 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Second Monocular Depth Estimation Challenge
Apr 26, 2023
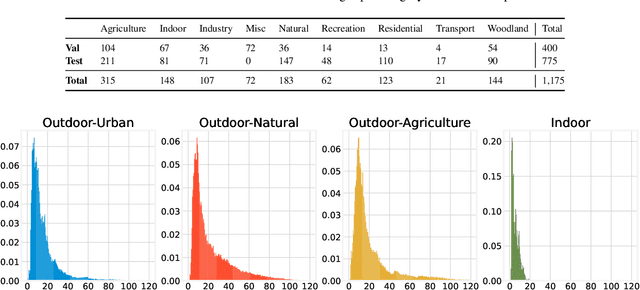
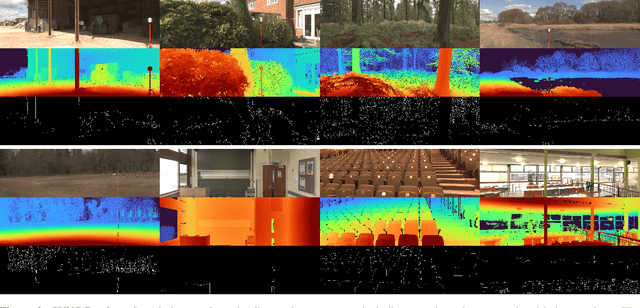
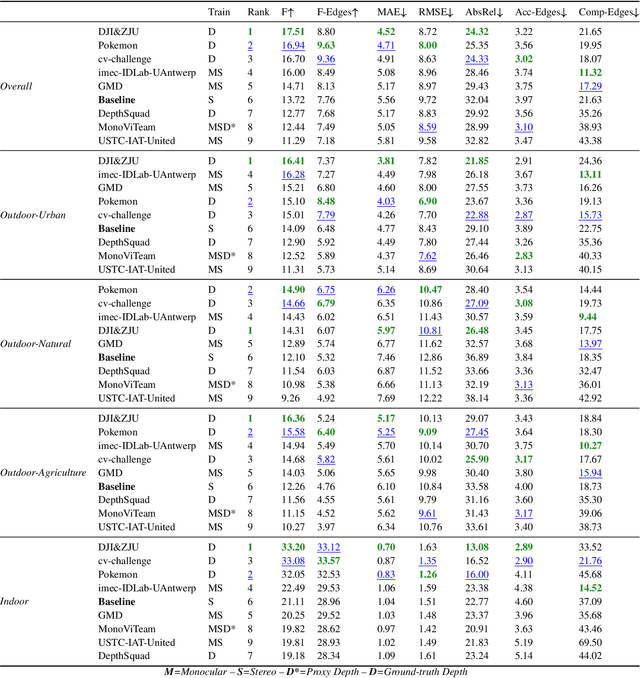
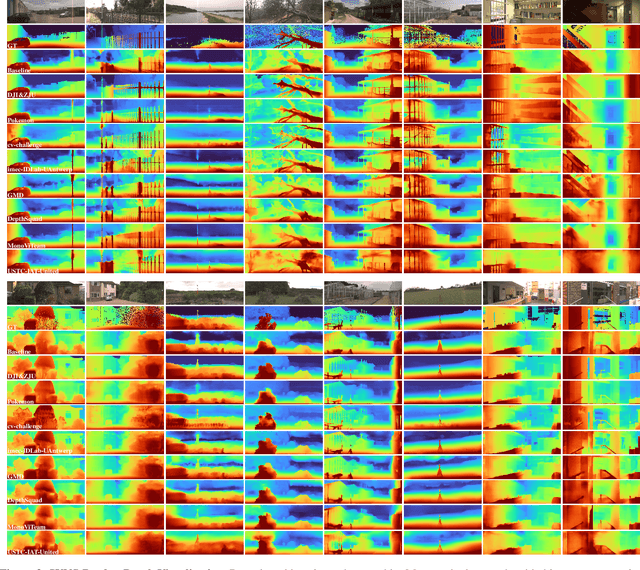
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
Multi-spectral Class Center Network for Face Manipulation Detection and Localization
May 18, 2023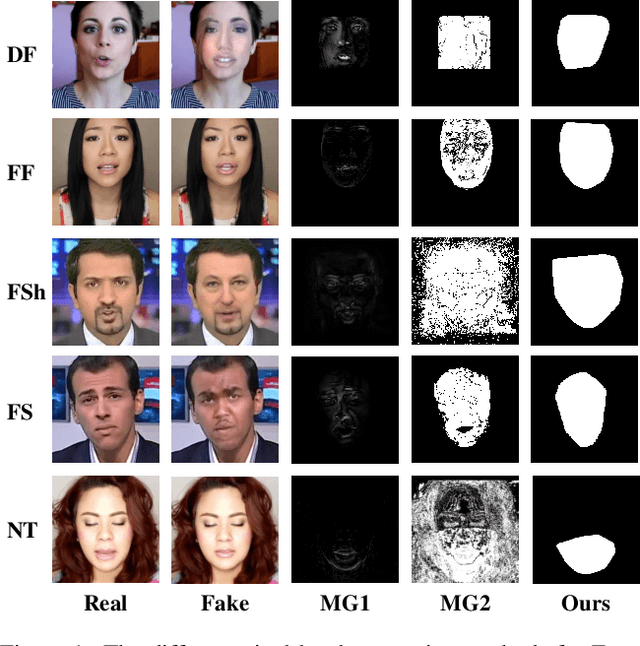
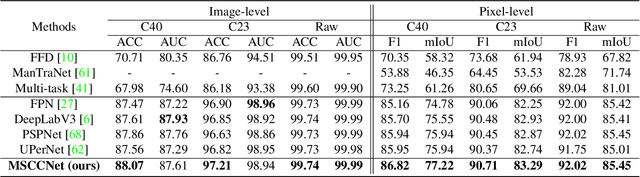
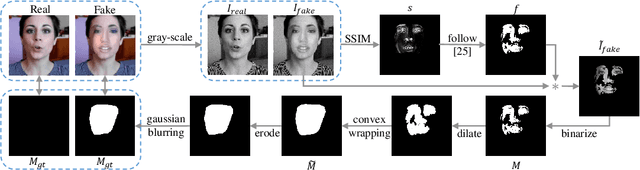

As Deepfake contents continue to proliferate on the internet, advancing face manipulation forensics has become a pressing issue. To combat this emerging threat, previous methods mainly focus on studying how to distinguish authentic and manipulated face images. Despite impressive, image-level classification lacks explainability and is limited to some specific application scenarios. Existing forgery localization methods suffer from imprecise and inconsistent pixel-level annotations. To alleviate these problems, this paper first re-constructs the FaceForensics++ dataset by introducing pixel-level annotations, then builds an extensive benchmark for localizing tampered regions. Next, a novel Multi-Spectral Class Center Network (MSCCNet) is proposed for face manipulation detection and localization. Specifically, inspired by the power of frequency-related forgery traces, we design Multi-Spectral Class Center (MSCC) module to learn more generalizable and semantic-agnostic features. Based on the features of different frequency bands, the MSCC module collects multispectral class centers and computes pixel-to-class relations. Applying multi-spectral class-level representations suppresses the semantic information of the visual concepts, which is insensitive to manipulations. Furthermore, we propose a Multi-level Features Aggregation (MFA) module to employ more low-level forgery artifacts and structure textures. Experimental results quantitatively and qualitatively indicate the effectiveness and superiority of the proposed MSCCNet on comprehensive localization benchmarks. We expect this work to inspire more studies on pixel-level face manipulation localization. The annotations and code will be available.
Parallel development of social preferences in fish and machines
May 18, 2023
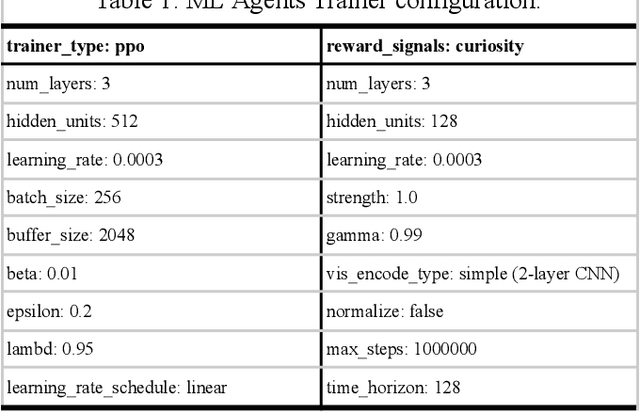
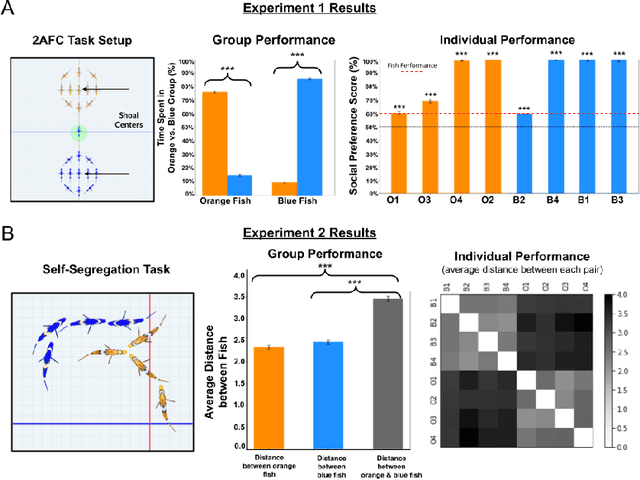
What are the computational foundations of social grouping? Traditional approaches to this question have focused on verbal reasoning or simple (low-dimensional) quantitative models. In the real world, however, social preferences emerge when high-dimensional learning systems (brains and bodies) interact with high-dimensional sensory inputs during an animal's embodied interactions with the world. A deep understanding of social grouping will therefore require embodied models that learn directly from sensory inputs using high-dimensional learning mechanisms. To this end, we built artificial neural networks (ANNs), embodied those ANNs in virtual fish bodies, and raised the artificial fish in virtual fish tanks that mimicked the rearing conditions of real fish. We then compared the social preferences that emerged in real fish versus artificial fish. We found that when artificial fish had two core learning mechanisms (reinforcement learning and curiosity-driven learning), artificial fish developed fish-like social preferences. Like real fish, the artificial fish spontaneously learned to prefer members of their own group over members of other groups. The artificial fish also spontaneously learned to self-segregate with their in-group, akin to self-segregation behavior seen in nature. Our results suggest that social grouping can emerge from three ingredients: (1) reinforcement learning, (2) intrinsic motivation, and (3) early social experiences with in-group members. This approach lays a foundation for reverse engineering animal-like social behavior with image-computable models, bridging the divide between high-dimensional sensory inputs and social preferences.
mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video
Feb 01, 2023
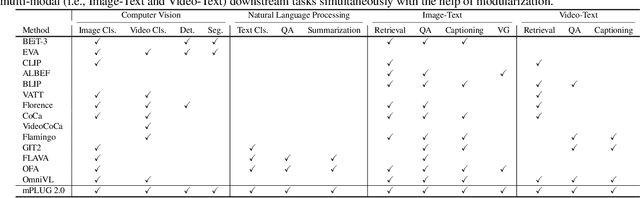
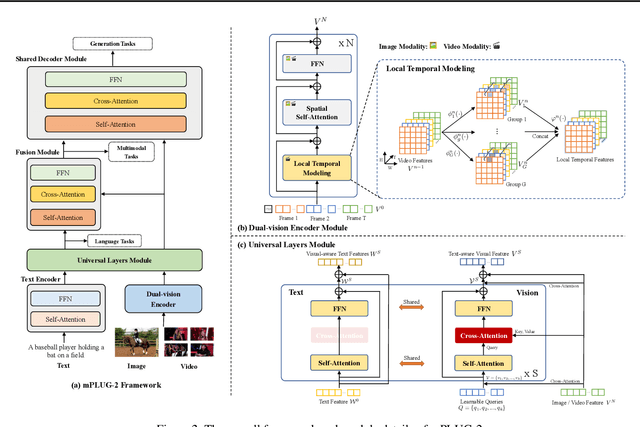

Recent years have witnessed a big convergence of language, vision, and multi-modal pretraining. In this work, we present mPLUG-2, a new unified paradigm with modularized design for multi-modal pretraining, which can benefit from modality collaboration while addressing the problem of modality entanglement. In contrast to predominant paradigms of solely relying on sequence-to-sequence generation or encoder-based instance discrimination, mPLUG-2 introduces a multi-module composition network by sharing common universal modules for modality collaboration and disentangling different modality modules to deal with modality entanglement. It is flexible to select different modules for different understanding and generation tasks across all modalities including text, image, and video. Empirical study shows that mPLUG-2 achieves state-of-the-art or competitive results on a broad range of over 30 downstream tasks, spanning multi-modal tasks of image-text and video-text understanding and generation, and uni-modal tasks of text-only, image-only, and video-only understanding. Notably, mPLUG-2 shows new state-of-the-art results of 48.0 top-1 accuracy and 80.3 CIDEr on the challenging MSRVTT video QA and video caption tasks with a far smaller model size and data scale. It also demonstrates strong zero-shot transferability on vision-language and video-language tasks. Code and models will be released in https://github.com/alibaba/AliceMind.
Invariant Representations in Deep Learning for Optoacoustic Imaging
Apr 29, 2023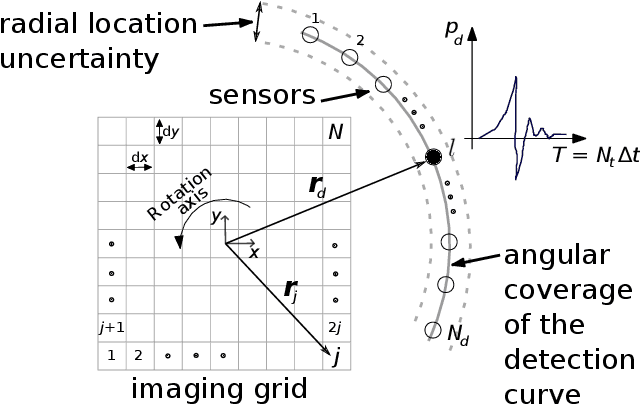

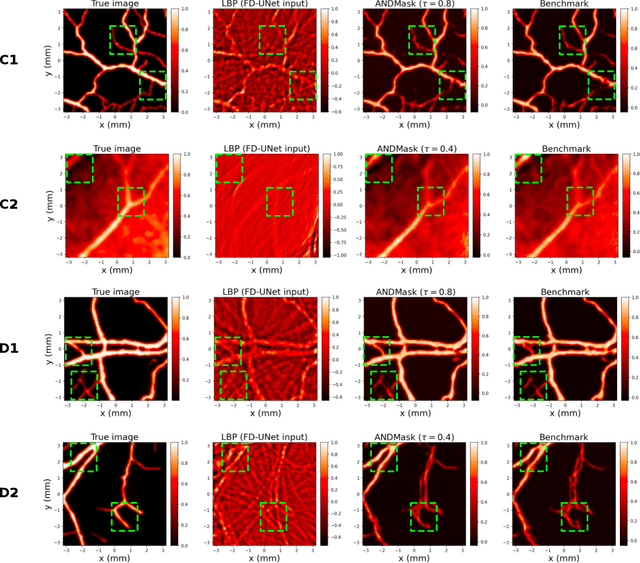
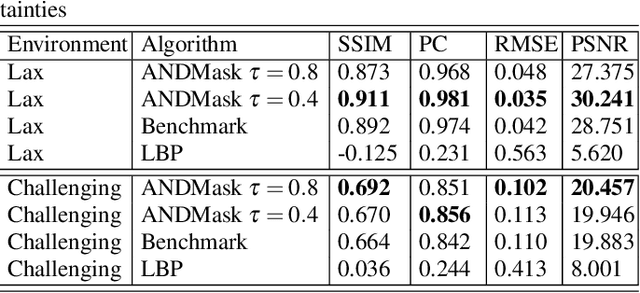
Image reconstruction in optoacoustic tomography (OAT) is a trending learning task highly dependent on measured physical magnitudes present at sensing time. The large number of different settings, and also the presence of uncertainties or partial knowledge of parameters, can lead to reconstructions algorithms that are specifically tailored and designed to a particular configuration which could not be the one that will be ultimately faced in a final practical situation. Being able to learn reconstruction algorithms that are robust to different environments (e.g. the different OAT image reconstruction settings) or invariant to such environments is highly valuable because it allows to focus on what truly matters for the application at hand and discard what are considered spurious features. In this work we explore the use of deep learning algorithms based on learning invariant and robust representations for the OAT inverse problem. In particular, we consider the application of the ANDMask scheme due to its easy adaptation to the OAT problem. Numerical experiments are conducted showing that, when out-of-distribution generalization (against variations in parameters such as the location of the sensors) is imposed, there is no degradation of the performance and, in some cases, it is even possible to achieve improvements with respect to standard deep learning approaches where invariance robustness is not explicitly considered.
Use the Detection Transformer as a Data Augmenter
Apr 10, 2023
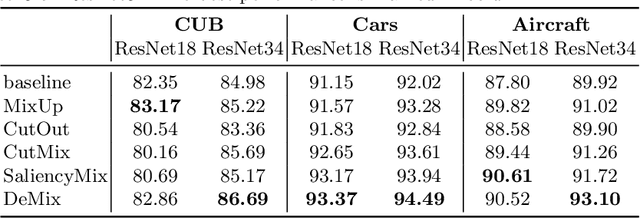
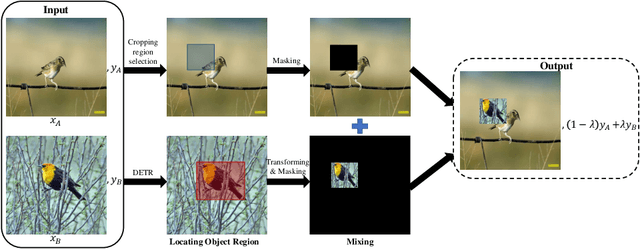
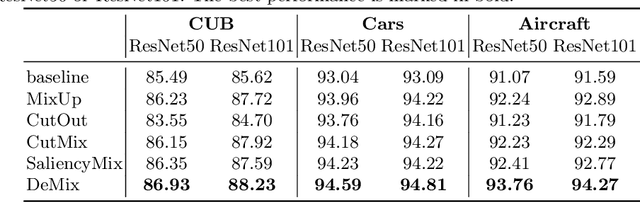
Detection Transformer (DETR) is a Transformer architecture based object detection model. In this paper, we demonstrate that it can also be used as a data augmenter. We term our approach as DETR assisted CutMix, or DeMix for short. DeMix builds on CutMix, a simple yet highly effective data augmentation technique that has gained popularity in recent years. CutMix improves model performance by cutting and pasting a patch from one image onto another, yielding a new image. The corresponding label for this new example is specified as the weighted average of the original labels, where the weight is proportional to the area of the patches. CutMix selects a random patch to be cut. In contrast, DeMix elaborately selects a semantically rich patch, located by a pre-trained DETR. The label of the new image is specified in the same way as in CutMix. Experimental results on benchmark datasets for image classification demonstrate that DeMix significantly outperforms prior art data augmentation methods including CutMix.
Target-Free Text-guided Image Manipulation
Dec 01, 2022
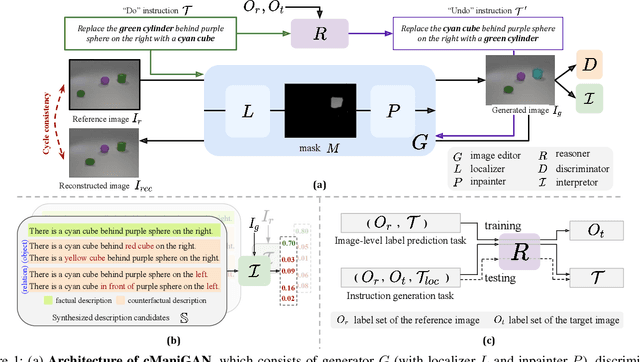

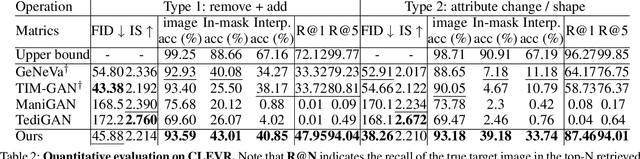
We tackle the problem of target-free text-guided image manipulation, which requires one to modify the input reference image based on the given text instruction, while no ground truth target image is observed during training. To address this challenging task, we propose a Cyclic-Manipulation GAN (cManiGAN) in this paper, which is able to realize where and how to edit the image regions of interest. Specifically, the image editor in cManiGAN learns to identify and complete the input image, while cross-modal interpreter and reasoner are deployed to verify the semantic correctness of the output image based on the input instruction. While the former utilizes factual/counterfactual description learning for authenticating the image semantics, the latter predicts the "undo" instruction and provides pixel-level supervision for the training of cManiGAN. With such operational cycle-consistency, our cManiGAN can be trained in the above weakly supervised setting. We conduct extensive experiments on the datasets of CLEVR and COCO, and the effectiveness and generalizability of our proposed method can be successfully verified. Project page: https://sites.google.com/view/wancyuanfan/projects/cmanigan.
Self-supervised Learning for Gastrointestinal Pathologies Endoscopy Image Classification with Triplet Loss
Mar 03, 2023



Recently, the amount of GI tract datasets is introduced more and more by gathering from contests and challenges. The most common task needs to solve that is to classify images from the GI tract into various classes. However, the contributions of the existing approaches exhibit lots of limitations. In this paper, we aim to develop a computer-aided diagnosis system to classify the pathological findings in endoscopy images, the system can classify some common pathologies including polyps, esophagitis, and ulcerative -- colitis. To evaluate the proposed work, we use the public dataset which is Hyper--Kvasir instead of gathering the data. The key idea of our system is to develop self-supervised learning based on the Barlow Twins framework with a downstream task which is an endoscopy image classification integrated with triplet loss and focal loss functions. The self-supervision framework and focal loss function are used to overcome class-imbalanced data, while the triplet loss function is to tackle the domain-specific properties in endoscopy images which are inter/intra class problems. An extensive experimental study on the pathological finding images in the Hyper--Kvasir dataset has shown that our proposed system is in general better than the compared methods, whereas using a simple neural network model. This means the proposed system can be used efficiently and capable of accurately for the classification of pathology images in the GI tract.
GULP: Solar-Powered Smart Garbage Segregation Bins with SMS Notification and Machine Learning Image Processing
Apr 25, 2023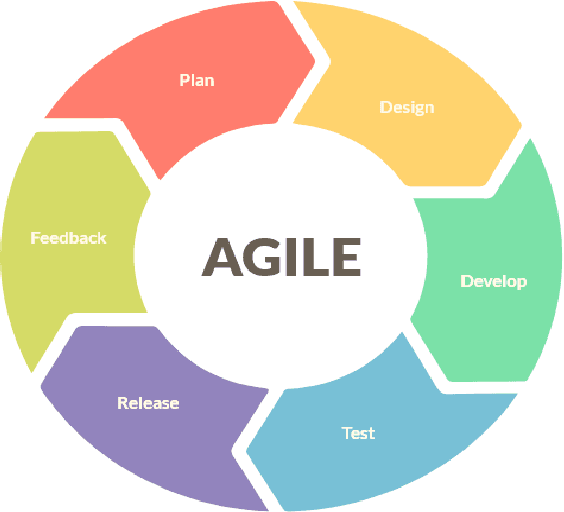
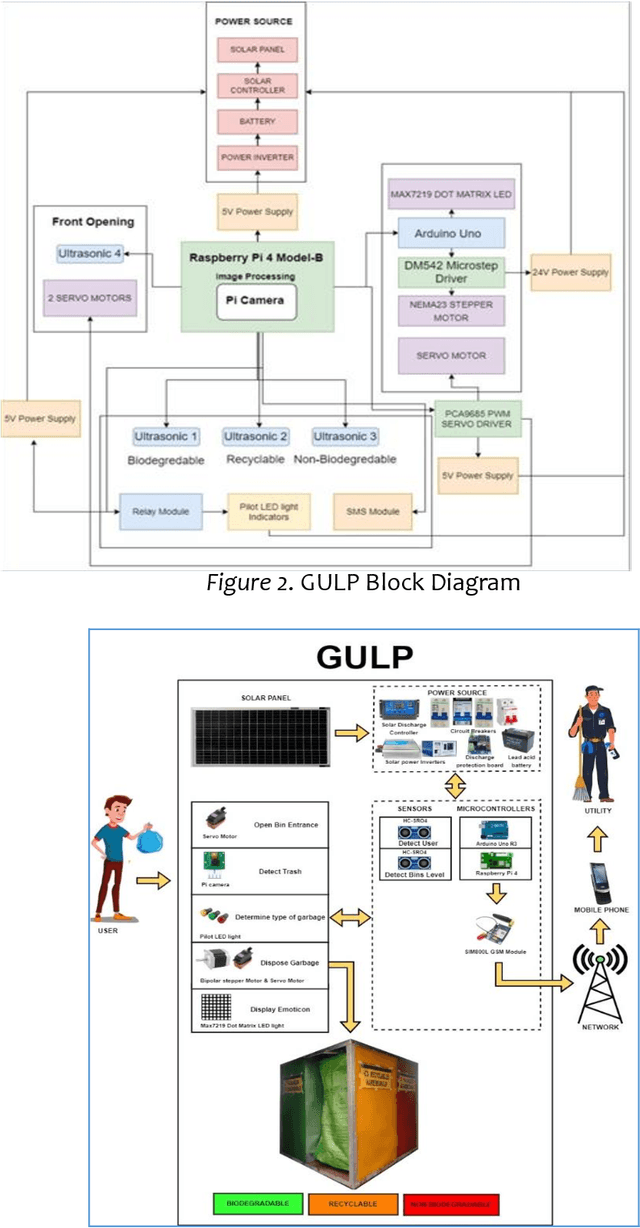
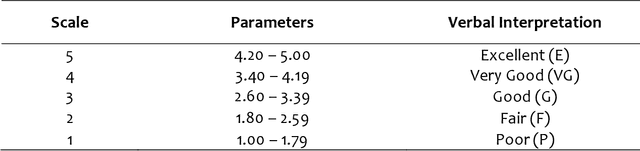
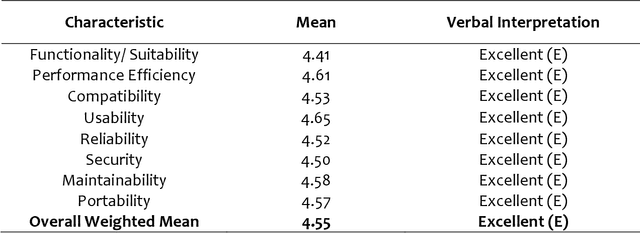
This study intends to build a smartbin that segregates solid waste into its respective bins. To make the waste management process more interesting for the end-users; to notify the utility staff when the smart bin needs to be unloaded; to encourage an environment-friendly smart bin by utilizing renewable solar energy source. The researchers employed an Agile Development approach because it enables teams to manage their workloads successfully and create the highest-quality product while staying within their allocated budget. The six fundamental phases are planning, design, development, test, release, and feedback. The Overall quality testing result that was provided through the ISO/IEC 25010 evaluation which concludes a positive outcome. The overall average was 4.55, which is verbally interpreted as excellent. Additionally, the application can also independently run with its solar energy source. Users were able to enjoy the whole process of waste disposal through its interesting mechanisms. Based on the findings, a compressor is recommended to compress the trash when the trash level reaches its maximum point to create more rooms for more garbage. An algorithm to determine multiple garbage at a time is also recommended. Adding a solar tracker coupled with solar panel will help produce more renewable energy for the smart bin.
* 19 pages, 6 figures, International Research Conference on Computer Engineering and Technology Education2023 (IRCCETE 2023)
A2S-NAS: Asymmetric Spectral-Spatial Neural Architecture Search For Hyperspectral Image Classification
Feb 23, 2023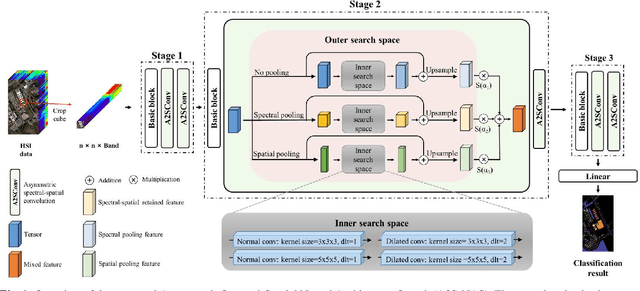
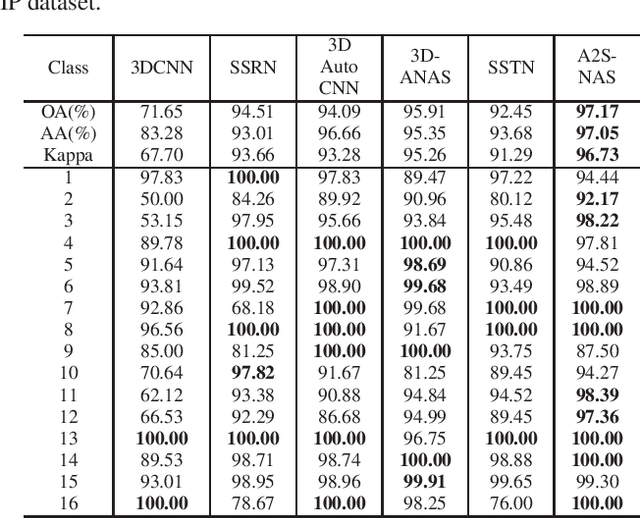
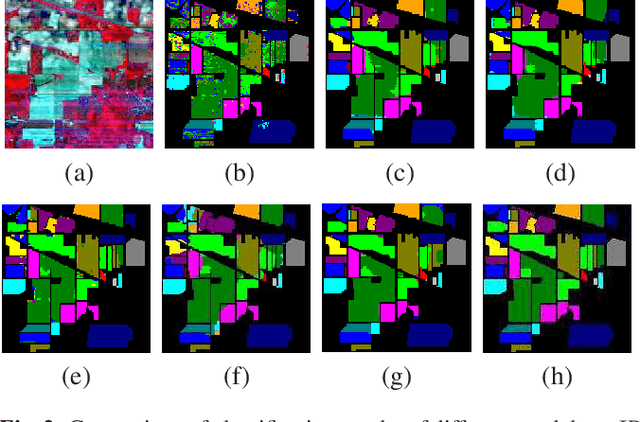
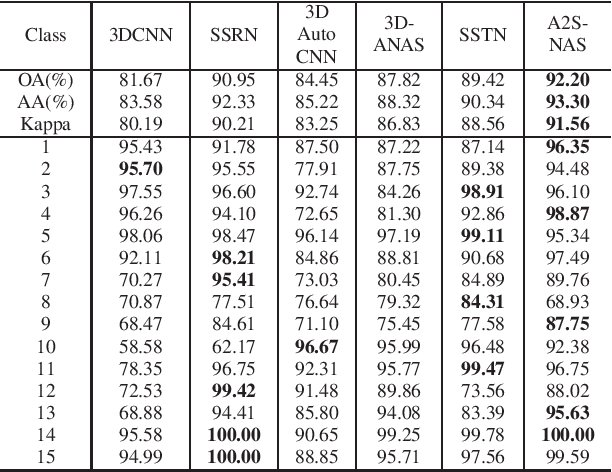
Existing deep learning-based hyperspectral image (HSI) classification works still suffer from the limitation of the fixed-sized receptive field, leading to difficulties in distinctive spectral-spatial features for ground objects with various sizes and arbitrary shapes. Meanwhile, plenty of previous works ignore asymmetric spectral-spatial dimensions in HSI. To address the above issues, we propose a multi-stage search architecture in order to overcome asymmetric spectral-spatial dimensions and capture significant features. First, the asymmetric pooling on the spectral-spatial dimension maximally retains the essential features of HSI. Then, the 3D convolution with a selectable range of receptive fields overcomes the constraints of fixed-sized convolution kernels. Finally, we extend these two searchable operations to different layers of each stage to build the final architecture. Extensive experiments are conducted on two challenging HSI benchmarks including Indian Pines and Houston University, and results demonstrate the effectiveness of the proposed method with superior performance compared with the related works.