 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Simulation Runs but Solves the Wrong Physics: PDE-Grounded Intent Verification for LLM-Generated Multiphysics Simulation Code
May 10, 2026Execution-based evaluation of LLM-generated code implicitly treats successful execution as a proxy for correctness. In scientific simulation, this proxy is insufficient: a generated input file can run, mesh, and converge while encoding governing equations that differ from the user's intent. We call this mismatch between intended physics and generated code the comprehension-generation gap. We instantiate this in MOOSE, where Kernel and BC objects map compositionally to weak-form residual terms, enabling deterministic reconstruction of the encoded PDE and comparison against an intended contract. We formalize this comparison as the Intent Fidelity Score (IFS), a structural metric covering governing terms, BCs, ICs, coefficients, and time scheme. Building on IFS, we develop a PDE-grounded refinement loop that uses deterministic violation reports to correct generated code iteratively. We evaluate on MooseBench, a 220-case multiphysics benchmark with PDE-level ground truth released with this work. On this benchmark, our method consistently improves mean IFS over direct generation, with gains concentrated on hard cases. On the subset where direct generation falls below IFS 0.7, refinement adds +0.22 to +0.41 absolute IFS. In the deployment audit, execution-only repair improves execution success while leaving 39-40% of all 220 cases runnable but still solving the wrong physics across the three main deployment-audit models, exposing executability and intent fidelity as separable failure modes. Static proof-of-concept experiments on four PDE-oriented DSLs (UFL/FEniCS, FreeFEM, FiPy, and Devito) suggest that the reconstruction-and-comparison pattern extends beyond MOOSE. These findings reinforce that executable simulation code should be verified against the mathematical structure it is intended to encode, not accepted on execution alone.
UniCSG: Unified High-Fidelity Content-Constrained Style-Driven Generation via Staged Semantic and Frequency Disentanglement
Apr 20, 2026Style transfer must match a target style while preserving content semantics. DiT-based diffusion models often suffer from content-style entanglement, leading to reference-content leakage and unstable generation. We present UniCSG, a unified framework for content-constrained, style-driven generation in both text-guided and reference-guided settings. UniCSG employs staged training: (i) a latent-space semantic disentanglement stage that combines low-frequency preprocessing with conditioning corruption to encourage content-style separation, and (ii) a latent-space frequency-aware detail reconstruction stage that refines details via multi-scale frequency supervision. We further incorporate pixel-space reward learning to align latent objectives with perceptual quality after decoding. Experiments demonstrate improved content faithfulness, style alignment, and robustness in both settings.
Quantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025



Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
Follow-Your-Motion: Video Motion Transfer via Efficient Spatial-Temporal Decoupled Finetuning
Jun 05, 2025Recently, breakthroughs in the video diffusion transformer have shown remarkable capabilities in diverse motion generations. As for the motion-transfer task, current methods mainly use two-stage Low-Rank Adaptations (LoRAs) finetuning to obtain better performance. However, existing adaptation-based motion transfer still suffers from motion inconsistency and tuning inefficiency when applied to large video diffusion transformers. Naive two-stage LoRA tuning struggles to maintain motion consistency between generated and input videos due to the inherent spatial-temporal coupling in the 3D attention operator. Additionally, they require time-consuming fine-tuning processes in both stages. To tackle these issues, we propose Follow-Your-Motion, an efficient two-stage video motion transfer framework that finetunes a powerful video diffusion transformer to synthesize complex motion.Specifically, we propose a spatial-temporal decoupled LoRA to decouple the attention architecture for spatial appearance and temporal motion processing. During the second training stage, we design the sparse motion sampling and adaptive RoPE to accelerate the tuning speed. To address the lack of a benchmark for this field, we introduce MotionBench, a comprehensive benchmark comprising diverse motion, including creative camera motion, single object motion, multiple object motion, and complex human motion. We show extensive evaluations on MotionBench to verify the superiority of Follow-Your-Motion.
Graceful Forgetting in Generative Language Models
May 26, 2025Recently, the pretrain-finetune paradigm has become a cornerstone in various deep learning areas. While in general the pre-trained model would promote both effectiveness and efficiency of downstream tasks fine-tuning, studies have shown that not all knowledge acquired during pre-training is beneficial. Some of the knowledge may actually bring detrimental effects to the fine-tuning tasks, which is also known as negative transfer. To address this problem, graceful forgetting has emerged as a promising approach. The core principle of graceful forgetting is to enhance the learning plasticity of the target task by selectively discarding irrelevant knowledge. However, this approach remains underexplored in the context of generative language models, and it is often challenging to migrate existing forgetting algorithms to these models due to architecture incompatibility. To bridge this gap, in this paper we propose a novel framework, Learning With Forgetting (LWF), to achieve graceful forgetting in generative language models. With Fisher Information Matrix weighting the intended parameter updates, LWF computes forgetting confidence to evaluate self-generated knowledge regarding the forgetting task, and consequently, knowledge with high confidence is periodically unlearned during fine-tuning. Our experiments demonstrate that, although thoroughly uncovering the mechanisms of knowledge interaction remains challenging in pre-trained language models, applying graceful forgetting can contribute to enhanced fine-tuning performance.
Foundation Cures Personalization: Recovering Facial Personalized Models' Prompt Consistency
Nov 22, 2024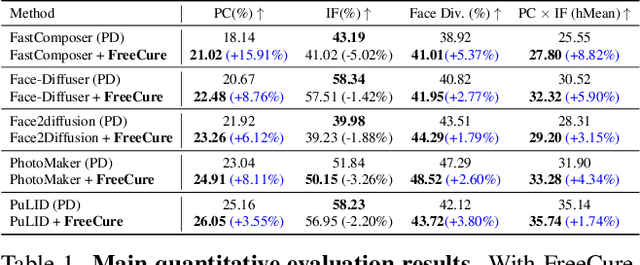

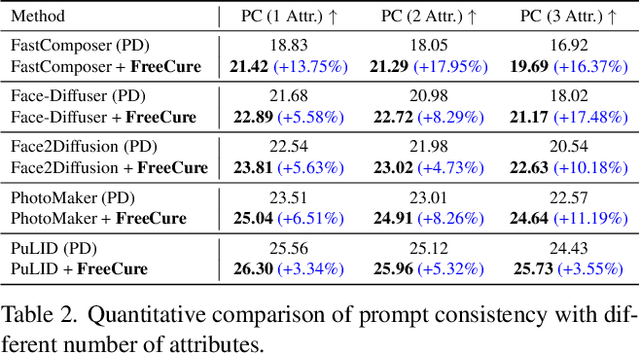

Facial personalization represents a crucial downstream task in the domain of text-to-image generation. To preserve identity fidelity while ensuring alignment with user-defined prompts, current mainstream frameworks for facial personalization predominantly employ identity embedding mechanisms to associate identity information with textual embeddings. However, our experiments show that identity embeddings compromise the effectiveness of other tokens within the prompt, thereby hindering high prompt consistency, particularly when prompts involve multiple facial attributes. Moreover, previous works overlook the fact that their corresponding foundation models hold great potential to generate faces aligning to prompts well and can be easily leveraged to cure these ill-aligned attributes in personalized models. Building upon these insights, we propose FreeCure, a training-free framework that harnesses the intrinsic knowledge from the foundation models themselves to improve the prompt consistency of personalization models. First, by extracting cross-attention and semantic maps from the denoising process of foundation models, we identify easily localized attributes (e.g., hair, accessories, etc). Second, we enhance multiple attributes in the outputs of personalization models through a novel noise-blending strategy coupled with an inversion-based process. Our approach offers several advantages: it eliminates the need for training; it effectively facilitates the enhancement for a wide array of facial attributes in a non-intrusive manner; and it can be seamlessly integrated into existing popular personalization models. FreeCure has demonstrated significant improvements in prompt consistency across a diverse set of state-of-the-art facial personalization models while maintaining the integrity of original identity fidelity.
HiRes-LLaVA: Restoring Fragmentation Input in High-Resolution Large Vision-Language Models
Jul 11, 2024



High-resolution inputs enable Large Vision-Language Models (LVLMs) to discern finer visual details, enhancing their comprehension capabilities. To reduce the training and computation costs caused by high-resolution input, one promising direction is to use sliding windows to slice the input into uniform patches, each matching the input size of the well-trained vision encoder. Although efficient, this slicing strategy leads to the fragmentation of original input, i.e., the continuity of contextual information and spatial geometry is lost across patches, adversely affecting performance in cross-patch context perception and position-specific tasks. To overcome these shortcomings, we introduce HiRes-LLaVA, a novel framework designed to efficiently process any size of high-resolution input without altering the original contextual and geometric information. HiRes-LLaVA comprises two innovative components: (i) a SliceRestore adapter that reconstructs sliced patches into their original form, efficiently extracting both global and local features via down-up-sampling and convolution layers, and (ii) a Self-Mining Sampler to compresses the vision tokens based on themselves, preserving the original context and positional information while reducing training overhead. To assess the ability of handling context fragmentation, we construct a new benchmark, EntityGrid-QA, consisting of edge-related and position-related tasks. Our comprehensive experiments demonstrate the superiority of HiRes-LLaVA on both existing public benchmarks and on EntityGrid-QA, particularly on document-oriented tasks, establishing new standards for handling high-resolution inputs.
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Mar 11, 2024Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
From Summary to Action: Enhancing Large Language Models for Complex Tasks with Open World APIs
Feb 28, 2024The distinction between humans and animals lies in the unique ability of humans to use and create tools. Tools empower humans to overcome physiological limitations, fostering the creation of magnificent civilizations. Similarly, enabling foundational models like Large Language Models (LLMs) with the capacity to learn external tool usage may serve as a pivotal step toward realizing artificial general intelligence. Previous studies in this field have predominantly pursued two distinct approaches to augment the tool invocation capabilities of LLMs. The first approach emphasizes the construction of relevant datasets for model fine-tuning. The second approach, in contrast, aims to fully exploit the inherent reasoning abilities of LLMs through in-context learning strategies. In this work, we introduce a novel tool invocation pipeline designed to control massive real-world APIs. This pipeline mirrors the human task-solving process, addressing complicated real-life user queries. At each step, we guide LLMs to summarize the achieved results and determine the next course of action. We term this pipeline `from Summary to action', Sum2Act for short. Empirical evaluations of our Sum2Act pipeline on the ToolBench benchmark show significant performance improvements, outperforming established methods like ReAct and DFSDT. This highlights Sum2Act's effectiveness in enhancing LLMs for complex real-world tasks.
BrainCLIP: Bridging Brain and Visual-Linguistic Representation via CLIP for Generic Natural Visual Stimulus Decoding from fMRI
Feb 25, 2023Reconstructing perceived natural images or decoding their categories from fMRI signals are challenging tasks with great scientific significance. Due to the lack of paired samples, most existing methods fail to generate semantically recognizable reconstruction and are difficult to generalize to novel classes. In this work, we propose, for the first time, a task-agnostic brain decoding model by unifying the visual stimulus classification and reconstruction tasks in a semantic space. We denote it as BrainCLIP, which leverages CLIP's cross-modal generalization ability to bridge the modality gap between brain activities, images, and texts. Specifically, BrainCLIP is a VAE-based architecture that transforms fMRI patterns into the CLIP embedding space by combining visual and textual supervision. Note that previous works rarely use multi-modal supervision for visual stimulus decoding. Our experiments demonstrate that textual supervision can significantly boost the performance of decoding models compared to the condition where only image supervision exists. BrainCLIP can be applied to multiple scenarios like fMRI-to-image generation, fMRI-image-matching, and fMRI-text-matching. Compared with BraVL, a recently proposed multi-modal method for fMRI-based brain decoding, BrainCLIP achieves significantly better performance on the novel class classification task. BrainCLIP also establishes a new state-of-the-art for fMRI-based natural image reconstruction in terms of high-level image features.