplex graph neural network (mGNN) that learns the neural distance to fill the affinity matrix for more effective graph matching. We optimize the mGNN with a differentiable linear assignment layer by maximizing the long-term values that favor time efficiency and map completeness via reinforcement learning. We compare our algorithm with several state-of-the-art multi-robot active mapping approaches and adapted reinforcement-learning baselines. Experimental results demonstrate the superior performance and exceptional generalization ability of our algorithm on various indoor scenes and unseen number of robots, when only trained with 9 indoor scenes.
FisherMatch: Semi-Supervised Rotation Regression via Entropy-based Filtering
Mar 29, 2022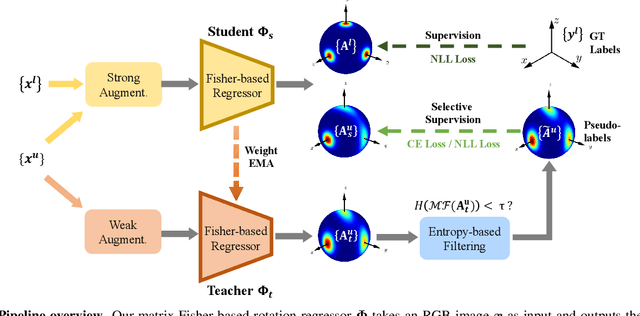
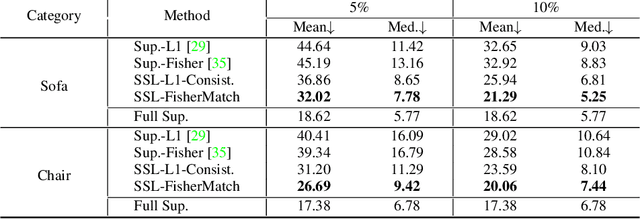
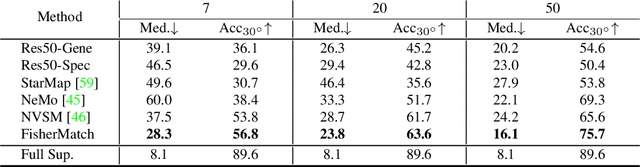
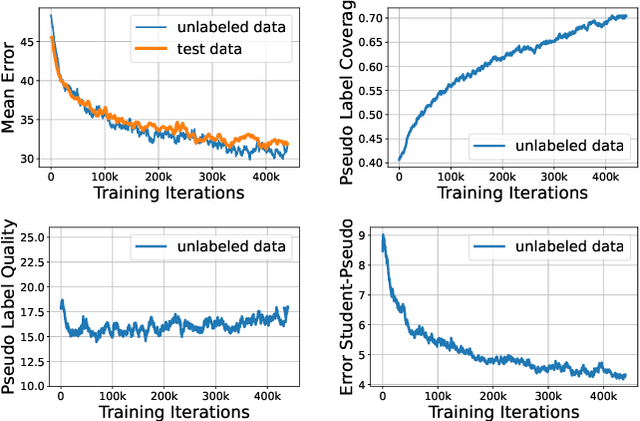
Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. Recent works achieve good performance relying on a large amount of expensive-to-obtain labeled data. To reduce the amount of supervision, we for the first time propose a general framework, FisherMatch, for semi-supervised rotation regression, without assuming any domain-specific knowledge or paired data. Inspired by the popular semi-supervised approach, FixMatch, we propose to leverage pseudo label filtering to facilitate the information flow from labeled data to unlabeled data in a teacher-student mutual learning framework. However, incorporating the pseudo label filtering mechanism into semi-supervised rotation regression is highly non-trivial, mainly due to the lack of a reliable confidence measure for rotation prediction. In this work, we propose to leverage matrix Fisher distribution to build a probabilistic model of rotation and devise a matrix Fisher-based regressor for jointly predicting rotation along with its prediction uncertainty. We then propose to use the entropy of the predicted distribution as a confidence measure, which enables us to perform pseudo label filtering for rotation regression. For supervising such distribution-like pseudo labels, we further investigate the problem of how to enforce loss between two matrix Fisher distributions. Our extensive experiments show that our method can work well even under very low labeled data ratios on different benchmarks, achieving significant and consistent performance improvement over supervised learning and other semi-supervised learning baselines. Our project page is at https://yd-yin.github.io/FisherMatch.
Self-Conditioned Generative Adversarial Networks for Image Editing
Feb 08, 2022Generative Adversarial Networks (GANs) are susceptible to bias, learned from either the unbalanced data, or through mode collapse. The networks focus on the core of the data distribution, leaving the tails - or the edges of the distribution - behind. We argue that this bias is responsible not only for fairness concerns, but that it plays a key role in the collapse of latent-traversal editing methods when deviating away from the distribution's core. Building on this observation, we outline a method for mitigating generative bias through a self-conditioning process, where distances in the latent-space of a pre-trained generator are used to provide initial labels for the data. By fine-tuning the generator on a re-sampled distribution drawn from these self-labeled data, we force the generator to better contend with rare semantic attributes and enable more realistic generation of these properties. We compare our models to a wide range of latent editing methods, and show that by alleviating the bias they achieve finer semantic control and better identity preservation through a wider range of transformations. Our code and models will be available at https://github.com/yzliu567/sc-gan
Projective Manifold Gradient Layer for Deep Rotation Regression
Oct 22, 2021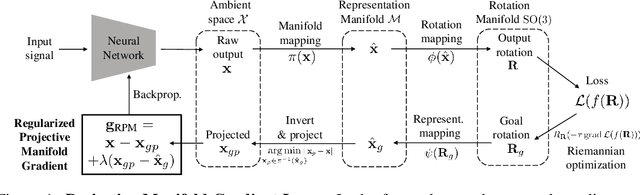
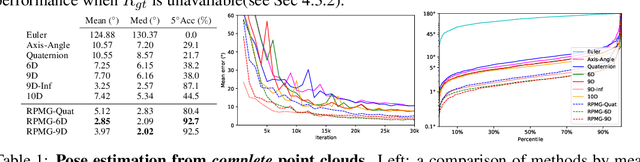
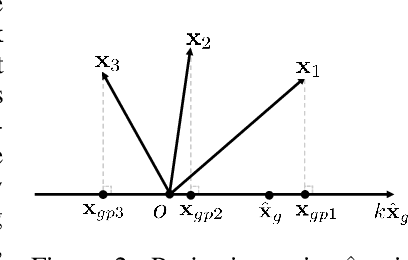
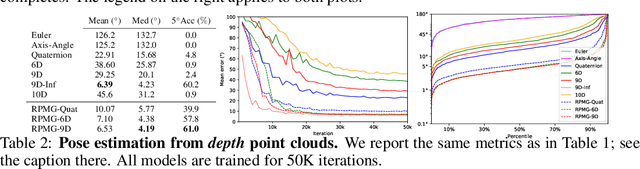
Regressing rotations on SO(3) manifold using deep neural networks is an important yet unsolved problem. The gap between Euclidean network output space and the non-Euclidean SO(3) manifold imposes a severe challenge for neural network learning in both forward and backward passes. While several works have proposed different regression-friendly rotation representations, very few works have been devoted to improving the gradient backpropagating in the backward pass. In this paper, we propose a manifold-aware gradient that directly backpropagates into deep network weights. Leveraging the Riemannian gradient and a novel projective gradient, our proposed regularized projective manifold gradient (RPMG) helps networks achieve new state-of-the-art performance in a variety of rotation estimation tasks. The proposed gradient layer can also be applied to other smooth manifolds such as the unit sphere.
Unsupervised Co-part Segmentation through Assembly
Jun 10, 2021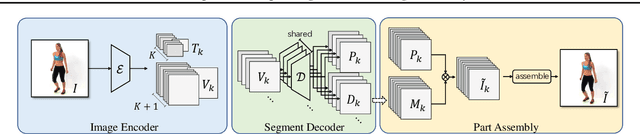
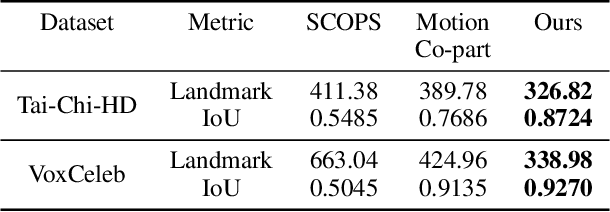
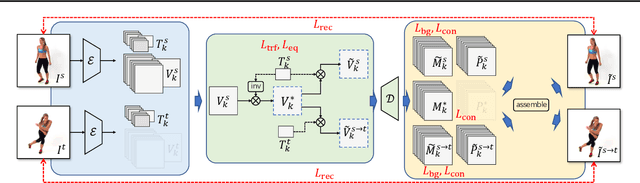
Co-part segmentation is an important problem in computer vision for its rich applications. We propose an unsupervised learning approach for co-part segmentation from images. For the training stage, we leverage motion information embedded in videos and explicitly extract latent representations to segment meaningful object parts. More importantly, we introduce a dual procedure of part-assembly to form a closed loop with part-segmentation, enabling an effective self-supervision. We demonstrate the effectiveness of our approach with a host of extensive experiments, ranging from human bodies, hands, quadruped, and robot arms. We show that our approach can achieve meaningful and compact part segmentation, outperforming state-of-the-art approaches on diverse benchmarks.
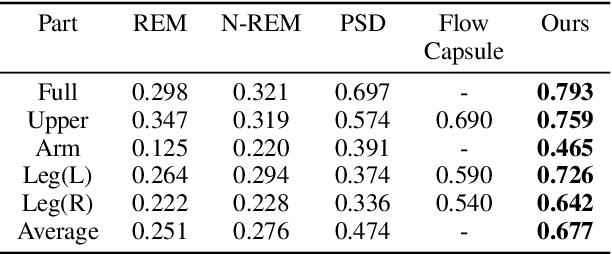
MoCo-Flow: Neural Motion Consensus Flow for Dynamic Humans in Stationary Monocular Cameras
Jun 08, 2021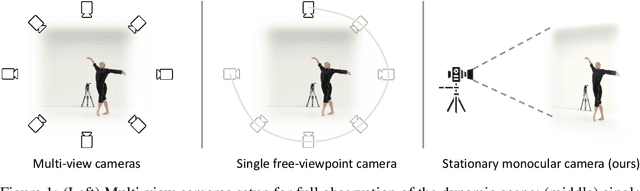

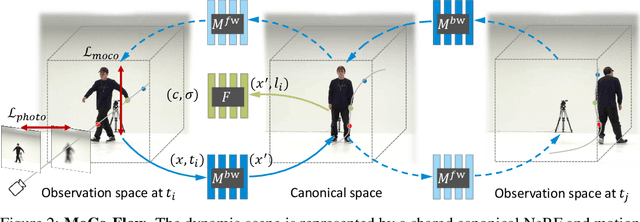

Synthesizing novel views of dynamic humans from stationary monocular cameras is a popular scenario. This is particularly attractive as it does not require static scenes, controlled environments, or specialized hardware. In contrast to techniques that exploit multi-view observations to constrain the modeling, given a single fixed viewpoint only, the problem of modeling the dynamic scene is significantly more under-constrained and ill-posed. In this paper, we introduce Neural Motion Consensus Flow (MoCo-Flow), a representation that models the dynamic scene using a 4D continuous time-variant function. The proposed representation is learned by an optimization which models a dynamic scene that minimizes the error of rendering all observation images. At the heart of our work lies a novel optimization formulation, which is constrained by a motion consensus regularization on the motion flow. We extensively evaluate MoCo-Flow on several datasets that contain human motions of varying complexity, and compare, both qualitatively and quantitatively, to several baseline methods and variants of our methods. Pretrained model, code, and data will be released for research purposes upon paper acceptance.