 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputationally-efficient Graph Modeling with Refined Graph Random Features
Oct 09, 2025We propose refined GRFs (GRFs++), a new class of Graph Random Features (GRFs) for efficient and accurate computations involving kernels defined on the nodes of a graph. GRFs++ resolve some of the long-standing limitations of regular GRFs, including difficulty modeling relationships between more distant nodes. They reduce dependence on sampling long graph random walks via a novel walk-stitching technique, concatenating several shorter walks without breaking unbiasedness. By applying these techniques, GRFs++ inherit the approximation quality provided by longer walks but with greater efficiency, trading sequential, inefficient sampling of a long walk for parallel computation of short walks and matrix-matrix multiplication. Furthermore, GRFs++ extend the simplistic GRFs walk termination mechanism (Bernoulli schemes with fixed halting probabilities) to a broader class of strategies, applying general distributions on the walks' lengths. This improves the approximation accuracy of graph kernels, without incurring extra computational cost. We provide empirical evaluations to showcase all our claims and complement our results with theoretical analysis.
Wavelet-Induced Rotary Encodings: RoPE Meets Graphs
Sep 26, 2025We introduce WIRE: Wavelet-Induced Rotary Encodings. WIRE extends Rotary Position Encodings (RoPE), a popular algorithm in LLMs and ViTs, to graph-structured data. We demonstrate that WIRE is more general than RoPE, recovering the latter in the special case of grid graphs. WIRE also enjoys a host of desirable theoretical properties, including equivariance under node ordering permutation, compatibility with linear attention, and (under select assumptions) asymptotic dependence on graph resistive distance. We test WIRE on a range of synthetic and real-world tasks, including identifying monochromatic subgraphs, semantic segmentation of point clouds, and more standard graph benchmarks. We find it to be effective in settings where the underlying graph structure is important.
Graph Random Features for Scalable Gaussian Processes
Sep 03, 2025



We study the application of graph random features (GRFs) - a recently introduced stochastic estimator of graph node kernels - to scalable Gaussian processes on discrete input spaces. We prove that (under mild assumptions) Bayesian inference with GRFs enjoys $O(N^{3/2})$ time complexity with respect to the number of nodes $N$, compared to $O(N^3)$ for exact kernels. Substantial wall-clock speedups and memory savings unlock Bayesian optimisation on graphs with over $10^6$ nodes on a single computer chip, whilst preserving competitive performance.
Distributional Training Data Attribution
Jun 15, 2025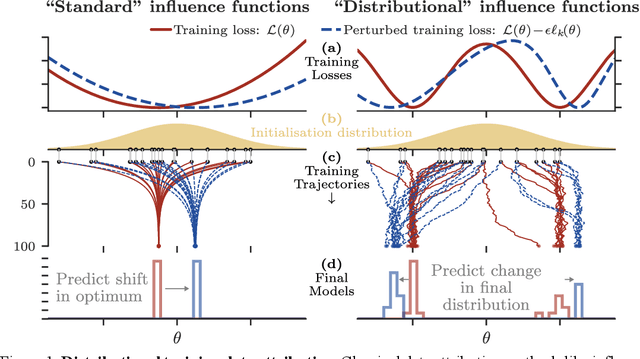
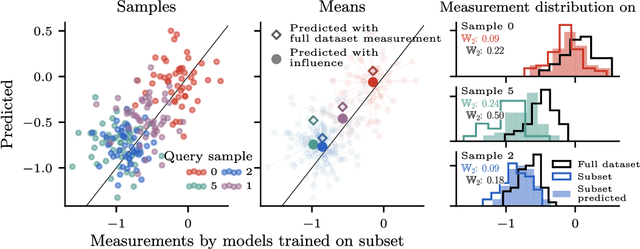
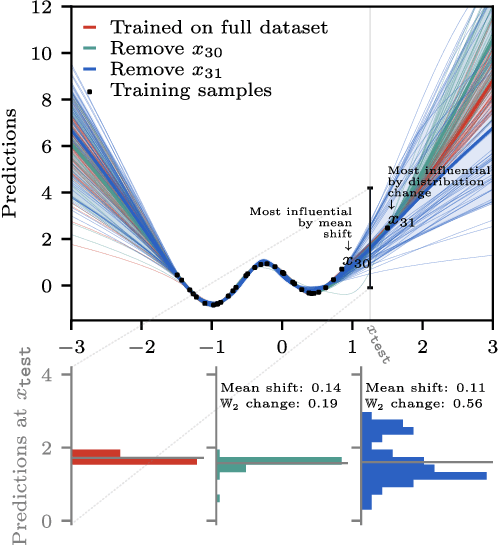
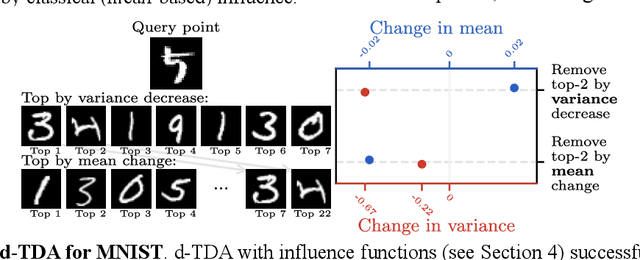
Randomness is an unavoidable part of training deep learning models, yet something that traditional training data attribution algorithms fail to rigorously account for. They ignore the fact that, due to stochasticity in the initialisation and batching, training on the same dataset can yield different models. In this paper, we address this shortcoming through introducing distributional training data attribution (d-TDA), the goal of which is to predict how the distribution of model outputs (over training runs) depends upon the dataset. We demonstrate the practical significance of d-TDA in experiments, e.g. by identifying training examples that drastically change the distribution of some target measurement without necessarily changing the mean. Intriguingly, we also find that influence functions (IFs), a popular but poorly-understood data attribution tool, emerge naturally from our distributional framework as the limit to unrolled differentiation; without requiring restrictive convexity assumptions. This provides a new mathematical motivation for their efficacy in deep learning, and helps to characterise their limitations.
Learning the RoPEs: Better 2D and 3D Position Encodings with STRING
Feb 04, 2025
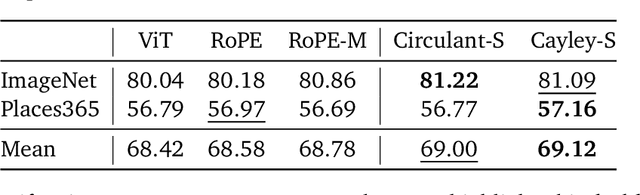
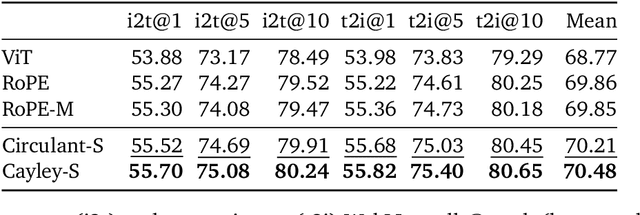

We introduce STRING: Separable Translationally Invariant Position Encodings. STRING extends Rotary Position Encodings, a recently proposed and widely used algorithm in large language models, via a unifying theoretical framework. Importantly, STRING still provides exact translation invariance, including token coordinates of arbitrary dimensionality, whilst maintaining a low computational footprint. These properties are especially important in robotics, where efficient 3D token representation is key. We integrate STRING into Vision Transformers with RGB(-D) inputs (color plus optional depth), showing substantial gains, e.g. in open-vocabulary object detection and for robotics controllers. We complement our experiments with a rigorous mathematical analysis, proving the universality of our methods.
Optimal Time Complexity Algorithms for Computing General Random Walk Graph Kernels on Sparse Graphs
Oct 15, 2024We present the first linear time complexity randomized algorithms for unbiased approximation of the celebrated family of general random walk kernels (RWKs) for sparse graphs. This includes both labelled and unlabelled instances. The previous fastest methods for general RWKs were of cubic time complexity and not applicable to labelled graphs. Our method samples dependent random walks to compute novel graph embeddings in $\mathbb{R}^d$ whose dot product is equal to the true RWK in expectation. It does so without instantiating the direct product graph in memory, meaning we can scale to massive datasets that cannot be stored on a single machine. We derive exponential concentration bounds to prove that our estimator is sharp, and show that the ability to approximate general RWKs (rather than just special cases) unlocks efficient implicit graph kernel learning. Our method is up to $\mathbf{27\times}$ faster than its counterparts for efficient computation on large graphs and scales to graphs $\mathbf{128 \times}$ bigger than largest examples amenable to brute-force computation.
Linear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Variance-Reducing Couplings for Random Features: Perspectives from Optimal Transport
May 26, 2024



Random features (RFs) are a popular technique to scale up kernel methods in machine learning, replacing exact kernel evaluations with stochastic Monte Carlo estimates. They underpin models as diverse as efficient transformers (by approximating attention) to sparse spectrum Gaussian processes (by approximating the covariance function). Efficiency can be further improved by speeding up the convergence of these estimates: a variance reduction problem. We tackle this through the unifying framework of optimal transport, using theoretical insights and numerical algorithms to develop novel, high-performing RF couplings for kernels defined on Euclidean and discrete input spaces. They enjoy concrete theoretical performance guarantees and sometimes provide strong empirical downstream gains, including for scalable approximate inference on graphs. We reach surprising conclusions about the benefits and limitations of variance reduction as a paradigm.
Universal Graph Random Features
Oct 10, 2023



We propose a novel random walk-based algorithm for unbiased estimation of arbitrary functions of a weighted adjacency matrix, coined universal graph random features (u-GRFs). This includes many of the most popular examples of kernels defined on the nodes of a graph. Our algorithm enjoys subquadratic time complexity with respect to the number of nodes, overcoming the notoriously prohibitive cubic scaling of exact graph kernel evaluation. It can also be trivially distributed across machines, permitting learning on much larger networks. At the heart of the algorithm is a modulation function which upweights or downweights the contribution from different random walks depending on their lengths. We show that by parameterising it with a neural network we can obtain u-GRFs that give higher-quality kernel estimates or perform efficient, scalable kernel learning. We provide robust theoretical analysis and support our findings with experiments including pointwise estimation of fixed graph kernels, solving non-homogeneous graph ordinary differential equations, node clustering and kernel regression on triangular meshes.
Repelling Random Walks
Oct 07, 2023



We present a novel quasi-Monte Carlo mechanism to improve graph-based sampling, coined repelling random walks. By inducing correlations between the trajectories of an interacting ensemble such that their marginal transition probabilities are unmodified, we are able to explore the graph more efficiently, improving the concentration of statistical estimators whilst leaving them unbiased. The mechanism has a trivial drop-in implementation. We showcase the effectiveness of repelling random walks in a range of settings including estimation of graph kernels, the PageRank vector and graphlet concentrations. We provide detailed experimental evaluation and robust theoretical guarantees. To our knowledge, repelling random walks constitute the first rigorously studied quasi-Monte Carlo scheme correlating the directions of walkers on a graph, inviting new research in this exciting nascent domain.