 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpdate-Free On-Policy Steering via Verifiers
Mar 10, 2026In recent years, Behavior Cloning (BC) has become one of the most prevalent methods for enabling robots to mimic human demonstrations. However, despite their successes, BC policies are often brittle and struggle with precise manipulation. To overcome these issues, we propose UF-OPS, an Update-Free On-Policy Steering method that enables the robot to predict the success likelihood of its actions and adapt its strategy at execution time. We accomplish this by training verifier functions using policy rollout data obtained during an initial evaluation of the policy. These verifiers are subsequently used to steer the base policy toward actions with a higher likelihood of success. Our method improves the performance of black-box diffusion policy, without changing the base parameters, making it light-weight and flexible. We present results from both simulation and real-world data and achieve an average 49% improvement in success rate over the base policy across 5 real tasks.
BPP: Long-Context Robot Imitation Learning by Focusing on Key History Frames
Feb 16, 2026Many robot tasks require attending to the history of past observations. For example, finding an item in a room requires remembering which places have already been searched. However, the best-performing robot policies typically condition only on the current observation, limiting their applicability to such tasks. Naively conditioning on past observations often fails due to spurious correlations: policies latch onto incidental features of training histories that do not generalize to out-of-distribution trajectories upon deployment. We analyze why policies latch onto these spurious correlations and find that this problem stems from limited coverage over the space of possible histories during training, which grows exponentially with horizon. Existing regularization techniques provide inconsistent benefits across tasks, as they do not fundamentally address this coverage problem. Motivated by these findings, we propose Big Picture Policies (BPP), an approach that conditions on a minimal set of meaningful keyframes detected by a vision-language model. By projecting diverse rollouts onto a compact set of task-relevant events, BPP substantially reduces distribution shift between training and deployment, without sacrificing expressivity. We evaluate BPP on four challenging real-world manipulation tasks and three simulation tasks, all requiring history conditioning. BPP achieves 70% higher success rates than the best comparison on real-world evaluations.
GeoMatch++: Morphology Conditioned Geometry Matching for Multi-Embodiment Grasping
Dec 25, 2024



Despite recent progress on multi-finger dexterous grasping, current methods focus on single grippers and unseen objects, and even the ones that explore cross-embodiment, often fail to generalize well to unseen end-effectors. This work addresses the problem of dexterous grasping generalization to unseen end-effectors via a unified policy that learns correlation between gripper morphology and object geometry. Robot morphology contains rich information representing how joints and links connect and move with respect to each other and thus, we leverage it through attention to learn better end-effector geometry features. Our experiments show an average of 9.64% increase in grasp success rate across 3 out-of-domain end-effectors compared to previous methods.
Vid2Robot: End-to-end Video-conditioned Policy Learning with Cross-Attention Transformers
Mar 19, 2024



While large-scale robotic systems typically rely on textual instructions for tasks, this work explores a different approach: can robots infer the task directly from observing humans? This shift necessitates the robot's ability to decode human intent and translate it into executable actions within its physical constraints and environment. We introduce Vid2Robot, a novel end-to-end video-based learning framework for robots. Given a video demonstration of a manipulation task and current visual observations, Vid2Robot directly produces robot actions. This is achieved through a unified representation model trained on a large dataset of human video and robot trajectory. The model leverages cross-attention mechanisms to fuse prompt video features to the robot's current state and generate appropriate actions that mimic the observed task. To further improve policy performance, we propose auxiliary contrastive losses that enhance the alignment between human and robot video representations. We evaluate Vid2Robot on real-world robots, demonstrating a 20% improvement in performance compared to other video-conditioned policies when using human demonstration videos. Additionally, our model exhibits emergent capabilities, such as successfully transferring observed motions from one object to another, and long-horizon composition, thus showcasing its potential for real-world applications. Project website: vid2robot.github.io
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
Geometry Matching for Multi-Embodiment Grasping
Dec 06, 2023



Many existing learning-based grasping approaches concentrate on a single embodiment, provide limited generalization to higher DoF end-effectors and cannot capture a diverse set of grasp modes. We tackle the problem of grasping using multiple embodiments by learning rich geometric representations for both objects and end-effectors using Graph Neural Networks. Our novel method - GeoMatch - applies supervised learning on grasping data from multiple embodiments, learning end-to-end contact point likelihood maps as well as conditional autoregressive predictions of grasps keypoint-by-keypoint. We compare our method against baselines that support multiple embodiments. Our approach performs better across three end-effectors, while also producing diverse grasps. Examples, including real robot demos, can be found at geo-match.github.io.
See, Plan, Predict: Language-guided Cognitive Planning with Video Prediction
Oct 07, 2022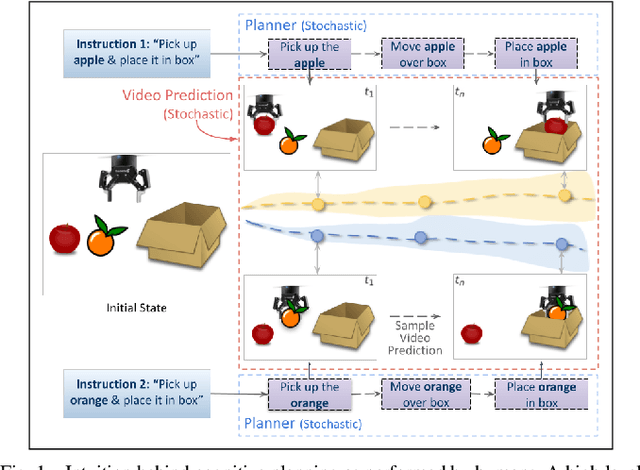
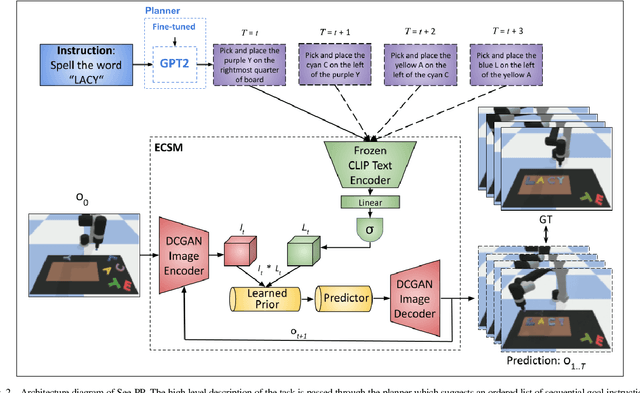
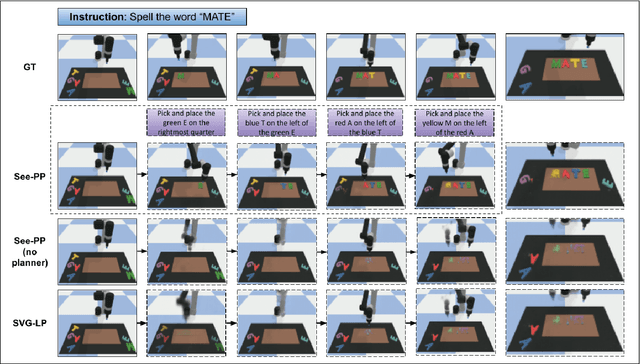

Cognitive planning is the structural decomposition of complex tasks into a sequence of future behaviors. In the computational setting, performing cognitive planning entails grounding plans and concepts in one or more modalities in order to leverage them for low level control. Since real-world tasks are often described in natural language, we devise a cognitive planning algorithm via language-guided video prediction. Current video prediction models do not support conditioning on natural language instructions. Therefore, we propose a new video prediction architecture which leverages the power of pre-trained transformers.The network is endowed with the ability to ground concepts based on natural language input with generalization to unseen objects. We demonstrate the effectiveness of this approach on a new simulation dataset, where each task is defined by a high-level action described in natural language. Our experiments compare our method again stone video generation baseline without planning or action grounding and showcase significant improvements. Our ablation studies highlight an improved generalization to unseen objects that natural language embeddings offer to concept grounding ability, as well as the importance of planning towards visual "imagination" of a task.
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
Oct 27, 2020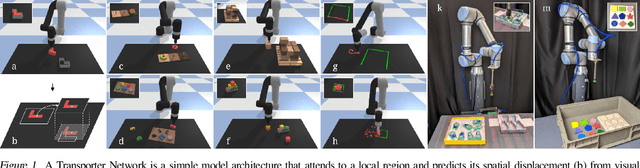
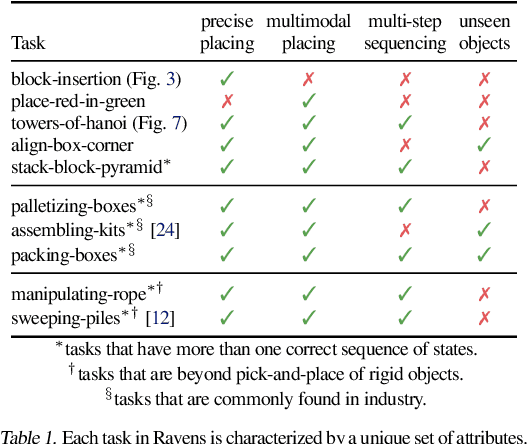
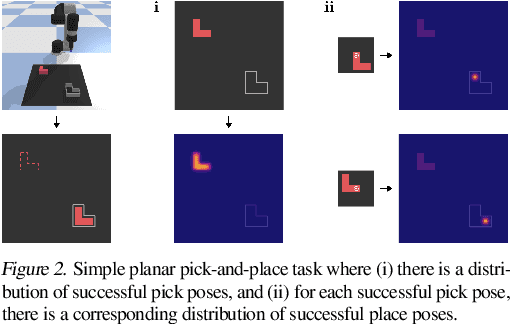
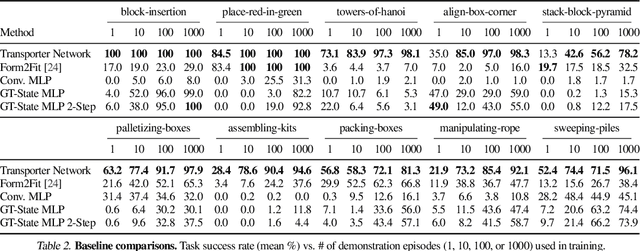
Robotic manipulation can be formulated as inducing a sequence of spatial displacements: where the space being moved can encompass an object, part of an object, or end effector. In this work, we propose the Transporter Network, a simple model architecture that rearranges deep features to infer spatial displacements from visual input - which can parameterize robot actions. It makes no assumptions of objectness (e.g. canonical poses, models, or keypoints), it exploits spatial symmetries, and is orders of magnitude more sample efficient than our benchmarked alternatives in learning vision-based manipulation tasks: from stacking a pyramid of blocks, to assembling kits with unseen objects; from manipulating deformable ropes, to pushing piles of small objects with closed-loop feedback. Our method can represent complex multi-modal policy distributions and generalizes to multi-step sequential tasks, as well as 6DoF pick-and-place. Experiments on 10 simulated tasks show that it learns faster and generalizes better than a variety of end-to-end baselines, including policies that use ground-truth object poses. We validate our methods with hardware in the real world. Experiment videos and code will be made available at https://transporternets.github.io
Transforming Neural Network Visual Representations to Predict Human Judgments of Similarity
Oct 13, 2020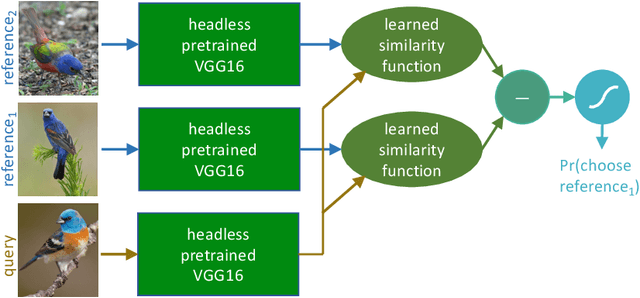
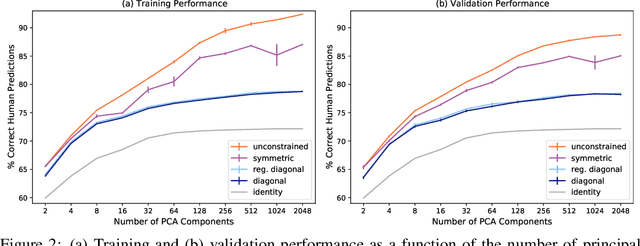
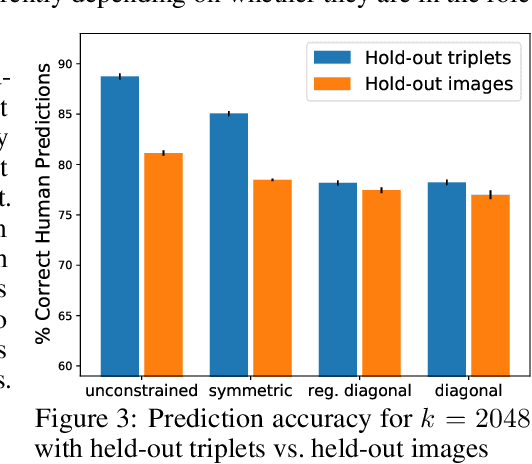
Deep-learning vision models have shown intriguing similarities and differences with respect to human vision. We investigate how to bring machine visual representations into better alignment with human representations. Human representations are often inferred from behavioral evidence such as the selection of an image most similar to a query image. We find that with appropriate linear transformations of deep embeddings, we can improve prediction of human binary choice on a data set of bird images from 72% at baseline to 89%. We hypothesized that deep embeddings have redundant, high (4096) dimensional representations; however, reducing the rank of these representations results in a loss of explanatory power. We hypothesized that the dilation transformation of representations explored in past research is too restrictive, and indeed we found that model explanatory power can be significantly improved with a more expressive linear transform. Most surprising and exciting, we found that, consistent with classic psychological literature, human similarity judgments are asymmetric: the similarity of X to Y is not necessarily equal to the similarity of Y to X, and allowing models to express this asymmetry improves explanatory power.
Combining Learned Lyrical Structures and Vocabulary for Improved Lyric Generation
Nov 12, 2018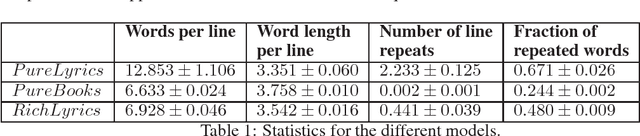
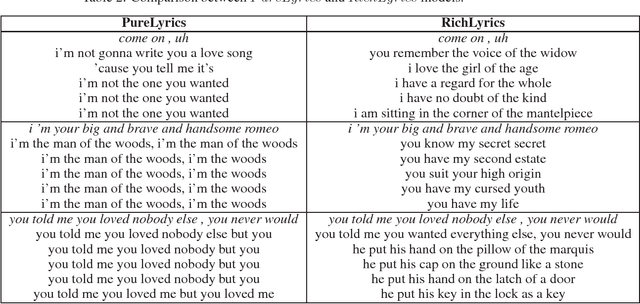
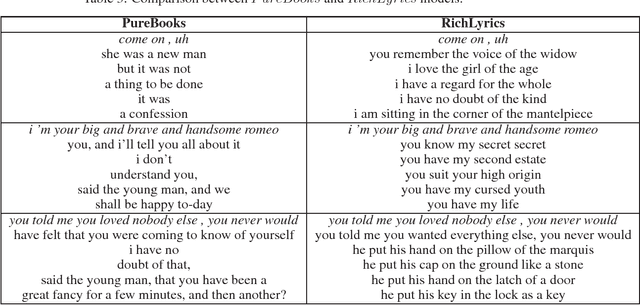
The use of language models for generating lyrics and poetry has received an increased interest in the last few years. They pose a unique challenge relative to standard natural language problems, as their ultimate purpose is reative, notions of accuracy and reproducibility are secondary to notions of lyricism, structure, and diversity. In this creative setting, traditional quantitative measures for natural language problems, such as BLEU scores, prove inadequate: a high-scoring model may either fail to produce output respecting the desired structure (e.g. song verses), be a terribly boring creative companion, or both. In this work we propose a mechanism for combining two separately trained language models into a framework that is able to produce output respecting the desired song structure, while providing a richness and diversity of vocabulary that renders it more creatively appealing.