 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structured Reasoning via Tractable Trajectory Control
Mar 02, 2026Large language models can exhibit emergent reasoning behaviors, often manifested as recurring lexical patterns (e.g., "wait," indicating verification). However, complex reasoning trajectories remain sparse in unconstrained sampling, and standard RL often fails to guarantee the acquisition of diverse reasoning behaviors. We propose a systematic discovery and reinforcement of diverse reasoning patterns through structured reasoning, a paradigm that requires targeted exploration of specific reasoning patterns during the RL process. To this end, we propose Ctrl-R, a framework for learning structured reasoning via tractable trajectory control that actively guides the rollout process, incentivizing the exploration of diverse reasoning patterns that are critical for complex problem-solving. The resulting behavior policy enables accurate importance-sampling estimation, supporting unbiased on-policy optimization. We further introduce a power-scaling factor on the importance-sampling weights, allowing the policy to selectively learn from exploratory, out-of-distribution trajectories while maintaining stable optimization. Experiments demonstrate that Ctrl-R enables effective exploration and internalization of previously unattainable reasoning patterns, yielding consistent improvements across language and vision-language models on mathematical reasoning tasks.
Pushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning
Dec 22, 2025We introduce Perception Encoder Audiovisual, PE-AV, a new family of encoders for audio and video understanding trained with scaled contrastive learning. Built on PE, PE-AV makes several key contributions to extend representations to audio, and natively support joint embeddings across audio-video, audio-text, and video-text modalities. PE-AV's unified cross-modal embeddings enable novel tasks such as speech retrieval, and set a new state of the art across standard audio and video benchmarks. We unlock this by building a strong audiovisual data engine that synthesizes high-quality captions for O(100M) audio-video pairs, enabling large-scale supervision consistent across modalities. Our audio data includes speech, music, and general sound effects-avoiding single-domain limitations common in prior work. We exploit ten pairwise contrastive objectives, showing that scaling cross-modality and caption-type pairs strengthens alignment and improves zero-shot performance. We further develop PE-A-Frame by fine-tuning PE-AV with frame-level contrastive objectives, enabling fine-grained audio-frame-to-text alignment for tasks such as sound event detection.
Customize Multi-modal RAI Guardrails with Precedent-based predictions
Jul 28, 2025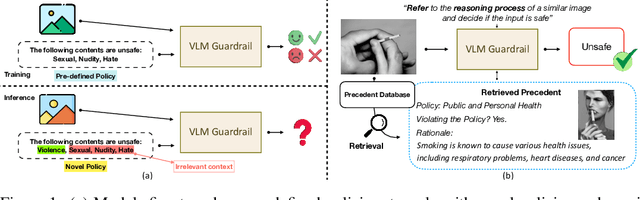
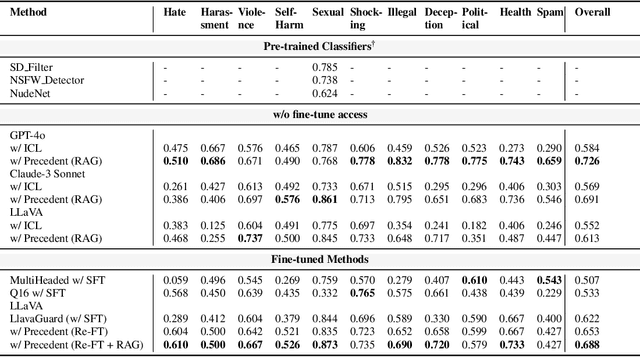
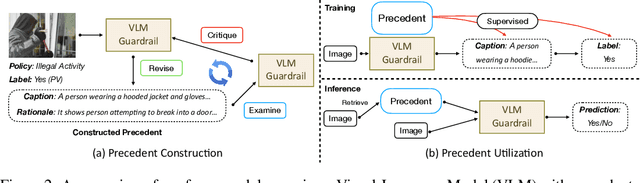
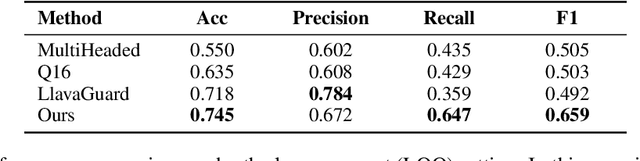
A multi-modal guardrail must effectively filter image content based on user-defined policies, identifying material that may be hateful, reinforce harmful stereotypes, contain explicit material, or spread misinformation. Deploying such guardrails in real-world applications, however, poses significant challenges. Users often require varied and highly customizable policies and typically cannot provide abundant examples for each custom policy. Consequently, an ideal guardrail should be scalable to the multiple policies and adaptable to evolving user standards with minimal retraining. Existing fine-tuning methods typically condition predictions on pre-defined policies, restricting their generalizability to new policies or necessitating extensive retraining to adapt. Conversely, training-free methods struggle with limited context lengths, making it difficult to incorporate all the policies comprehensively. To overcome these limitations, we propose to condition model's judgment on "precedents", which are the reasoning processes of prior data points similar to the given input. By leveraging precedents instead of fixed policies, our approach greatly enhances the flexibility and adaptability of the guardrail. In this paper, we introduce a critique-revise mechanism for collecting high-quality precedents and two strategies that utilize precedents for robust prediction. Experimental results demonstrate that our approach outperforms previous methods across both few-shot and full-dataset scenarios and exhibits superior generalization to novel policies.
Learning to Rank Chain-of-Thought: An Energy-Based Approach with Outcome Supervision
May 21, 2025Mathematical reasoning presents a significant challenge for Large Language Models (LLMs), often requiring robust multi step logical consistency. While Chain of Thought (CoT) prompting elicits reasoning steps, it doesn't guarantee correctness, and improving reliability via extensive sampling is computationally costly. This paper introduces the Energy Outcome Reward Model (EORM), an effective, lightweight, post hoc verifier. EORM leverages Energy Based Models (EBMs) to simplify the training of reward models by learning to assign a scalar energy score to CoT solutions using only outcome labels, thereby avoiding detailed annotations. It achieves this by interpreting discriminator output logits as negative energies, effectively ranking candidates where lower energy is assigned to solutions leading to correct final outcomes implicitly favoring coherent reasoning. On mathematical benchmarks (GSM8k, MATH), EORM significantly improves final answer accuracy (e.g., with Llama 3 8B, achieving 90.7% on GSM8k and 63.7% on MATH). EORM effectively leverages a given pool of candidate solutions to match or exceed the performance of brute force sampling, thereby enhancing LLM reasoning outcome reliability through its streamlined post hoc verification process.
Verbalized Representation Learning for Interpretable Few-Shot Generalization
Nov 27, 2024



Humans recognize objects after observing only a few examples, a remarkable capability enabled by their inherent language understanding of the real-world environment. Developing verbalized and interpretable representation can significantly improve model generalization in low-data settings. In this work, we propose Verbalized Representation Learning (VRL), a novel approach for automatically extracting human-interpretable features for object recognition using few-shot data. Our method uniquely captures inter-class differences and intra-class commonalities in the form of natural language by employing a Vision-Language Model (VLM) to identify key discriminative features between different classes and shared characteristics within the same class. These verbalized features are then mapped to numeric vectors through the VLM. The resulting feature vectors can be further utilized to train and infer with downstream classifiers. Experimental results show that, at the same model scale, VRL achieves a 24% absolute improvement over prior state-of-the-art methods while using 95% less data and a smaller mode. Furthermore, compared to human-labeled attributes, the features learned by VRL exhibit a 20% absolute gain when used for downstream classification tasks. Code is available at: https://github.com/joeyy5588/VRL/tree/main.
Towards a Holistic Framework for Multimodal Large Language Models in Three-dimensional Brain CT Report Generation
Jul 02, 2024Multi-modal large language models (MLLMs) have been given free rein to explore exciting medical applications with a primary focus on radiology report generation. Nevertheless, the preliminary success in 2D radiology captioning is incompetent to reflect the real-world diagnostic challenge in the volumetric 3D anatomy. To mitigate three crucial limitation aspects in the existing literature, including (1) data complexity, (2) model capacity, and (3) evaluation metric fidelity, we collected an 18,885 text-scan pairs 3D-BrainCT dataset and applied clinical visual instruction tuning (CVIT) to train BrainGPT models to generate radiology-adherent 3D brain CT reports. Statistically, our BrainGPT scored BLEU-1 = 44.35, BLEU-4 = 20.38, METEOR = 30.13, ROUGE-L = 47.6, and CIDEr-R = 211.77 during internal testing and demonstrated an accuracy of 0.91 in captioning midline shifts on the external validation CQ500 dataset. By further inspecting the captioned report, we reported that the traditional metrics appeared to measure only the surface text similarity and failed to gauge the information density of the diagnostic purpose. To close this gap, we proposed a novel Feature-Oriented Radiology Task Evaluation (FORTE) to estimate the report's clinical relevance (lesion feature and landmarks). Notably, the BrainGPT model scored an average FORTE F1-score of 0.71 (degree=0.661; landmark=0.706; feature=0.693; impression=0.779). To demonstrate that BrainGPT models possess objective readiness to generate human-like radiology reports, we conducted a Turing test that enrolled 11 physician evaluators, and around 74% of the BrainGPT-generated captions were indistinguishable from those written by humans. Our work embodies a holistic framework that showcased the first-hand experience of curating a 3D brain CT dataset, fine-tuning anatomy-sensible language models, and proposing robust radiology evaluation metrics.
LLM-A*: Large Language Model Enhanced Incremental Heuristic Search on Path Planning
Jun 20, 2024Path planning is a fundamental scientific problem in robotics and autonomous navigation, requiring the derivation of efficient routes from starting to destination points while avoiding obstacles. Traditional algorithms like A* and its variants are capable of ensuring path validity but suffer from significant computational and memory inefficiencies as the state space grows. Conversely, large language models (LLMs) excel in broader environmental analysis through contextual understanding, providing global insights into environments. However, they fall short in detailed spatial and temporal reasoning, often leading to invalid or inefficient routes. In this work, we propose LLM-A*, an new LLM based route planning method that synergistically combines the precise pathfinding capabilities of A* with the global reasoning capability of LLMs. This hybrid approach aims to enhance pathfinding efficiency in terms of time and space complexity while maintaining the integrity of path validity, especially in large-scale scenarios. By integrating the strengths of both methodologies, LLM-A* addresses the computational and memory limitations of conventional algorithms without compromising on the validity required for effective pathfinding.
Reflection-Reinforced Self-Training for Language Agents
Jun 03, 2024



Self-training can potentially improve the performance of language agents without relying on demonstrations from humans or stronger models. The general process involves generating samples from a model, evaluating their quality, and updating the model by training on high-quality samples. However, self-training can face limitations because achieving good performance requires a good amount of high-quality samples, yet relying solely on model sampling for obtaining such samples can be inefficient. In addition, these methods often disregard low-quality samples, failing to leverage them effectively. To address these limitations, we present Reflection-Reinforced Self-Training (Re-ReST), which leverages a reflection model to refine low-quality samples and subsequently uses these improved samples to augment self-training. The reflection model takes both the model output and feedback from an external environment (e.g., unit test results in code generation) as inputs and produces improved samples as outputs. By employing this technique, we effectively enhance the quality of inferior samples, and enrich the self-training dataset with higher-quality samples efficiently. We perform extensive experiments on open-source language agents across tasks, including multi-hop question answering, sequential decision-making, code generation, visual question answering, and text-to-image generation. Results demonstrate improvements over self-training baselines across settings. Moreover, ablation studies confirm the reflection model's efficiency in generating quality self-training samples and its compatibility with self-consistency decoding.
Planning as In-Painting: A Diffusion-Based Embodied Task Planning Framework for Environments under Uncertainty
Dec 02, 2023Task planning for embodied AI has been one of the most challenging problems where the community does not meet a consensus in terms of formulation. In this paper, we aim to tackle this problem with a unified framework consisting of an end-to-end trainable method and a planning algorithm. Particularly, we propose a task-agnostic method named 'planning as in-painting'. In this method, we use a Denoising Diffusion Model (DDM) for plan generation, conditioned on both language instructions and perceptual inputs under partially observable environments. Partial observation often leads to the model hallucinating the planning. Therefore, our diffusion-based method jointly models both state trajectory and goal estimation to improve the reliability of the generated plan, given the limited available information at each step. To better leverage newly discovered information along the plan execution for a higher success rate, we propose an on-the-fly planning algorithm to collaborate with the diffusion-based planner. The proposed framework achieves promising performances in various embodied AI tasks, including vision-language navigation, object manipulation, and task planning in a photorealistic virtual environment. The code is available at: https://github.com/joeyy5588/planning-as-inpainting.
LACMA: Language-Aligning Contrastive Learning with Meta-Actions for Embodied Instruction Following
Oct 18, 2023



End-to-end Transformers have demonstrated an impressive success rate for Embodied Instruction Following when the environment has been seen in training. However, they tend to struggle when deployed in an unseen environment. This lack of generalizability is due to the agent's insensitivity to subtle changes in natural language instructions. To mitigate this issue, we propose explicitly aligning the agent's hidden states with the instructions via contrastive learning. Nevertheless, the semantic gap between high-level language instructions and the agent's low-level action space remains an obstacle. Therefore, we further introduce a novel concept of meta-actions to bridge the gap. Meta-actions are ubiquitous action patterns that can be parsed from the original action sequence. These patterns represent higher-level semantics that are intuitively aligned closer to the instructions. When meta-actions are applied as additional training signals, the agent generalizes better to unseen environments. Compared to a strong multi-modal Transformer baseline, we achieve a significant 4.5% absolute gain in success rate in unseen environments of ALFRED Embodied Instruction Following. Additional analysis shows that the contrastive objective and meta-actions are complementary in achieving the best results, and the resulting agent better aligns its states with corresponding instructions, making it more suitable for real-world embodied agents. The code is available at: https://github.com/joeyy5588/LACMA.