 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Stylistic Consistency Profiling: Robust Detection of LLM-Generated Textual Content for Multimedia Moderation
May 07, 2026The increasing prevalence of Large Language Models (LLMs) in content creation has made distinguishing human-written textual content from LLM-generated counterparts a critical task for multimedia moderation. Existing detectors often rely on statistical cues or model-specific heuristics, making them vulnerable to paraphrasing and adversarial manipulations, and consequently limiting their robustness and interpretability. In this work, we proposeLiSCP , a novel lightweight stylistic consistency profiling method for robust detection of LLM-generated textual content, focusing on feature stability under adversarial manipulation. Our approach constructs a consistency profile that combines discrete stylistic features with continuous semantic signals, leveraging stylistic stability across multimodal-guided paraphrased text variants. Experiments spanning real-world multimedia news and movie datasets and conventional text domains demonstrate that LiSCP achieves superior performance on in-domain detection and outperforms existing approaches by up to 11.79% in cross-domain settings. Additionally,it demonstrates notable robustness under adversarial scenarios, including adversarial attacks and hybrid human-AI settings.
ArtGS:3D Gaussian Splatting for Interactive Visual-Physical Modeling and Manipulation of Articulated Objects
Jul 03, 2025Articulated object manipulation remains a critical challenge in robotics due to the complex kinematic constraints and the limited physical reasoning of existing methods. In this work, we introduce ArtGS, a novel framework that extends 3D Gaussian Splatting (3DGS) by integrating visual-physical modeling for articulated object understanding and interaction. ArtGS begins with multi-view RGB-D reconstruction, followed by reasoning with a vision-language model (VLM) to extract semantic and structural information, particularly the articulated bones. Through dynamic, differentiable 3DGS-based rendering, ArtGS optimizes the parameters of the articulated bones, ensuring physically consistent motion constraints and enhancing the manipulation policy. By leveraging dynamic Gaussian splatting, cross-embodiment adaptability, and closed-loop optimization, ArtGS establishes a new framework for efficient, scalable, and generalizable articulated object modeling and manipulation. Experiments conducted in both simulation and real-world environments demonstrate that ArtGS significantly outperforms previous methods in joint estimation accuracy and manipulation success rates across a variety of articulated objects. Additional images and videos are available on the project website: https://sites.google.com/view/artgs/home
Generalizable Articulated Object Perception with Superpoints
Dec 21, 2024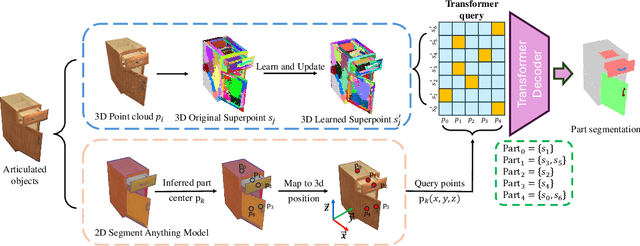



Manipulating articulated objects with robotic arms is challenging due to the complex kinematic structure, which requires precise part segmentation for efficient manipulation. In this work, we introduce a novel superpoint-based perception method designed to improve part segmentation in 3D point clouds of articulated objects. We propose a learnable, part-aware superpoint generation technique that efficiently groups points based on their geometric and semantic similarities, resulting in clearer part boundaries. Furthermore, by leveraging the segmentation capabilities of the 2D foundation model SAM, we identify the centers of pixel regions and select corresponding superpoints as candidate query points. Integrating a query-based transformer decoder further enhances our method's ability to achieve precise part segmentation. Experimental results on the GAPartNet dataset show that our method outperforms existing state-of-the-art approaches in cross-category part segmentation, achieving AP50 scores of 77.9% for seen categories (4.4% improvement) and $39.3\%$ for unseen categories (11.6% improvement), with superior results in 5 out of 9 part categories for seen objects and outperforming all previous methods across all part categories for unseen objects.
UniAff: A Unified Representation of Affordances for Tool Usage and Articulation with Vision-Language Models
Sep 30, 2024



Previous studies on robotic manipulation are based on a limited understanding of the underlying 3D motion constraints and affordances. To address these challenges, we propose a comprehensive paradigm, termed UniAff, that integrates 3D object-centric manipulation and task understanding in a unified formulation. Specifically, we constructed a dataset labeled with manipulation-related key attributes, comprising 900 articulated objects from 19 categories and 600 tools from 12 categories. Furthermore, we leverage MLLMs to infer object-centric representations for manipulation tasks, including affordance recognition and reasoning about 3D motion constraints. Comprehensive experiments in both simulation and real-world settings indicate that UniAff significantly improves the generalization of robotic manipulation for tools and articulated objects. We hope that UniAff will serve as a general baseline for unified robotic manipulation tasks in the future. Images, videos, dataset, and code are published on the project website at:https://sites.google.com/view/uni-aff/home