 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextCrafter: Accurately Rendering Multiple Texts in Complex Visual Scenes
Apr 01, 2025This paper explores the task of Complex Visual Text Generation (CVTG), which centers on generating intricate textual content distributed across diverse regions within visual images. In CVTG, image generation models often rendering distorted and blurred visual text or missing some visual text. To tackle these challenges, we propose TextCrafter, a novel multi-visual text rendering method. TextCrafter employs a progressive strategy to decompose complex visual text into distinct components while ensuring robust alignment between textual content and its visual carrier. Additionally, it incorporates a token focus enhancement mechanism to amplify the prominence of visual text during the generation process. TextCrafter effectively addresses key challenges in CVTG tasks, such as text confusion, omissions, and blurriness. Moreover, we present a new benchmark dataset, CVTG-2K, tailored to rigorously evaluate the performance of generative models on CVTG tasks. Extensive experiments demonstrate that our method surpasses state-of-the-art approaches.
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Mar 09, 2025Recent advances in diffusion-based text-to-image generation have demonstrated promising results through visual condition control. However, existing ControlNet-like methods struggle with compositional visual conditioning - simultaneously preserving semantic fidelity across multiple heterogeneous control signals while maintaining high visual quality, where they employ separate control branches that often introduce conflicting guidance during the denoising process, leading to structural distortions and artifacts in generated images. To address this issue, we present PixelPonder, a novel unified control framework, which allows for effective control of multiple visual conditions under a single control structure. Specifically, we design a patch-level adaptive condition selection mechanism that dynamically prioritizes spatially relevant control signals at the sub-region level, enabling precise local guidance without global interference. Additionally, a time-aware control injection scheme is deployed to modulate condition influence according to denoising timesteps, progressively transitioning from structural preservation to texture refinement and fully utilizing the control information from different categories to promote more harmonious image generation. Extensive experiments demonstrate that PixelPonder surpasses previous methods across different benchmark datasets, showing superior improvement in spatial alignment accuracy while maintaining high textual semantic consistency.
RealVVT: Towards Photorealistic Video Virtual Try-on via Spatio-Temporal Consistency
Jan 15, 2025Virtual try-on has emerged as a pivotal task at the intersection of computer vision and fashion, aimed at digitally simulating how clothing items fit on the human body. Despite notable progress in single-image virtual try-on (VTO), current methodologies often struggle to preserve a consistent and authentic appearance of clothing across extended video sequences. This challenge arises from the complexities of capturing dynamic human pose and maintaining target clothing characteristics. We leverage pre-existing video foundation models to introduce RealVVT, a photoRealistic Video Virtual Try-on framework tailored to bolster stability and realism within dynamic video contexts. Our methodology encompasses a Clothing & Temporal Consistency strategy, an Agnostic-guided Attention Focus Loss mechanism to ensure spatial consistency, and a Pose-guided Long Video VTO technique adept at handling extended video sequences.Extensive experiments across various datasets confirms that our approach outperforms existing state-of-the-art models in both single-image and video VTO tasks, offering a viable solution for practical applications within the realms of fashion e-commerce and virtual fitting environments.
EnerVerse: Envisioning Embodied Future Space for Robotics Manipulation
Jan 03, 2025



We introduce EnerVerse, a comprehensive framework for embodied future space generation specifically designed for robotic manipulation tasks. EnerVerse seamlessly integrates convolutional and bidirectional attention mechanisms for inner-chunk space modeling, ensuring low-level consistency and continuity. Recognizing the inherent redundancy in video data, we propose a sparse memory context combined with a chunkwise unidirectional generative paradigm to enable the generation of infinitely long sequences. To further augment robotic capabilities, we introduce the Free Anchor View (FAV) space, which provides flexible perspectives to enhance observation and analysis. The FAV space mitigates motion modeling ambiguity, removes physical constraints in confined environments, and significantly improves the robot's generalization and adaptability across various tasks and settings. To address the prohibitive costs and labor intensity of acquiring multi-camera observations, we present a data engine pipeline that integrates a generative model with 4D Gaussian Splatting (4DGS). This pipeline leverages the generative model's robust generalization capabilities and the spatial constraints provided by 4DGS, enabling an iterative enhancement of data quality and diversity, thus creating a data flywheel effect that effectively narrows the sim-to-real gap. Finally, our experiments demonstrate that the embodied future space generation prior substantially enhances policy predictive capabilities, resulting in improved overall performance, particularly in long-range robotic manipulation tasks.
Foundation Cures Personalization: Recovering Facial Personalized Models' Prompt Consistency
Nov 22, 2024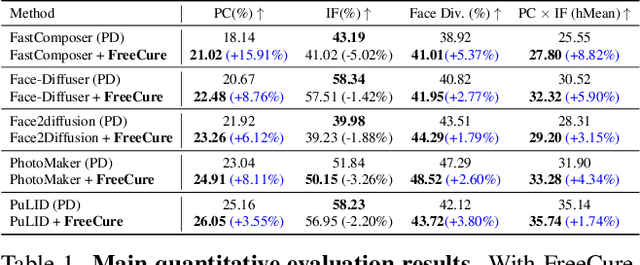

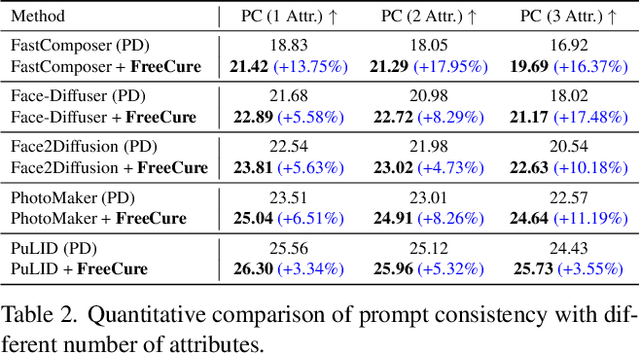

Facial personalization represents a crucial downstream task in the domain of text-to-image generation. To preserve identity fidelity while ensuring alignment with user-defined prompts, current mainstream frameworks for facial personalization predominantly employ identity embedding mechanisms to associate identity information with textual embeddings. However, our experiments show that identity embeddings compromise the effectiveness of other tokens within the prompt, thereby hindering high prompt consistency, particularly when prompts involve multiple facial attributes. Moreover, previous works overlook the fact that their corresponding foundation models hold great potential to generate faces aligning to prompts well and can be easily leveraged to cure these ill-aligned attributes in personalized models. Building upon these insights, we propose FreeCure, a training-free framework that harnesses the intrinsic knowledge from the foundation models themselves to improve the prompt consistency of personalization models. First, by extracting cross-attention and semantic maps from the denoising process of foundation models, we identify easily localized attributes (e.g., hair, accessories, etc). Second, we enhance multiple attributes in the outputs of personalization models through a novel noise-blending strategy coupled with an inversion-based process. Our approach offers several advantages: it eliminates the need for training; it effectively facilitates the enhancement for a wide array of facial attributes in a non-intrusive manner; and it can be seamlessly integrated into existing popular personalization models. FreeCure has demonstrated significant improvements in prompt consistency across a diverse set of state-of-the-art facial personalization models while maintaining the integrity of original identity fidelity.
Region-Aware Text-to-Image Generation via Hard Binding and Soft Refinement
Nov 15, 2024



Regional prompting, or compositional generation, which enables fine-grained spatial control, has gained increasing attention for its practicality in real-world applications. However, previous methods either introduce additional trainable modules, thus only applicable to specific models, or manipulate on score maps within cross-attention layers using attention masks, resulting in limited control strength when the number of regions increases. To handle these limitations, we present RAG, a Regional-Aware text-to-image Generation method conditioned on regional descriptions for precise layout composition. RAG decouple the multi-region generation into two sub-tasks, the construction of individual region (Regional Hard Binding) that ensures the regional prompt is properly executed, and the overall detail refinement (Regional Soft Refinement) over regions that dismiss the visual boundaries and enhance adjacent interactions. Furthermore, RAG novelly makes repainting feasible, where users can modify specific unsatisfied regions in the last generation while keeping all other regions unchanged, without relying on additional inpainting models. Our approach is tuning-free and applicable to other frameworks as an enhancement to the prompt following property. Quantitative and qualitative experiments demonstrate that RAG achieves superior performance over attribute binding and object relationship than previous tuning-free methods.
UniAff: A Unified Representation of Affordances for Tool Usage and Articulation with Vision-Language Models
Sep 30, 2024



Previous studies on robotic manipulation are based on a limited understanding of the underlying 3D motion constraints and affordances. To address these challenges, we propose a comprehensive paradigm, termed UniAff, that integrates 3D object-centric manipulation and task understanding in a unified formulation. Specifically, we constructed a dataset labeled with manipulation-related key attributes, comprising 900 articulated objects from 19 categories and 600 tools from 12 categories. Furthermore, we leverage MLLMs to infer object-centric representations for manipulation tasks, including affordance recognition and reasoning about 3D motion constraints. Comprehensive experiments in both simulation and real-world settings indicate that UniAff significantly improves the generalization of robotic manipulation for tools and articulated objects. We hope that UniAff will serve as a general baseline for unified robotic manipulation tasks in the future. Images, videos, dataset, and code are published on the project website at:https://sites.google.com/view/uni-aff/home
SKT: Integrating State-Aware Keypoint Trajectories with Vision-Language Models for Robotic Garment Manipulation
Sep 26, 2024



Automating garment manipulation poses a significant challenge for assistive robotics due to the diverse and deformable nature of garments. Traditional approaches typically require separate models for each garment type, which limits scalability and adaptability. In contrast, this paper presents a unified approach using vision-language models (VLMs) to improve keypoint prediction across various garment categories. By interpreting both visual and semantic information, our model enables robots to manage different garment states with a single model. We created a large-scale synthetic dataset using advanced simulation techniques, allowing scalable training without extensive real-world data. Experimental results indicate that the VLM-based method significantly enhances keypoint detection accuracy and task success rates, providing a more flexible and general solution for robotic garment manipulation. In addition, this research also underscores the potential of VLMs to unify various garment manipulation tasks within a single framework, paving the way for broader applications in home automation and assistive robotics for future.
OSV: One Step is Enough for High-Quality Image to Video Generation
Sep 17, 2024



Video diffusion models have shown great potential in generating high-quality videos, making them an increasingly popular focus. However, their inherent iterative nature leads to substantial computational and time costs. While efforts have been made to accelerate video diffusion by reducing inference steps (through techniques like consistency distillation) and GAN training (these approaches often fall short in either performance or training stability). In this work, we introduce a two-stage training framework that effectively combines consistency distillation with GAN training to address these challenges. Additionally, we propose a novel video discriminator design, which eliminates the need for decoding the video latents and improves the final performance. Our model is capable of producing high-quality videos in merely one-step, with the flexibility to perform multi-step refinement for further performance enhancement. Our quantitative evaluation on the OpenWebVid-1M benchmark shows that our model significantly outperforms existing methods. Notably, our 1-step performance(FVD 171.15) exceeds the 8-step performance of the consistency distillation based method, AnimateLCM (FVD 184.79), and approaches the 25-step performance of advanced Stable Video Diffusion (FVD 156.94).
Adapted-MoE: Mixture of Experts with Test-Time Adaption for Anomaly Detection
Sep 09, 2024



Most unsupervised anomaly detection methods based on representations of normal samples to distinguish anomalies have recently made remarkable progress. However, existing methods only learn a single decision boundary for distinguishing the samples within the training dataset, neglecting the variation in feature distribution for normal samples even in the same category in the real world. Furthermore, it was not considered that a distribution bias still exists between the test set and the train set. Therefore, we propose an Adapted-MoE which contains a routing network and a series of expert models to handle multiple distributions of same-category samples by divide and conquer. Specifically, we propose a routing network based on representation learning to route same-category samples into the subclasses feature space. Then, a series of expert models are utilized to learn the representation of various normal samples and construct several independent decision boundaries. We propose the test-time adaption to eliminate the bias between the unseen test sample representation and the feature distribution learned by the expert model. Our experiments are conducted on a dataset that provides multiple subclasses from three categories, namely Texture AD benchmark. The Adapted-MoE significantly improves the performance of the baseline model, achieving 2.18%-7.20% and 1.57%-16.30% increase in I-AUROC and P-AUROC, which outperforms the current state-of-the-art methods. Our code is available at https://github.com/.