 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Where is VALDO? VAscular Lesions Detection and segmentatiOn challenge at MICCAI 2021
Aug 15, 2022
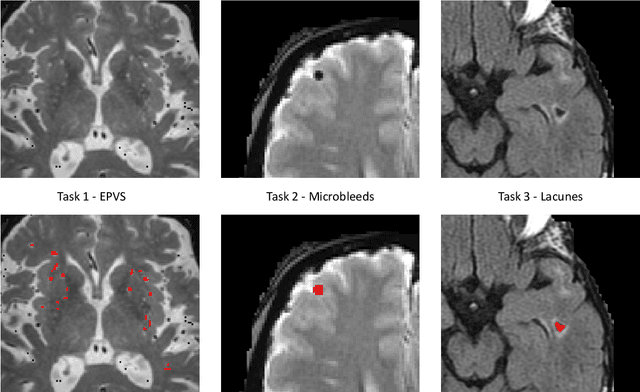
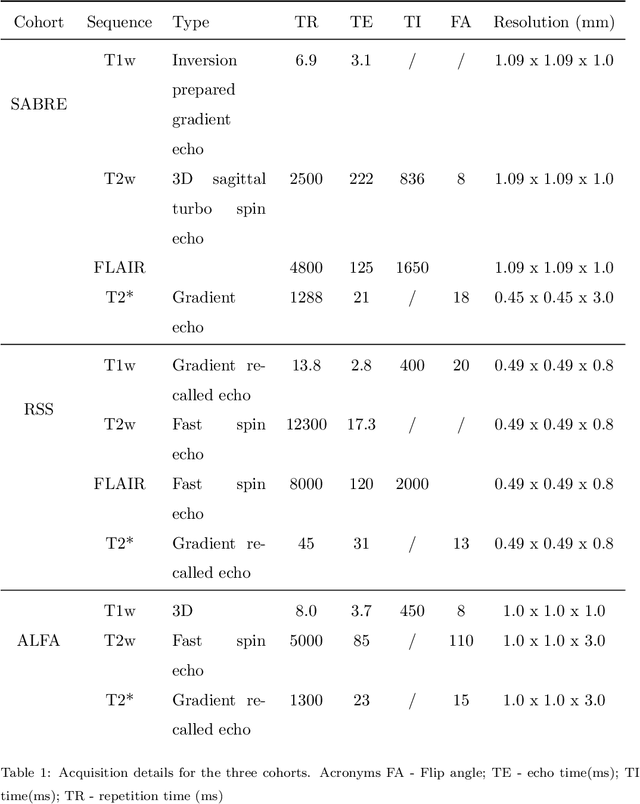
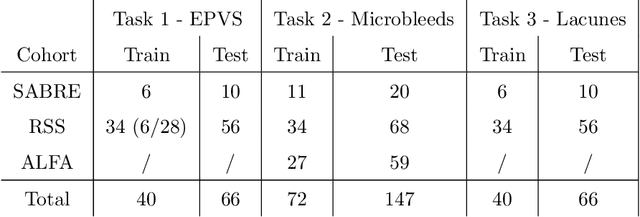
Imaging markers of cerebral small vessel disease provide valuable information on brain health, but their manual assessment is time-consuming and hampered by substantial intra- and interrater variability. Automated rating may benefit biomedical research, as well as clinical assessment, but diagnostic reliability of existing algorithms is unknown. Here, we present the results of the \textit{VAscular Lesions DetectiOn and Segmentation} (\textit{Where is VALDO?}) challenge that was run as a satellite event at the international conference on Medical Image Computing and Computer Aided Intervention (MICCAI) 2021. This challenge aimed to promote the development of methods for automated detection and segmentation of small and sparse imaging markers of cerebral small vessel disease, namely enlarged perivascular spaces (EPVS) (Task 1), cerebral microbleeds (Task 2) and lacunes of presumed vascular origin (Task 3) while leveraging weak and noisy labels. Overall, 12 teams participated in the challenge proposing solutions for one or more tasks (4 for Task 1 - EPVS, 9 for Task 2 - Microbleeds and 6 for Task 3 - Lacunes). Multi-cohort data was used in both training and evaluation. Results showed a large variability in performance both across teams and across tasks, with promising results notably for Task 1 - EPVS and Task 2 - Microbleeds and not practically useful results yet for Task 3 - Lacunes. It also highlighted the performance inconsistency across cases that may deter use at an individual level, while still proving useful at a population level.
How GNNs Facilitate CNNs in Mining Geometric Information from Large-Scale Medical Images
Jun 15, 2022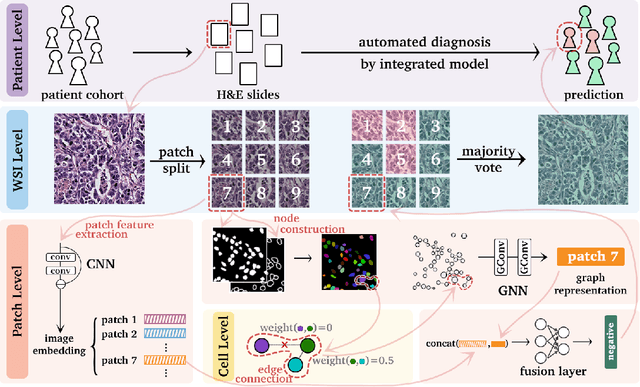
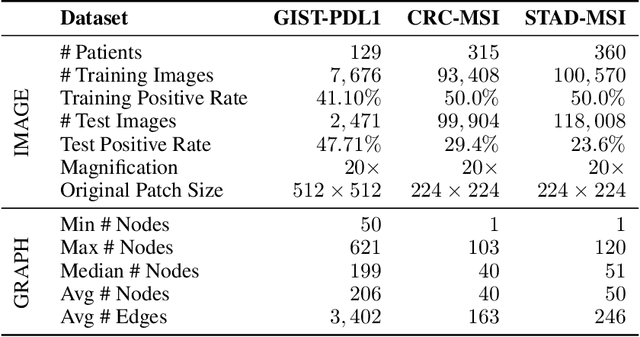
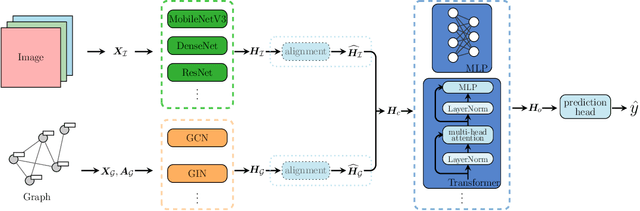
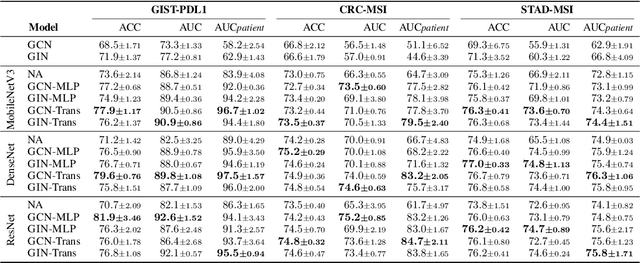
Gigapixel medical images provide massive data, both morphological textures and spatial information, to be mined. Due to the large data scale in histology, deep learning methods play an increasingly significant role as feature extractors. Existing solutions heavily rely on convolutional neural networks (CNNs) for global pixel-level analysis, leaving the underlying local geometric structure such as the interaction between cells in the tumor microenvironment unexplored. The topological structure in medical images, as proven to be closely related to tumor evolution, can be well characterized by graphs. To obtain a more comprehensive representation for downstream oncology tasks, we propose a fusion framework for enhancing the global image-level representation captured by CNNs with the geometry of cell-level spatial information learned by graph neural networks (GNN). The fusion layer optimizes an integration between collaborative features of global images and cell graphs. Two fusion strategies have been developed: one with MLP which is simple but turns out efficient through fine-tuning, and the other with Transformer gains a champion in fusing multiple networks. We evaluate our fusion strategies on histology datasets curated from large patient cohorts of colorectal and gastric cancers for three biomarker prediction tasks. Both two models outperform plain CNNs or GNNs, reaching a consistent AUC improvement of more than 5% on various network backbones. The experimental results yield the necessity for combining image-level morphological features with cell spatial relations in medical image analysis. Codes are available at https://github.com/yiqings/HEGnnEnhanceCnn.
Evaluating Systemic Error Detection Methods using Synthetic Images
Jul 08, 2022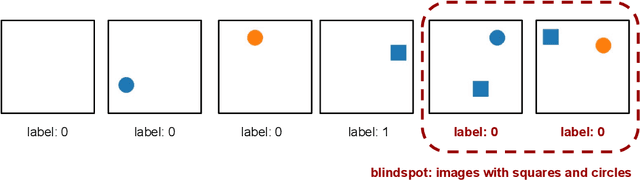
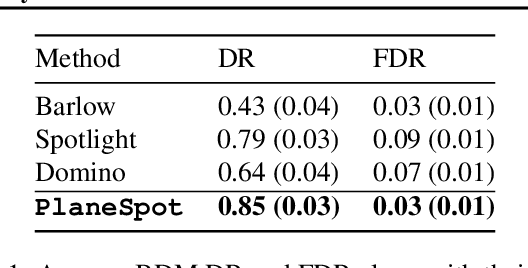
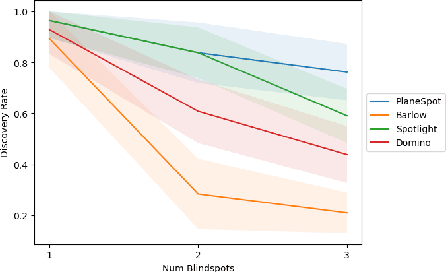

We introduce SpotCheck, a framework for generating synthetic datasets to use for evaluating methods for discovering blindspots (i.e., systemic errors) in image classifiers. We use SpotCheck to run controlled studies of how various factors influence the performance of blindspot discovery methods. Our experiments reveal several shortcomings of existing methods, such as relatively poor performance in settings with multiple blindspots and sensitivity to hyperparameters. Further, we find that a method based on dimensionality reduction, PlaneSpot, is competitive with existing methods, which has promising implications for the development of interactive tools.
DualCoOp: Fast Adaptation to Multi-Label Recognition with Limited Annotations
Jun 20, 2022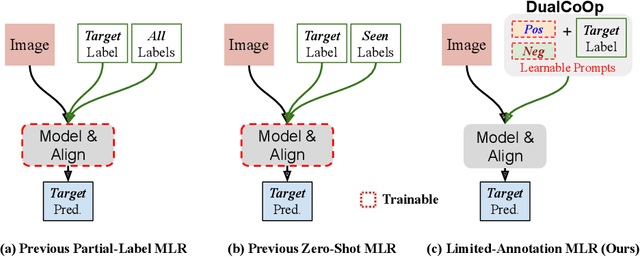
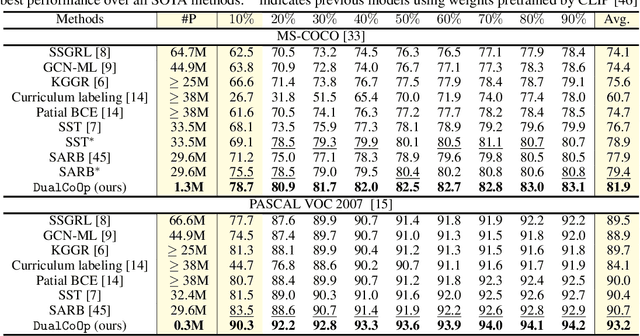
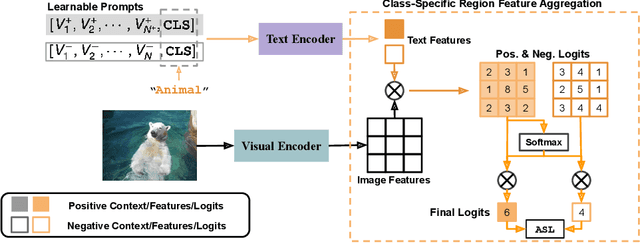
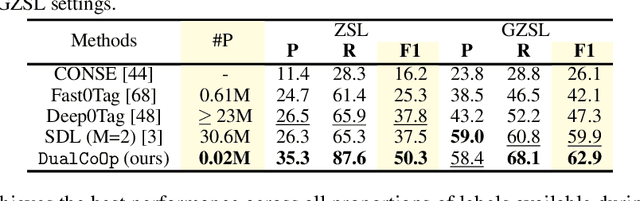
Solving multi-label recognition (MLR) for images in the low-label regime is a challenging task with many real-world applications. Recent work learns an alignment between textual and visual spaces to compensate for insufficient image labels, but loses accuracy because of the limited amount of available MLR annotations. In this work, we utilize the strong alignment of textual and visual features pretrained with millions of auxiliary image-text pairs and propose Dual Context Optimization (DualCoOp) as a unified framework for partial-label MLR and zero-shot MLR. DualCoOp encodes positive and negative contexts with class names as part of the linguistic input (i.e. prompts). Since DualCoOp only introduces a very light learnable overhead upon the pretrained vision-language framework, it can quickly adapt to multi-label recognition tasks that have limited annotations and even unseen classes. Experiments on standard multi-label recognition benchmarks across two challenging low-label settings demonstrate the advantages of our approach over state-of-the-art methods.
Language-Driven Image Style Transfer
Jun 01, 2021
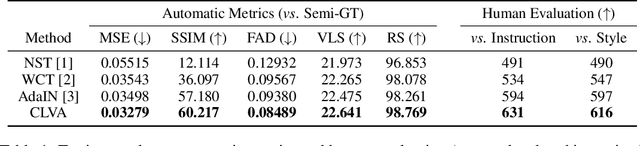
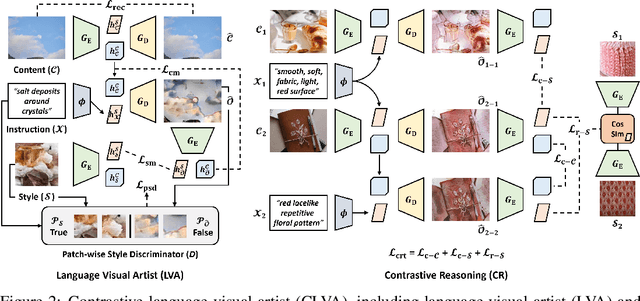
Despite having promising results, style transfer, which requires preparing style images in advance, may result in lack of creativity and accessibility. Following human instruction, on the other hand, is the most natural way to perform artistic style transfer that can significantly improve controllability for visual effect applications. We introduce a new task -- language-driven image style transfer (\texttt{LDIST}) -- to manipulate the style of a content image, guided by a text. We propose contrastive language visual artist (CLVA) that learns to extract visual semantics from style instructions and accomplish \texttt{LDIST} by the patch-wise style discriminator. The discriminator considers the correlation between language and patches of style images or transferred results to jointly embed style instructions. CLVA further compares contrastive pairs of content image and style instruction to improve the mutual relativeness between transfer results. The transferred results from the same content image can preserve consistent content structures. Besides, they should present analogous style patterns from style instructions that contain similar visual semantics. The experiments show that our CLVA is effective and achieves superb transferred results on \texttt{LDIST}.
Unbalanced Feature Transport for Exemplar-based Image Translation
Jun 19, 2021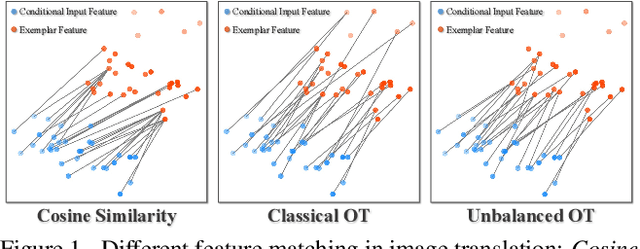
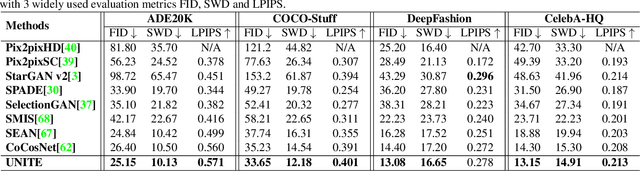
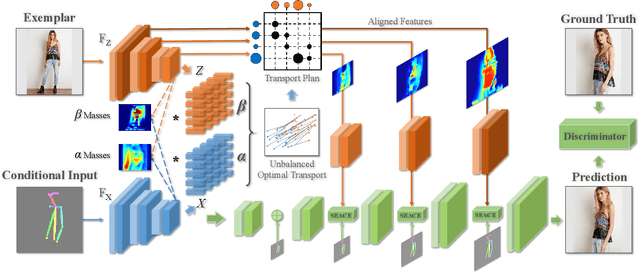
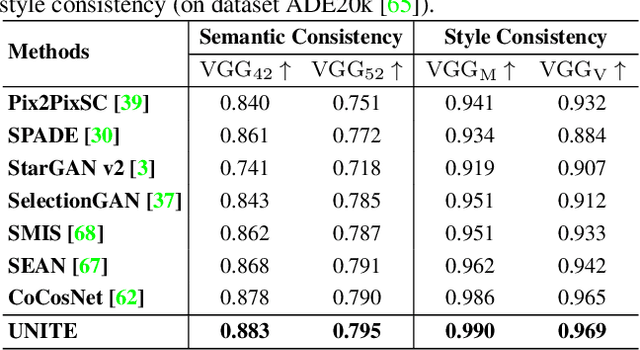
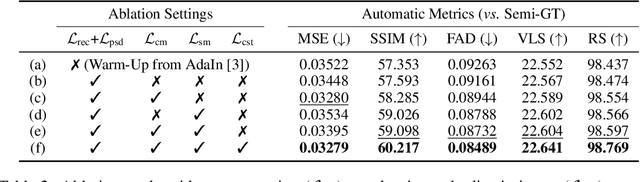
Despite the great success of GANs in images translation with different conditioned inputs such as semantic segmentation and edge maps, generating high-fidelity realistic images with reference styles remains a grand challenge in conditional image-to-image translation. This paper presents a general image translation framework that incorporates optimal transport for feature alignment between conditional inputs and style exemplars in image translation. The introduction of optimal transport mitigates the constraint of many-to-one feature matching significantly while building up accurate semantic correspondences between conditional inputs and exemplars. We design a novel unbalanced optimal transport to address the transport between features with deviational distributions which exists widely between conditional inputs and exemplars. In addition, we design a semantic-activation normalization scheme that injects style features of exemplars into the image translation process successfully. Extensive experiments over multiple image translation tasks show that our method achieves superior image translation qualitatively and quantitatively as compared with the state-of-the-art.
Contrastive Semi-supervised Learning for Domain Adaptive Segmentation Across Similar Anatomical Structures
Aug 18, 2022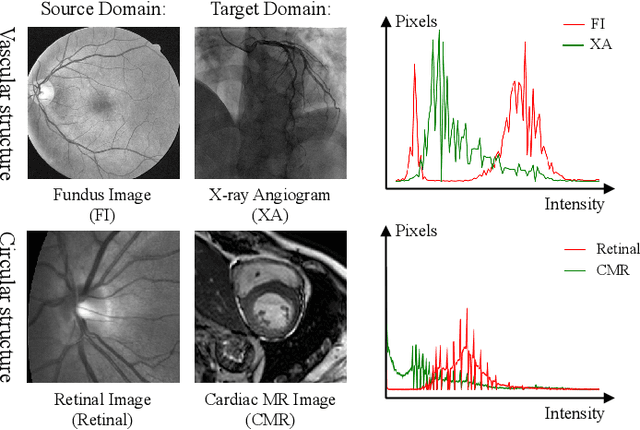
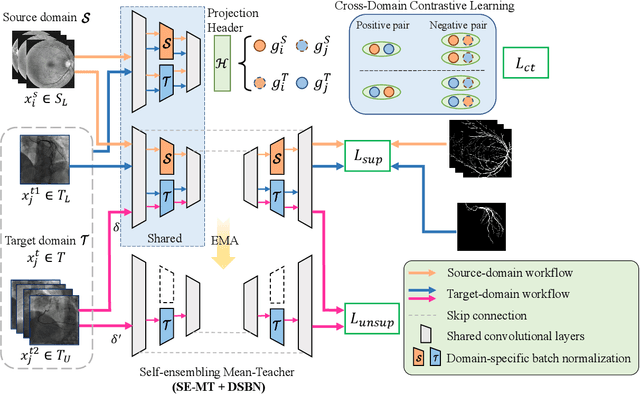
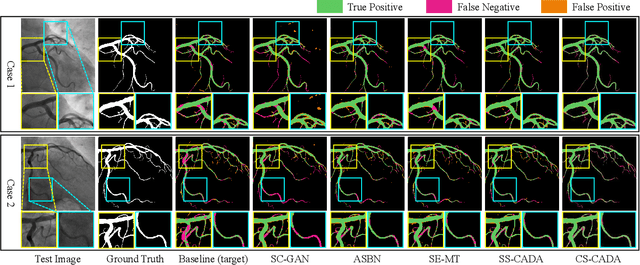
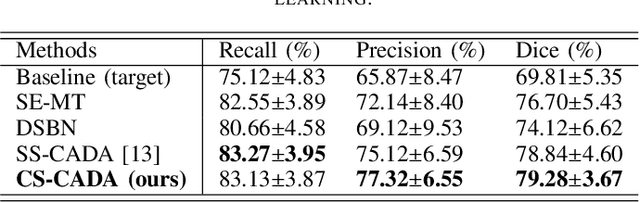
Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance for medical image segmentation, yet need plenty of manual annotations for training. Semi-Supervised Learning (SSL) methods are promising to reduce the requirement of annotations, but their performance is still limited when the dataset size and the number of annotated images are small. Leveraging existing annotated datasets with similar anatomical structures to assist training has a potential for improving the model's performance. However, it is further challenged by the cross-anatomy domain shift due to the different appearance and even imaging modalities from the target structure. To solve this problem, we propose Contrastive Semi-supervised learning for Cross Anatomy Domain Adaptation (CS-CADA) that adapts a model to segment similar structures in a target domain, which requires only limited annotations in the target domain by leveraging a set of existing annotated images of similar structures in a source domain. We use Domain-Specific Batch Normalization (DSBN) to individually normalize feature maps for the two anatomical domains, and propose a cross-domain contrastive learning strategy to encourage extracting domain invariant features. They are integrated into a Self-Ensembling Mean-Teacher (SE-MT) framework to exploit unlabeled target domain images with a prediction consistency constraint. Extensive experiments show that our CS-CADA is able to solve the challenging cross-anatomy domain shift problem, achieving accurate segmentation of coronary arteries in X-ray images with the help of retinal vessel images and cardiac MR images with the help of fundus images, respectively, given only a small number of annotations in the target domain.
SDF-StyleGAN: Implicit SDF-Based StyleGAN for 3D Shape Generation
Jun 24, 2022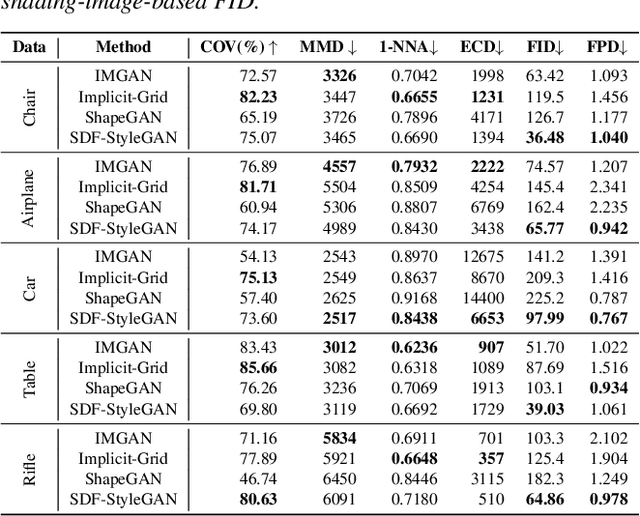

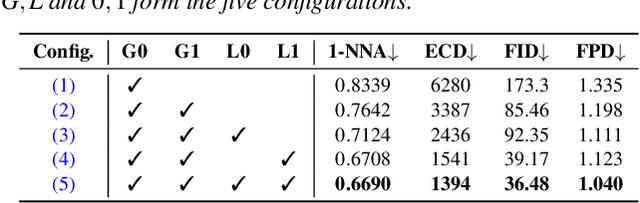
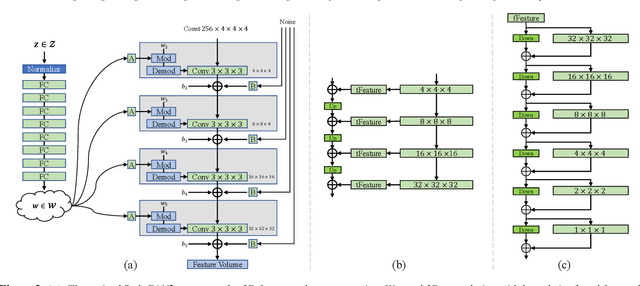
We present a StyleGAN2-based deep learning approach for 3D shape generation, called SDF-StyleGAN, with the aim of reducing visual and geometric dissimilarity between generated shapes and a shape collection. We extend StyleGAN2 to 3D generation and utilize the implicit signed distance function (SDF) as the 3D shape representation, and introduce two novel global and local shape discriminators that distinguish real and fake SDF values and gradients to significantly improve shape geometry and visual quality. We further complement the evaluation metrics of 3D generative models with the shading-image-based Fr\'echet inception distance (FID) scores to better assess visual quality and shape distribution of the generated shapes. Experiments on shape generation demonstrate the superior performance of SDF-StyleGAN over the state-of-the-art. We further demonstrate the efficacy of SDF-StyleGAN in various tasks based on GAN inversion, including shape reconstruction, shape completion from partial point clouds, single-view image-based shape generation, and shape style editing. Extensive ablation studies justify the efficacy of our framework design. Our code and trained models are available at https://github.com/Zhengxinyang/SDF-StyleGAN.
Towards Domain-agnostic Depth Completion
Jul 29, 2022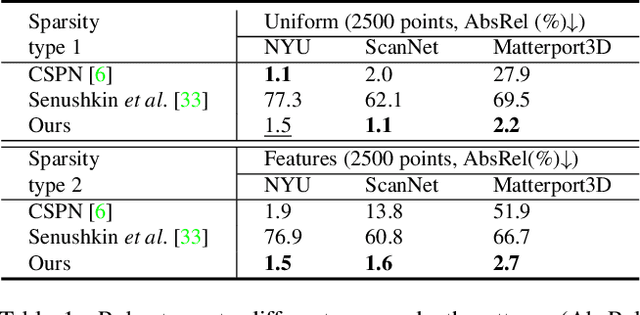

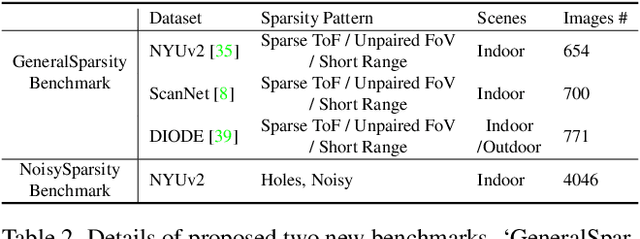

Existing depth completion methods are often targeted at a specific sparse depth type, and generalize poorly across task domains. We present a method to complete sparse/semi-dense, noisy, and potentially low-resolution depth maps obtained by various range sensors, including those in modern mobile phones, or by multi-view reconstruction algorithms. Our method leverages a data driven prior in the form of a single image depth prediction network trained on large-scale datasets, the output of which is used as an input to our model. We propose an effective training scheme where we simulate various sparsity patterns in typical task domains. In addition, we design two new benchmarks to evaluate the generalizability and the robustness of depth completion methods. Our simple method shows superior cross-domain generalization ability against state-of-the-art depth completion methods, introducing a practical solution to high quality depth capture on a mobile device. Code is available at: https://github.com/YvanYin/FillDepth.
Image-to-image Translation via Hierarchical Style Disentanglement
Mar 02, 2021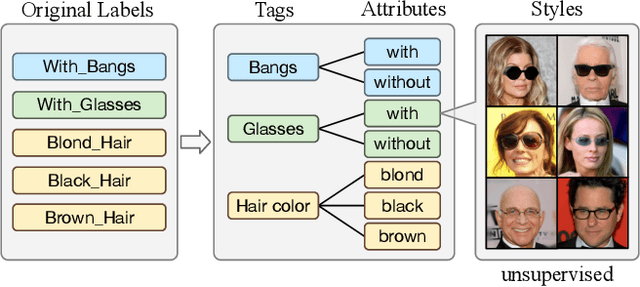


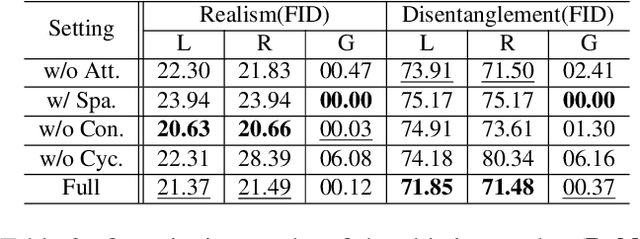
Recently, image-to-image translation has made significant progress in achieving both multi-label (\ie, translation conditioned on different labels) and multi-style (\ie, generation with diverse styles) tasks. However, due to the unexplored independence and exclusiveness in the labels, existing endeavors are defeated by involving uncontrolled manipulations to the translation results. In this paper, we propose Hierarchical Style Disentanglement (HiSD) to address this issue. Specifically, we organize the labels into a hierarchical tree structure, in which independent tags, exclusive attributes, and disentangled styles are allocated from top to bottom. Correspondingly, a new translation process is designed to adapt the above structure, in which the styles are identified for controllable translations. Both qualitative and quantitative results on the CelebA-HQ dataset verify the ability of the proposed HiSD. We hope our method will serve as a solid baseline and provide fresh insights with the hierarchically organized annotations for future research in image-to-image translation. The code has been released at https://github.com/imlixinyang/HiSD.