 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplete-muE: Optimal Hyperparameter Transfer and Scaling for MoE Models
May 22, 2026We propose Complete-muE, a framework which targets hyperparameter transfer across dense FFN and any Mixture-of-Experts (MoE) setups in transformer blocks. Existing tools such as $μ$P (requires fixed architectue) or SDE (requires fixed per-step token count) cannot directly solve the hyperparameter transfer problem in MoE setups because Dense to MoE transfer or MoE total experts scaling changes both architecture and tokens per expert. Complete-muE solves this challenge with a two-bridge system: Bridge~I maps between dense FFN and Dense MoE by active-width $μ$P with a normalized router scale. Bridge~II maps between Dense MoE and sparse MoE by activated-expert scaling, where the first-order SDE LR/WD correction cancels while a bounded residual $σ_0$ shift remains. The resulting transfer rule, which we term as Complete muE, covers changes in activated experts, total capacity, granularity, and shared/group-balanced hybrids for MoE models as well as network width/depth, batch size, and duration changes for general Transformer models. Extensive language model and diffusion model pretraining experiments confirm that complete-muE yields relatively stable hyperparameter optima across model architectures and parameter counts -- with only minor drift consistent with the non-strict SDE behavior of Bridge~II. In practice this drift is small enough that hyperparameters tuned on a single dense reference transfer near-optimally to all MoE configurations -- \emph{tune dense once, transfer to all} is the practical recipe at the core of Complete-muE. This enables MoE models to achieve accelerated convergence speedup over dense models when scaling model capacity without costly hyperparameter search.
Staggered Batch Scheduling: Co-optimizing Time-to-First-Token and Throughput for High-Efficiency LLM Inference
Dec 18, 2025



The evolution of Large Language Model (LLM) serving towards complex, distributed architectures--specifically the P/D-separated, large-scale DP+EP paradigm--introduces distinct scheduling challenges. Unlike traditional deployments where schedulers can treat instances as black boxes, DP+EP architectures exhibit high internal synchronization costs. We identify that immediate request dispatching in such systems leads to severe in-engine queuing and parallelization bubbles, degrading Time-to-First-Token (TTFT). To address this, we propose Staggered Batch Scheduling (SBS), a mechanism that deliberately buffers requests to form optimal execution batches. This temporal decoupling eliminates internal queuing bubbles without compromising throughput. Furthermore, leveraging the scheduling window created by buffering, we introduce a Load-Aware Global Allocation strategy that balances computational load across DP units for both Prefill and Decode phases. Deployed on a production H800 cluster serving Deepseek-V3, our system reduces TTFT by 30%-40% and improves throughput by 15%-20% compared to state-of-the-art immediate scheduling baselines.
ZipIR: Latent Pyramid Diffusion Transformer for High-Resolution Image Restoration
Apr 11, 2025Recent progress in generative models has significantly improved image restoration capabilities, particularly through powerful diffusion models that offer remarkable recovery of semantic details and local fidelity. However, deploying these models at ultra-high resolutions faces a critical trade-off between quality and efficiency due to the computational demands of long-range attention mechanisms. To address this, we introduce ZipIR, a novel framework that enhances efficiency, scalability, and long-range modeling for high-res image restoration. ZipIR employs a highly compressed latent representation that compresses image 32x, effectively reducing the number of spatial tokens, and enabling the use of high-capacity models like the Diffusion Transformer (DiT). Toward this goal, we propose a Latent Pyramid VAE (LP-VAE) design that structures the latent space into sub-bands to ease diffusion training. Trained on full images up to 2K resolution, ZipIR surpasses existing diffusion-based methods, offering unmatched speed and quality in restoring high-resolution images from severely degraded inputs.
EP-CFG: Energy-Preserving Classifier-Free Guidance
Dec 13, 2024



Classifier-free guidance (CFG) is widely used in diffusion models but often introduces over-contrast and over-saturation artifacts at higher guidance strengths. We present EP-CFG (Energy-Preserving Classifier-Free Guidance), which addresses these issues by preserving the energy distribution of the conditional prediction during the guidance process. Our method simply rescales the energy of the guided output to match that of the conditional prediction at each denoising step, with an optional robust variant for improved artifact suppression. Through experiments, we show that EP-CFG maintains natural image quality and preserves details across guidance strengths while retaining CFG's semantic alignment benefits, all with minimal computational overhead.
UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
Dec 10, 2024



We introduce UniReal, a unified framework designed to address various image generation and editing tasks. Existing solutions often vary by tasks, yet share fundamental principles: preserving consistency between inputs and outputs while capturing visual variations. Inspired by recent video generation models that effectively balance consistency and variation across frames, we propose a unifying approach that treats image-level tasks as discontinuous video generation. Specifically, we treat varying numbers of input and output images as frames, enabling seamless support for tasks such as image generation, editing, customization, composition, etc. Although designed for image-level tasks, we leverage videos as a scalable source for universal supervision. UniReal learns world dynamics from large-scale videos, demonstrating advanced capability in handling shadows, reflections, pose variation, and object interaction, while also exhibiting emergent capability for novel applications.
LayerFusion: Harmonized Multi-Layer Text-to-Image Generation with Generative Priors
Dec 05, 2024



Large-scale diffusion models have achieved remarkable success in generating high-quality images from textual descriptions, gaining popularity across various applications. However, the generation of layered content, such as transparent images with foreground and background layers, remains an under-explored area. Layered content generation is crucial for creative workflows in fields like graphic design, animation, and digital art, where layer-based approaches are fundamental for flexible editing and composition. In this paper, we propose a novel image generation pipeline based on Latent Diffusion Models (LDMs) that generates images with two layers: a foreground layer (RGBA) with transparency information and a background layer (RGB). Unlike existing methods that generate these layers sequentially, our approach introduces a harmonized generation mechanism that enables dynamic interactions between the layers for more coherent outputs. We demonstrate the effectiveness of our method through extensive qualitative and quantitative experiments, showing significant improvements in visual coherence, image quality, and layer consistency compared to baseline methods.
MetaShadow: Object-Centered Shadow Detection, Removal, and Synthesis
Dec 03, 2024



Shadows are often under-considered or even ignored in image editing applications, limiting the realism of the edited results. In this paper, we introduce MetaShadow, a three-in-one versatile framework that enables detection, removal, and controllable synthesis of shadows in natural images in an object-centered fashion. MetaShadow combines the strengths of two cooperative components: Shadow Analyzer, for object-centered shadow detection and removal, and Shadow Synthesizer, for reference-based controllable shadow synthesis. Notably, we optimize the learning of the intermediate features from Shadow Analyzer to guide Shadow Synthesizer to generate more realistic shadows that blend seamlessly with the scene. Extensive evaluations on multiple shadow benchmark datasets show significant improvements of MetaShadow over the existing state-of-the-art methods on object-centered shadow detection, removal, and synthesis. MetaShadow excels in image-editing tasks such as object removal, relocation, and insertion, pushing the boundaries of object-centered image editing.
Refine-by-Align: Reference-Guided Artifacts Refinement through Semantic Alignment
Nov 30, 2024


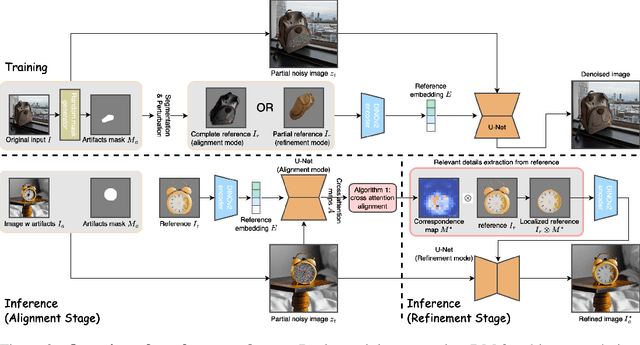
Personalized image generation has emerged from the recent advancements in generative models. However, these generated personalized images often suffer from localized artifacts such as incorrect logos, reducing fidelity and fine-grained identity details of the generated results. Furthermore, there is little prior work tackling this problem. To help improve these identity details in the personalized image generation, we introduce a new task: reference-guided artifacts refinement. We present Refine-by-Align, a first-of-its-kind model that employs a diffusion-based framework to address this challenge. Our model consists of two stages: Alignment Stage and Refinement Stage, which share weights of a unified neural network model. Given a generated image, a masked artifact region, and a reference image, the alignment stage identifies and extracts the corresponding regional features in the reference, which are then used by the refinement stage to fix the artifacts. Our model-agnostic pipeline requires no test-time tuning or optimization. It automatically enhances image fidelity and reference identity in the generated image, generalizing well to existing models on various tasks including but not limited to customization, generative compositing, view synthesis, and virtual try-on. Extensive experiments and comparisons demonstrate that our pipeline greatly pushes the boundary of fine details in the image synthesis models.
Generative Image Layer Decomposition with Visual Effects
Nov 26, 2024



Recent advancements in large generative models, particularly diffusion-based methods, have significantly enhanced the capabilities of image editing. However, achieving precise control over image composition tasks remains a challenge. Layered representations, which allow for independent editing of image components, are essential for user-driven content creation, yet existing approaches often struggle to decompose image into plausible layers with accurately retained transparent visual effects such as shadows and reflections. We propose $\textbf{LayerDecomp}$, a generative framework for image layer decomposition which outputs photorealistic clean backgrounds and high-quality transparent foregrounds with faithfully preserved visual effects. To enable effective training, we first introduce a dataset preparation pipeline that automatically scales up simulated multi-layer data with synthesized visual effects. To further enhance real-world applicability, we supplement this simulated dataset with camera-captured images containing natural visual effects. Additionally, we propose a consistency loss which enforces the model to learn accurate representations for the transparent foreground layer when ground-truth annotations are not available. Our method achieves superior quality in layer decomposition, outperforming existing approaches in object removal and spatial editing tasks across several benchmarks and multiple user studies, unlocking various creative possibilities for layer-wise image editing. The project page is https://rayjryang.github.io/LayerDecomp.
FINECAPTION: Compositional Image Captioning Focusing on Wherever You Want at Any Granularity
Nov 23, 2024



The advent of large Vision-Language Models (VLMs) has significantly advanced multimodal tasks, enabling more sophisticated and accurate reasoning across various applications, including image and video captioning, visual question answering, and cross-modal retrieval. Despite their superior capabilities, VLMs struggle with fine-grained image regional composition information perception. Specifically, they have difficulty accurately aligning the segmentation masks with the corresponding semantics and precisely describing the compositional aspects of the referred regions. However, compositionality - the ability to understand and generate novel combinations of known visual and textual components - is critical for facilitating coherent reasoning and understanding across modalities by VLMs. To address this issue, we propose FINECAPTION, a novel VLM that can recognize arbitrary masks as referential inputs and process high-resolution images for compositional image captioning at different granularity levels. To support this endeavor, we introduce COMPOSITIONCAP, a new dataset for multi-grained region compositional image captioning, which introduces the task of compositional attribute-aware regional image captioning. Empirical results demonstrate the effectiveness of our proposed model compared to other state-of-the-art VLMs. Additionally, we analyze the capabilities of current VLMs in recognizing various visual prompts for compositional region image captioning, highlighting areas for improvement in VLM design and training.