 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Extraction of Structured Information from Brain MRI Reports Using an Open-Weight Large Language Model
Jun 05, 2026Objectives: Automatic data extraction from free-text radiology reports enables large-scale research, but few studies assessed the performance of large language models (LLMs) on Dutch neuroradiology reports. Methods: We analyzed 947 brain MRI reports from a tertiary memory clinic (2016-2021), authored by consultant neuroradiologists. Trained medical students annotated thirty variables; 100 reports were double-annotated to assess inter-rater reliability. We evaluated the performance of the open-weight LLM LLaMA 3.1 using different languages (Dutch vs. English translation) and few-shot prompting with different example selection strategies. Performance was evaluated using balanced accuracy for categorical variables, accuracy and mean absolute error for counts, and text similarity for free-text. Metrics were computed across 10 random splits of the 947 reports. Results: LLaMA 3.1 demonstrated high zero-shot performance for visual rating scores (mean [95%-CI]): Medial Temporal Atrophy: 90% [77-100%] on the left and 96% [94-99%] on the right, Global Cortical Atrophy: 87% [83-91%], and Fazekas: 94% [93-96%]. Microbleed mentions were detected with 93% accuracy [92-95%] and infarct mentions with 82% [80-84%]. Text similarity for lesion location reached 0.95 [0.95-0.96]. Performance was lower for numerical variables: 80% [78-82%] for the number of microbleeds and 66% [63-68%] for infarcts. English translation yielded comparable results. Few-shot prompting improved performance for numerical variables, achieving 92% [90-93%] for microbleeds and 81% [77-85%] for infarcts using structural similarity-based selection. Conclusion: LLaMA 3.1 shows strong potential for extracting data from Dutch neuroradiology reports. Few-shot prompting enhances performance for numerical variables, whereas challenges remain for location-specific variables.
Where is VALDO? VAscular Lesions Detection and segmentatiOn challenge at MICCAI 2021
Aug 15, 2022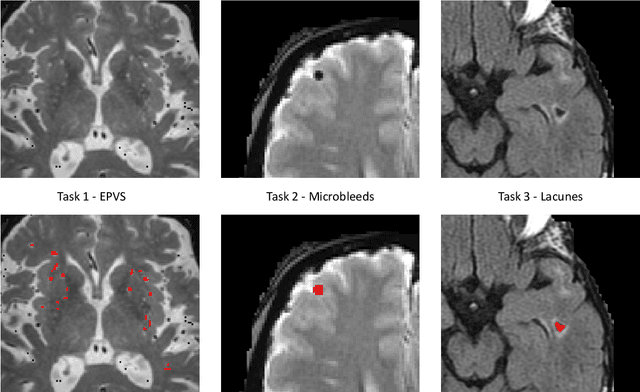
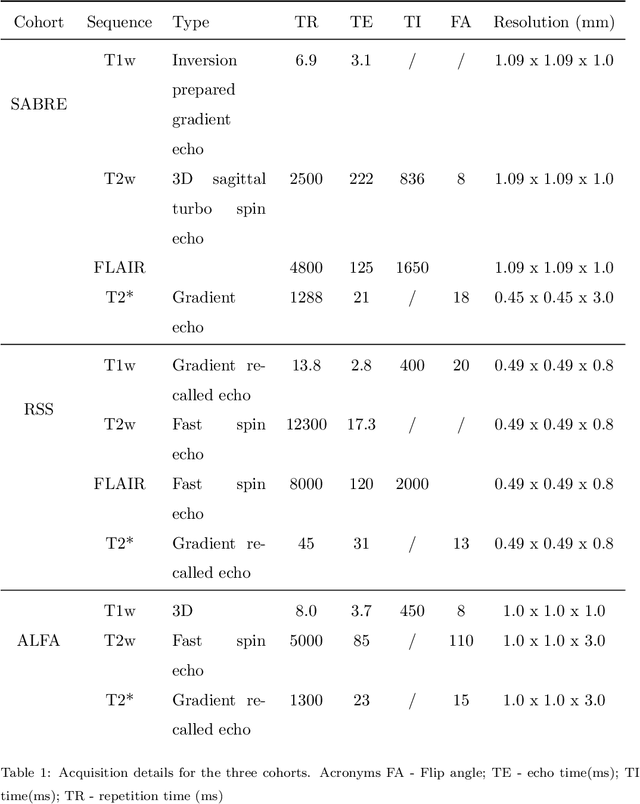
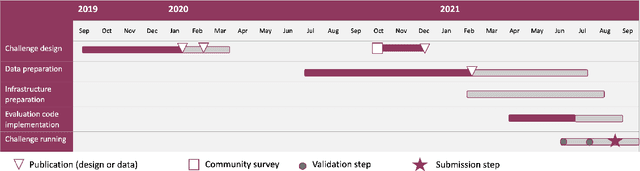
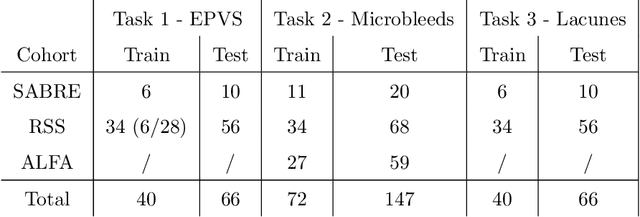
Imaging markers of cerebral small vessel disease provide valuable information on brain health, but their manual assessment is time-consuming and hampered by substantial intra- and interrater variability. Automated rating may benefit biomedical research, as well as clinical assessment, but diagnostic reliability of existing algorithms is unknown. Here, we present the results of the \textit{VAscular Lesions DetectiOn and Segmentation} (\textit{Where is VALDO?}) challenge that was run as a satellite event at the international conference on Medical Image Computing and Computer Aided Intervention (MICCAI) 2021. This challenge aimed to promote the development of methods for automated detection and segmentation of small and sparse imaging markers of cerebral small vessel disease, namely enlarged perivascular spaces (EPVS) (Task 1), cerebral microbleeds (Task 2) and lacunes of presumed vascular origin (Task 3) while leveraging weak and noisy labels. Overall, 12 teams participated in the challenge proposing solutions for one or more tasks (4 for Task 1 - EPVS, 9 for Task 2 - Microbleeds and 6 for Task 3 - Lacunes). Multi-cohort data was used in both training and evaluation. Results showed a large variability in performance both across teams and across tasks, with promising results notably for Task 1 - EPVS and Task 2 - Microbleeds and not practically useful results yet for Task 3 - Lacunes. It also highlighted the performance inconsistency across cases that may deter use at an individual level, while still proving useful at a population level.