 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-VAds: An E-commerce Short Videos Understanding Benchmark for MLLMs
Feb 09, 2026E-commerce short videos represent a high-revenue segment of the online video industry characterized by a goal-driven format and dense multi-modal signals. Current models often struggle with these videos because existing benchmarks focus primarily on general-purpose tasks and neglect the reasoning of commercial intent. In this work, we first propose a \textbf{multi-modal information density assessment framework} to quantify the complexity of this domain. Our evaluation reveals that e-commerce content exhibits substantially higher density across visual, audio, and textual modalities compared to mainstream datasets, establishing a more challenging frontier for video understanding. To address this gap, we introduce \textbf{E-commerce Video Ads Benchmark (E-VAds)}, which is the first benchmark specifically designed for e-commerce short video understanding. We curated 3,961 high-quality videos from Taobao covering a wide range of product categories and used a multi-agent system to generate 19,785 open-ended Q&A pairs. These questions are organized into two primary dimensions, namely Perception and Cognition and Reasoning, which consist of five distinct tasks. Finally, we develop \textbf{E-VAds-R1}, an RL-based reasoning model featuring a multi-grained reward design called \textbf{MG-GRPO}. This strategy provides smooth guidance for early exploration while creating a non-linear incentive for expert-level precision. Experimental results demonstrate that E-VAds-R1 achieves a 109.2% performance gain in commercial intent reasoning with only a few hundred training samples.
Graph Smoothing for Enhanced Local Geometry Learning in Point Cloud Analysis
Jan 16, 2026Graph-based methods have proven to be effective in capturing relationships among points for 3D point cloud analysis. However, these methods often suffer from suboptimal graph structures, particularly due to sparse connections at boundary points and noisy connections in junction areas. To address these challenges, we propose a novel method that integrates a graph smoothing module with an enhanced local geometry learning module. Specifically, we identify the limitations of conventional graph structures, particularly in handling boundary points and junction areas. In response, we introduce a graph smoothing module designed to optimize the graph structure and minimize the negative impact of unreliable sparse and noisy connections. Based on the optimized graph structure, we improve the feature extract function with local geometry information. These include shape features derived from adaptive geometric descriptors based on eigenvectors and distribution features obtained through cylindrical coordinate transformation. Experimental results on real-world datasets validate the effectiveness of our method in various point cloud learning tasks, i.e., classification, part segmentation, and semantic segmentation.
LLM-based Agentic Reasoning Frameworks: A Survey from Methods to Scenarios
Aug 25, 2025Recent advances in the intrinsic reasoning capabilities of large language models (LLMs) have given rise to LLM-based agent systems that exhibit near-human performance on a variety of automated tasks. However, although these systems share similarities in terms of their use of LLMs, different reasoning frameworks of the agent system steer and organize the reasoning process in different ways. In this survey, we propose a systematic taxonomy that decomposes agentic reasoning frameworks and analyze how these frameworks dominate framework-level reasoning by comparing their applications across different scenarios. Specifically, we propose an unified formal language to further classify agentic reasoning systems into single-agent methods, tool-based methods, and multi-agent methods. After that, we provide a comprehensive review of their key application scenarios in scientific discovery, healthcare, software engineering, social simulation, and economics. We also analyze the characteristic features of each framework and summarize different evaluation strategies. Our survey aims to provide the research community with a panoramic view to facilitate understanding of the strengths, suitable scenarios, and evaluation practices of different agentic reasoning frameworks.
Modality-Aware Feature Matching: A Comprehensive Review of Single- and Cross-Modality Techniques
Jul 30, 2025



Feature matching is a cornerstone task in computer vision, essential for applications such as image retrieval, stereo matching, 3D reconstruction, and SLAM. This survey comprehensively reviews modality-based feature matching, exploring traditional handcrafted methods and emphasizing contemporary deep learning approaches across various modalities, including RGB images, depth images, 3D point clouds, LiDAR scans, medical images, and vision-language interactions. Traditional methods, leveraging detectors like Harris corners and descriptors such as SIFT and ORB, demonstrate robustness under moderate intra-modality variations but struggle with significant modality gaps. Contemporary deep learning-based methods, exemplified by detector-free strategies like CNN-based SuperPoint and transformer-based LoFTR, substantially improve robustness and adaptability across modalities. We highlight modality-aware advancements, such as geometric and depth-specific descriptors for depth images, sparse and dense learning methods for 3D point clouds, attention-enhanced neural networks for LiDAR scans, and specialized solutions like the MIND descriptor for complex medical image matching. Cross-modal applications, particularly in medical image registration and vision-language tasks, underscore the evolution of feature matching to handle increasingly diverse data interactions.
Rethinking Range-View LiDAR Segmentation in Adverse Weather
Jun 10, 2025



LiDAR segmentation has emerged as an important task to enrich multimedia experiences and analysis. Range-view-based methods have gained popularity due to their high computational efficiency and compatibility with real-time deployment. However, their generalized performance under adverse weather conditions remains underexplored, limiting their reliability in real-world environments. In this work, we identify and analyze the unique challenges that affect the generalization of range-view LiDAR segmentation in severe weather. To address these challenges, we propose a modular and lightweight framework that enhances robustness without altering the core architecture of existing models. Our method reformulates the initial stem block of standard range-view networks into two branches to process geometric attributes and reflectance intensity separately. Specifically, a Geometric Abnormality Suppression (GAS) module reduces the influence of weather-induced spatial noise, and a Reflectance Distortion Calibration (RDC) module corrects reflectance distortions through memory-guided adaptive instance normalization. The processed features are then fused and passed to the original segmentation pipeline. Extensive experiments on different benchmarks and baseline models demonstrate that our approach significantly improves generalization to adverse weather with minimal inference overhead, offering a practical and effective solution for real-world LiDAR segmentation.
AsynFusion: Towards Asynchronous Latent Consistency Models for Decoupled Whole-Body Audio-Driven Avatars
May 21, 2025Whole-body audio-driven avatar pose and expression generation is a critical task for creating lifelike digital humans and enhancing the capabilities of interactive virtual agents, with wide-ranging applications in virtual reality, digital entertainment, and remote communication. Existing approaches often generate audio-driven facial expressions and gestures independently, which introduces a significant limitation: the lack of seamless coordination between facial and gestural elements, resulting in less natural and cohesive animations. To address this limitation, we propose AsynFusion, a novel framework that leverages diffusion transformers to achieve harmonious expression and gesture synthesis. The proposed method is built upon a dual-branch DiT architecture, which enables the parallel generation of facial expressions and gestures. Within the model, we introduce a Cooperative Synchronization Module to facilitate bidirectional feature interaction between the two modalities, and an Asynchronous LCM Sampling strategy to reduce computational overhead while maintaining high-quality outputs. Extensive experiments demonstrate that AsynFusion achieves state-of-the-art performance in generating real-time, synchronized whole-body animations, consistently outperforming existing methods in both quantitative and qualitative evaluations.
The Final Layer Holds the Key: A Unified and Efficient GNN Calibration Framework
May 16, 2025



Graph Neural Networks (GNNs) have demonstrated remarkable effectiveness on graph-based tasks. However, their predictive confidence is often miscalibrated, typically exhibiting under-confidence, which harms the reliability of their decisions. Existing calibration methods for GNNs normally introduce additional calibration components, which fail to capture the intrinsic relationship between the model and the prediction confidence, resulting in limited theoretical guarantees and increased computational overhead. To address this issue, we propose a simple yet efficient graph calibration method. We establish a unified theoretical framework revealing that model confidence is jointly governed by class-centroid-level and node-level calibration at the final layer. Based on this insight, we theoretically show that reducing the weight decay of the final-layer parameters alleviates GNN under-confidence by acting on the class-centroid level, while node-level calibration acts as a finer-grained complement to class-centroid level calibration, which encourages each test node to be closer to its predicted class centroid at the final-layer representations. Extensive experiments validate the superiority of our method.
TSTMotion: Training-free Scene-aware Text-to-motion Generation
May 05, 2025



Text-to-motion generation has recently garnered significant research interest, primarily focusing on generating human motion sequences in blank backgrounds. However, human motions commonly occur within diverse 3D scenes, which has prompted exploration into scene-aware text-to-motion generation methods. Yet, existing scene-aware methods often rely on large-scale ground-truth motion sequences in diverse 3D scenes, which poses practical challenges due to the expensive cost. To mitigate this challenge, we are the first to propose a \textbf{T}raining-free \textbf{S}cene-aware \textbf{T}ext-to-\textbf{Motion} framework, dubbed as \textbf{TSTMotion}, that efficiently empowers pre-trained blank-background motion generators with the scene-aware capability. Specifically, conditioned on the given 3D scene and text description, we adopt foundation models together to reason, predict and validate a scene-aware motion guidance. Then, the motion guidance is incorporated into the blank-background motion generators with two modifications, resulting in scene-aware text-driven motion sequences. Extensive experiments demonstrate the efficacy and generalizability of our proposed framework. We release our code in \href{https://tstmotion.github.io/}{Project Page}.
Unified Prompt Attack Against Text-to-Image Generation Models
Feb 23, 2025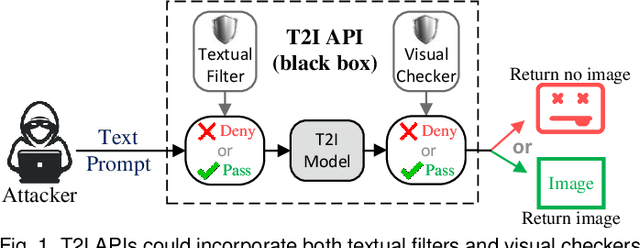
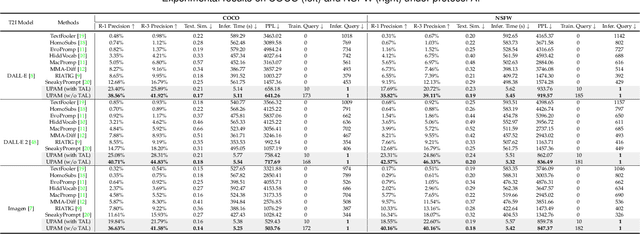
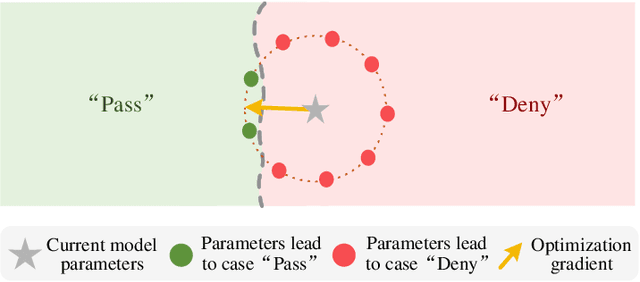

Text-to-Image (T2I) models have advanced significantly, but their growing popularity raises security concerns due to their potential to generate harmful images. To address these issues, we propose UPAM, a novel framework to evaluate the robustness of T2I models from an attack perspective. Unlike prior methods that focus solely on textual defenses, UPAM unifies the attack on both textual and visual defenses. Additionally, it enables gradient-based optimization, overcoming reliance on enumeration for improved efficiency and effectiveness. To handle cases where T2I models block image outputs due to defenses, we introduce Sphere-Probing Learning (SPL) to enable optimization even without image results. Following SPL, our model bypasses defenses, inducing the generation of harmful content. To ensure semantic alignment with attacker intent, we propose Semantic-Enhancing Learning (SEL) for precise semantic control. UPAM also prioritizes the naturalness of adversarial prompts using In-context Naturalness Enhancement (INE), making them harder for human examiners to detect. Additionally, we address the issue of iterative queries--common in prior methods and easily detectable by API defenders--by introducing Transferable Attack Learning (TAL), allowing effective attacks with minimal queries. Extensive experiments validate UPAM's superiority in effectiveness, efficiency, naturalness, and low query detection rates.
Bootstraping Clustering of Gaussians for View-consistent 3D Scene Understanding
Nov 29, 2024Injecting semantics into 3D Gaussian Splatting (3DGS) has recently garnered significant attention. While current approaches typically distill 3D semantic features from 2D foundational models (e.g., CLIP and SAM) to facilitate novel view segmentation and semantic understanding, their heavy reliance on 2D supervision can undermine cross-view semantic consistency and necessitate complex data preparation processes, therefore hindering view-consistent scene understanding. In this work, we present FreeGS, an unsupervised semantic-embedded 3DGS framework that achieves view-consistent 3D scene understanding without the need for 2D labels. Instead of directly learning semantic features, we introduce the IDentity-coupled Semantic Field (IDSF) into 3DGS, which captures both semantic representations and view-consistent instance indices for each Gaussian. We optimize IDSF with a two-step alternating strategy: semantics help to extract coherent instances in 3D space, while the resulting instances regularize the injection of stable semantics from 2D space. Additionally, we adopt a 2D-3D joint contrastive loss to enhance the complementarity between view-consistent 3D geometry and rich semantics during the bootstrapping process, enabling FreeGS to uniformly perform tasks such as novel-view semantic segmentation, object selection, and 3D object detection. Extensive experiments on LERF-Mask, 3D-OVS, and ScanNet datasets demonstrate that FreeGS performs comparably to state-of-the-art methods while avoiding the complex data preprocessing workload.