 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Latent Canvas: Eliciting and Benchmarking Symbolic Visual Expression in LLMs
Mar 15, 2026Current multimodal approaches predominantly treat visual generation as an external process, relying on pixel rendering or code execution, thereby overlooking the native visual representation capabilities latent within Large Language Models (LLMs). In this work, we unlock this potential through ASCII art, a compact, efficient, and text-native visual format. We introduce SVE-ASCII, a unified framework designed to elicit and benchmark Symbolic Visual Expression directly within the pure text space. To address the scarcity of systematic resources, we construct ASCIIArt-7K, a high-quality dataset synthesized via a novel "Seed-and-Evolve" pipeline that augments human-curated anchors through in-context stylistic editing. We further implement a unified instruction-tuning strategy that jointly optimizes for both Generation (Text-to-ASCII) and Understanding (ASCII-to-Text). Crucially, our experiments reveal a critical phenomenon regarding task duality: while it is established that perception aids generation, we provide compelling evidence that generative training significantly enhances visual comprehension. This confirms a mutually reinforcing cycle in symbolic visual processing, a relationship previously hypothesized but rarely empirically demonstrated in the visual domain. We release our dataset, the ASCIIArt-Bench benchmark, and the SVE-ASCII model, establishing a robust baseline for native text-based visual intelligence.
SIGMA: Selective-Interleaved Generation with Multi-Attribute Tokens
Feb 07, 2026Recent unified models such as Bagel demonstrate that paired image-edit data can effectively align multiple visual tasks within a single diffusion transformer. However, these models remain limited to single-condition inputs and lack the flexibility needed to synthesize results from multiple heterogeneous sources. We present SIGMA (Selective-Interleaved Generation with Multi-Attribute Tokens), a unified post-training framework that enables interleaved multi-condition generation within diffusion transformers. SIGMA introduces selective multi-attribute tokens, including style, content, subject, and identity tokens, which allow the model to interpret and compose multiple visual conditions in an interleaved text-image sequence. Through post-training on the Bagel unified backbone with 700K interleaved examples, SIGMA supports compositional editing, selective attribute transfer, and fine-grained multimodal alignment. Extensive experiments show that SIGMA improves controllability, cross-condition consistency, and visual quality across diverse editing and generation tasks, with substantial gains over Bagel on compositional tasks.
StableWorld: Towards Stable and Consistent Long Interactive Video Generation
Jan 21, 2026In this paper, we explore the overlooked challenge of stability and temporal consistency in interactive video generation, which synthesizes dynamic and controllable video worlds through interactive behaviors such as camera movements and text prompts. Despite remarkable progress in world modeling, current methods still suffer from severe instability and temporal degradation, often leading to spatial drift and scene collapse during long-horizon interactions. To better understand this issue, we initially investigate the underlying causes of instability and identify that the major source of error accumulation originates from the same scene, where generated frames gradually deviate from the initial clean state and propagate errors to subsequent frames. Building upon this observation, we propose a simple yet effective method, \textbf{StableWorld}, a Dynamic Frame Eviction Mechanism. By continuously filtering out degraded frames while retaining geometrically consistent ones, StableWorld effectively prevents cumulative drift at its source, leading to more stable and temporal consistency of interactive generation. Promising results on multiple interactive video models, \eg, Matrix-Game, Open-Oasis, and Hunyuan-GameCraft, demonstrate that StableWorld is model-agnostic and can be applied to different interactive video generation frameworks to substantially improve stability, temporal consistency, and generalization across diverse interactive scenarios.
OmniPSD: Layered PSD Generation with Diffusion Transformer
Dec 10, 2025Recent advances in diffusion models have greatly improved image generation and editing, yet generating or reconstructing layered PSD files with transparent alpha channels remains highly challenging. We propose OmniPSD, a unified diffusion framework built upon the Flux ecosystem that enables both text-to-PSD generation and image-to-PSD decomposition through in-context learning. For text-to-PSD generation, OmniPSD arranges multiple target layers spatially into a single canvas and learns their compositional relationships through spatial attention, producing semantically coherent and hierarchically structured layers. For image-to-PSD decomposition, it performs iterative in-context editing, progressively extracting and erasing textual and foreground components to reconstruct editable PSD layers from a single flattened image. An RGBA-VAE is employed as an auxiliary representation module to preserve transparency without affecting structure learning. Extensive experiments on our new RGBA-layered dataset demonstrate that OmniPSD achieves high-fidelity generation, structural consistency, and transparency awareness, offering a new paradigm for layered design generation and decomposition with diffusion transformers.
EasyText: Controllable Diffusion Transformer for Multilingual Text Rendering
May 30, 2025



Generating accurate multilingual text with diffusion models has long been desired but remains challenging. Recent methods have made progress in rendering text in a single language, but rendering arbitrary languages is still an unexplored area. This paper introduces EasyText, a text rendering framework based on DiT (Diffusion Transformer), which connects denoising latents with multilingual character tokens encoded as character tokens. We propose character positioning encoding and position encoding interpolation techniques to achieve controllable and precise text rendering. Additionally, we construct a large-scale synthetic text image dataset with 1 million multilingual image-text annotations as well as a high-quality dataset of 20K annotated images, which are used for pretraining and fine-tuning respectively. Extensive experiments and evaluations demonstrate the effectiveness and advancement of our approach in multilingual text rendering, visual quality, and layout-aware text integration.
GRE Suite: Geo-localization Inference via Fine-Tuned Vision-Language Models and Enhanced Reasoning Chains
May 24, 2025Recent advances in Visual Language Models (VLMs) have demonstrated exceptional performance in visual reasoning tasks. However, geo-localization presents unique challenges, requiring the extraction of multigranular visual cues from images and their integration with external world knowledge for systematic reasoning. Current approaches to geo-localization tasks often lack robust reasoning mechanisms and explainability, limiting their effectiveness. To address these limitations, we propose the Geo Reason Enhancement (GRE) Suite, a novel framework that augments VLMs with structured reasoning chains for accurate and interpretable location inference. The GRE Suite is systematically developed across three key dimensions: dataset, model, and benchmark. First, we introduce GRE30K, a high-quality geo-localization reasoning dataset designed to facilitate fine-grained visual and contextual analysis. Next, we present the GRE model, which employs a multi-stage reasoning strategy to progressively infer scene attributes, local details, and semantic features, thereby narrowing down potential geographic regions with enhanced precision. Finally, we construct the Geo Reason Evaluation Benchmark (GREval-Bench), a comprehensive evaluation framework that assesses VLMs across diverse urban, natural, and landmark scenes to measure both coarse-grained (e.g., country, continent) and fine-grained (e.g., city, street) localization performance. Experimental results demonstrate that GRE significantly outperforms existing methods across all granularities of geo-localization tasks, underscoring the efficacy of reasoning-augmented VLMs in complex geographic inference. Code and data will be released at https://github.com/Thorin215/GRE.
RepText: Rendering Visual Text via Replicating
Apr 28, 2025Although contemporary text-to-image generation models have achieved remarkable breakthroughs in producing visually appealing images, their capacity to generate precise and flexible typographic elements, especially non-Latin alphabets, remains constrained. To address these limitations, we start from an naive assumption that text understanding is only a sufficient condition for text rendering, but not a necessary condition. Based on this, we present RepText, which aims to empower pre-trained monolingual text-to-image generation models with the ability to accurately render, or more precisely, replicate, multilingual visual text in user-specified fonts, without the need to really understand them. Specifically, we adopt the setting from ControlNet and additionally integrate language agnostic glyph and position of rendered text to enable generating harmonized visual text, allowing users to customize text content, font and position on their needs. To improve accuracy, a text perceptual loss is employed along with the diffusion loss. Furthermore, to stabilize rendering process, at the inference phase, we directly initialize with noisy glyph latent instead of random initialization, and adopt region masks to restrict the feature injection to only the text region to avoid distortion of the background. We conducted extensive experiments to verify the effectiveness of our RepText relative to existing works, our approach outperforms existing open-source methods and achieves comparable results to native multi-language closed-source models. To be more fair, we also exhaustively discuss its limitations in the end.
InstantCharacter: Personalize Any Characters with a Scalable Diffusion Transformer Framework
Apr 16, 2025Current learning-based subject customization approaches, predominantly relying on U-Net architectures, suffer from limited generalization ability and compromised image quality. Meanwhile, optimization-based methods require subject-specific fine-tuning, which inevitably degrades textual controllability. To address these challenges, we propose InstantCharacter, a scalable framework for character customization built upon a foundation diffusion transformer. InstantCharacter demonstrates three fundamental advantages: first, it achieves open-domain personalization across diverse character appearances, poses, and styles while maintaining high-fidelity results. Second, the framework introduces a scalable adapter with stacked transformer encoders, which effectively processes open-domain character features and seamlessly interacts with the latent space of modern diffusion transformers. Third, to effectively train the framework, we construct a large-scale character dataset containing 10-million-level samples. The dataset is systematically organized into paired (multi-view character) and unpaired (text-image combinations) subsets. This dual-data structure enables simultaneous optimization of identity consistency and textual editability through distinct learning pathways. Qualitative experiments demonstrate the advanced capabilities of InstantCharacter in generating high-fidelity, text-controllable, and character-consistent images, setting a new benchmark for character-driven image generation. Our source code is available at https://github.com/Tencent/InstantCharacter.
EasyControl: Adding Efficient and Flexible Control for Diffusion Transformer
Mar 10, 2025

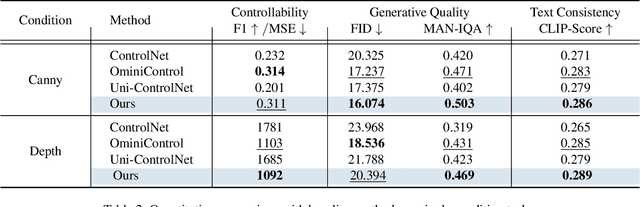

Recent advancements in Unet-based diffusion models, such as ControlNet and IP-Adapter, have introduced effective spatial and subject control mechanisms. However, the DiT (Diffusion Transformer) architecture still struggles with efficient and flexible control. To tackle this issue, we propose EasyControl, a novel framework designed to unify condition-guided diffusion transformers with high efficiency and flexibility. Our framework is built on three key innovations. First, we introduce a lightweight Condition Injection LoRA Module. This module processes conditional signals in isolation, acting as a plug-and-play solution. It avoids modifying the base model weights, ensuring compatibility with customized models and enabling the flexible injection of diverse conditions. Notably, this module also supports harmonious and robust zero-shot multi-condition generalization, even when trained only on single-condition data. Second, we propose a Position-Aware Training Paradigm. This approach standardizes input conditions to fixed resolutions, allowing the generation of images with arbitrary aspect ratios and flexible resolutions. At the same time, it optimizes computational efficiency, making the framework more practical for real-world applications. Third, we develop a Causal Attention Mechanism combined with the KV Cache technique, adapted for conditional generation tasks. This innovation significantly reduces the latency of image synthesis, improving the overall efficiency of the framework. Through extensive experiments, we demonstrate that EasyControl achieves exceptional performance across various application scenarios. These innovations collectively make our framework highly efficient, flexible, and suitable for a wide range of tasks.
Region-Aware Text-to-Image Generation via Hard Binding and Soft Refinement
Nov 15, 2024



Regional prompting, or compositional generation, which enables fine-grained spatial control, has gained increasing attention for its practicality in real-world applications. However, previous methods either introduce additional trainable modules, thus only applicable to specific models, or manipulate on score maps within cross-attention layers using attention masks, resulting in limited control strength when the number of regions increases. To handle these limitations, we present RAG, a Regional-Aware text-to-image Generation method conditioned on regional descriptions for precise layout composition. RAG decouple the multi-region generation into two sub-tasks, the construction of individual region (Regional Hard Binding) that ensures the regional prompt is properly executed, and the overall detail refinement (Regional Soft Refinement) over regions that dismiss the visual boundaries and enhance adjacent interactions. Furthermore, RAG novelly makes repainting feasible, where users can modify specific unsatisfied regions in the last generation while keeping all other regions unchanged, without relying on additional inpainting models. Our approach is tuning-free and applicable to other frameworks as an enhancement to the prompt following property. Quantitative and qualitative experiments demonstrate that RAG achieves superior performance over attribute binding and object relationship than previous tuning-free methods.