 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Text-to-Video Retrieval for Operating Room Clips via Action-Driven Digital Twins
Jun 15, 2026Text-to-video retrieval in operating rooms (OR) is an enabling technology for OR safety, as it allows stakeholders to retrieve and inspect recordings of specific events. However, because the most safety-critical events may not follow the common structure, to unlock its full potential text-to-video retrieval must be able to handle implicit queries that require reasoning to identify the right video (e.g., the step right before clipping). However, existing methods rely on global embeddings that cannot reason over such queries. We propose OR3, a text-to-video retrieval method that converts clips into action-driven digital twins (ActDTs), grouping concurrent subject-action-object triplets under non-overlapping temporal intervals. Moreover, rather than cross-modal matching through paired encoders, OR3 performs imagination-based retrieval where an LLM generates hypothetical ActDTs from queries. This enables intra-modal matching via a single encoder trained with ActDT-tailored hard negatives. Finally, evidence-grounded refinement revises imagined ActDTs based on discrepancies with top candidates to capture procedure-specific patterns. We construct a benchmark from MM-OR with 276 implicit queries across four reasoning categories over 386 clips from robotic knee procedures. OR3 achieves 57.6 R@1 and 77.3 R@5, outperforming the strongest baseline. These results demonstrate that OR3 enables fine-grained discrimination between visually similar OR video clips through temporal action reasoning.
Training LLMs with Reinforcement Learning over Digital Twin Representations for Reasoning-Intensive Surgical VideoQA
Jun 15, 2026Surgical video question answering requires multi-step reasoning across semantic, spatial, and temporal dimensions. Existing methods architecturally compress videos into discrete token representations and couple visual perception with reasoning. This approach fragments continuous spatial-temporal relationships and has been shown to restrict multi-step reasoning capabilities. We introduce a reinforcement learning (RL) framework that trains large language models (LLMs) to decouple perception from reasoning by operating over digital twin representations constructed from surgical foundation models. Additionally, we introduce hierarchical representations across frame, temporal window, and procedure levels with probabilistic uncertainty estimates. Finally, we propose a novel reward that combines format validation with accuracy assessment through clinical plausibility evaluation and uncertainty-aware calibration for training. To demonstrate the capabilities of this approach, we introduce REAL-Colon-Reason, a colonoscopic benchmark with 2000 question-answer pairs across three complexity levels. We achieve state-of-the-art performance on REAL-Colon-Reason and two existing surgical VideoQA benchmarks REAL-Colon-VQA and EndoVis18-VQA.
Open-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
AffordTissue: Dense Affordance Prediction for Tool-Action Specific Tissue Interaction
Apr 01, 2026Surgical action automation has progressed rapidly toward achieving surgeon-like dexterous control, driven primarily by advances in learning from demonstration and vision-language-action models. While these have demonstrated success in table-top experiments, translating them to clinical deployment remains challenging: current methods offer limited predictability on where instruments will interact on tissue surfaces and lack explicit conditioning inputs to enforce tool-action-specific safe interaction regions. Addressing this gap, we introduce AffordTissue, a multimodal framework for predicting tool-action specific tissue affordance regions as dense heatmaps during cholecystectomy. Our approach combines a temporal vision encoder capturing tool motion and tissue dynamics across multiple viewpoints, language conditioning enabling generalization across diverse instrument-action pairs, and a DiT-style decoder for dense affordance prediction. We establish the first tissue affordance benchmark by curating and annotating 15,638 video clips across 103 cholecystectomy procedures, covering six unique tool-action pairs involving four instruments (hook, grasper, scissors, clipper) and their associated tasks: dissection, grasping, clipping, and cutting. Experiments demonstrate substantial improvement over vision-language model baselines (20.6 px ASSD vs. 60.2 px for Molmo-VLM), showing that our task-specific architecture outperforms large-scale foundation models for dense surgical affordance prediction. By predicting tool-action specific tissue affordance regions, AffordTissue provides explicit spatial reasoning for safe surgical automation, potentially unlocking explicit policy guidance toward appropriate tissue regions and early safe stop when instruments deviate outside predicted safe zones.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
ProtRLSearch: A Multi-Round Multimodal Protein Search Agent with Large Language Models Trained via Reinforcement Learning
Mar 02, 2026Protein analysis tasks arising in healthcare settings often require accurate reasoning under protein sequence constraints, involving tasks such as functional interpretation of disease-related variants, protein-level analysis for clinical research, and similar scenarios. To address such tasks, search agents are introduced to search protein-related information, providing support for disease-related variant analysis and protein function reasoning in protein-centric inference. However, such search agents are mostly limited to single-round, text-only modality search, which prevents the protein sequence modality from being incorporated as a multimodal input into the search decision-making process. Meanwhile, their reliance on reinforcement learning (RL) supervision that focuses solely on the final answer results in a lack of search process constraints, making deviations in keyword selection and reasoning directions difficult to identify and correct in a timely manner. To address these limitations, we propose ProtRLSearch, a multi-round protein search agent trained with multi-dimensional reward based RL, which jointly leverages protein sequence and text as multimodal inputs during real-time search to produce high quality reports. To evaluate the ability of models to integrate protein sequence information and text-based multimodal inputs in realistic protein query settings, we construct ProtMCQs, a benchmark of 3,000 multiple choice questions (MCQs) organized into three difficulty levels. The benchmark evaluates protein query tasks that range from sequence constrained reasoning about protein function and phenotype changes to comprehensive protein reasoning that integrates multi-dimensional sequence features with signal pathways and regulatory networks.
Towards Controllable Video Synthesis of Routine and Rare OR Events
Feb 24, 2026Purpose: Curating large-scale datasets of operating room (OR) workflow, encompassing rare, safety-critical, or atypical events, remains operationally and ethically challenging. This data bottleneck complicates the development of ambient intelligence for detecting, understanding, and mitigating rare or safety-critical events in the OR. Methods: This work presents an OR video diffusion framework that enables controlled synthesis of rare and safety-critical events. The framework integrates a geometric abstraction module, a conditioning module, and a fine-tuned diffusion model to first transform OR scenes into abstract geometric representations, then condition the synthesis process, and finally generate realistic OR event videos. Using this framework, we also curate a synthetic dataset to train and validate AI models for detecting near-misses of sterile-field violations. Results: In synthesizing routine OR events, our method outperforms off-the-shelf video diffusion baselines, achieving lower FVD/LPIPS and higher SSIM/PSNR in both in- and out-of-domain datasets. Through qualitative results, we illustrate its ability for controlled video synthesis of counterfactual events. An AI model trained and validated on the generated synthetic data achieved a RECALL of 70.13% in detecting near safety-critical events. Finally, we conduct an ablation study to quantify performance gains from key design choices. Conclusion: Our solution enables controlled synthesis of routine and rare OR events from abstract geometric representations. Beyond demonstrating its capability to generate rare and safety-critical scenarios, we show its potential to support the development of ambient intelligence models.
Text-Driven Reasoning Video Editing via Reinforcement Learning on Digital Twin Representations
Nov 18, 2025Text-driven video editing enables users to modify video content only using text queries. While existing methods can modify video content if explicit descriptions of editing targets with precise spatial locations and temporal boundaries are provided, these requirements become impractical when users attempt to conceptualize edits through implicit queries referencing semantic properties or object relationships. We introduce reasoning video editing, a task where video editing models must interpret implicit queries through multi-hop reasoning to infer editing targets before executing modifications, and a first model attempting to solve this complex task, RIVER (Reasoning-based Implicit Video Editor). RIVER decouples reasoning from generation through digital twin representations of video content that preserve spatial relationships, temporal trajectories, and semantic attributes. A large language model then processes this representation jointly with the implicit query, performing multi-hop reasoning to determine modifications, then outputs structured instructions that guide a diffusion-based editor to execute pixel-level changes. RIVER training uses reinforcement learning with rewards that evaluate reasoning accuracy and generation quality. Finally, we introduce RVEBenchmark, a benchmark of 100 videos with 519 implicit queries spanning three levels and categories of reasoning complexity specifically for reasoning video editing. RIVER demonstrates best performance on the proposed RVEBenchmark and also achieves state-of-the-art performance on two additional video editing benchmarks (VegGIE and FiVE), where it surpasses six baseline methods.
Constructing and Interpreting Digital Twin Representations for Visual Reasoning via Reinforcement Learning
Nov 15, 2025Visual reasoning may require models to interpret images and videos and respond to implicit text queries across diverse output formats, from pixel-level segmentation masks to natural language descriptions. Existing approaches rely on supervised fine-tuning with task-specific architectures. For example, reasoning segmentation, grounding, summarization, and visual question answering each demand distinct model designs and training, preventing unified solutions and limiting cross-task and cross-modality generalization. Hence, we propose DT-R1, a reinforcement learning framework that trains large language models to construct digital twin representations of complex multi-modal visual inputs and then reason over these high-level representations as a unified approach to visual reasoning. Specifically, we train DT-R1 using GRPO with a novel reward that validates both structural integrity and output accuracy. Evaluations in six visual reasoning benchmarks, covering two modalities and four task types, demonstrate that DT-R1 consistently achieves improvements over state-of-the-art task-specific models. DT-R1 opens a new direction where visual reasoning emerges from reinforcement learning with digital twin representations.
Fast Reasoning Segmentation for Images and Videos
Nov 15, 2025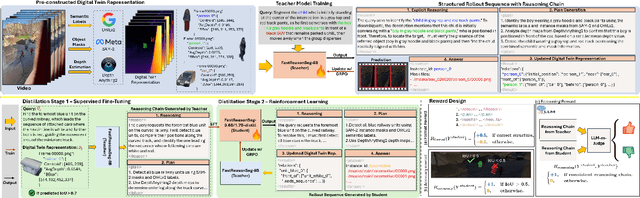
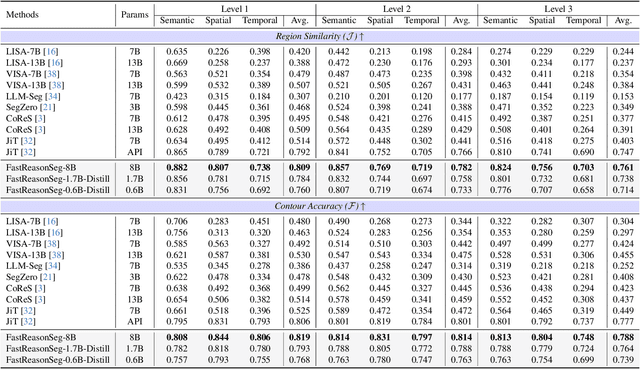
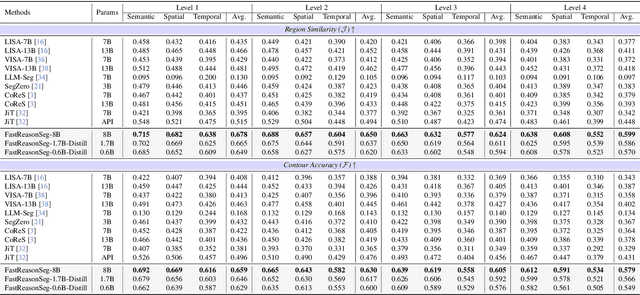

Reasoning segmentation enables open-set object segmentation via implicit text queries, therefore serving as a foundation for embodied agents that should operate autonomously in real-world environments. However, existing methods for reasoning segmentation require multimodal large language models with billions of parameters that exceed the computational capabilities of edge devices that typically deploy the embodied AI systems. Distillation offers a pathway to compress these models while preserving their capabilities. Yet, existing distillation approaches fail to transfer the multi-step reasoning capabilities that reasoning segmentation demands, as they focus on matching output predictions and intermediate features rather than preserving reasoning chains. The emerging paradigm of reasoning over digital twin representations presents an opportunity for more effective distillation by re-framing the problem. Consequently, we propose FastReasonSeg, which employs digital twin representations that decouple perception from reasoning to enable more effective distillation. Our distillation scheme first relies on supervised fine-tuning on teacher-generated reasoning chains. Then it is followed by reinforcement fine-tuning with joint rewards evaluating both segmentation accuracy and reasoning quality alignment. Experiments on two video (JiTBench, RVTBench) and two image benchmarks (ReasonSeg, LLM-Seg40K) demonstrate that our FastReasonSeg achieves state-of-the-art reasoning segmentation performance. Moreover, the distilled 0.6B variant outperforms models with 20 times more parameters while achieving 7.79 FPS throughput with only 2.1GB memory consumption. This efficiency enables deployment in resource-constrained environments to enable real-time reasoning segmentation.