 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFused Gromov-Wasserstein Contrastive Learning for Effective Enzyme-Reaction Screening
Dec 09, 2025Enzymes are crucial catalysts that enable a wide range of biochemical reactions. Efficiently identifying specific enzymes from vast protein libraries is essential for advancing biocatalysis. Traditional computational methods for enzyme screening and retrieval are time-consuming and resource-intensive. Recently, deep learning approaches have shown promise. However, these methods focus solely on the interaction between enzymes and reactions, overlooking the inherent hierarchical relationships within each domain. To address these limitations, we introduce FGW-CLIP, a novel contrastive learning framework based on optimizing the fused Gromov-Wasserstein distance. FGW-CLIP incorporates multiple alignments, including inter-domain alignment between reactions and enzymes and intra-domain alignment within enzymes and reactions. By introducing a tailored regularization term, our method minimizes the Gromov-Wasserstein distance between enzyme and reaction spaces, which enhances information integration across these domains. Extensive evaluations demonstrate the superiority of FGW-CLIP in challenging enzyme-reaction tasks. On the widely-used EnzymeMap benchmark, FGW-CLIP achieves state-of-the-art performance in enzyme virtual screening, as measured by BEDROC and EF metrics. Moreover, FGW-CLIP consistently outperforms across all three splits of ReactZyme, the largest enzyme-reaction benchmark, demonstrating robust generalization to novel enzymes and reactions. These results position FGW-CLIP as a promising framework for enzyme discovery in complex biochemical settings, with strong adaptability across diverse screening scenarios.
SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
Nov 18, 2025Serving deep learning based recommendation models (DLRM) at scale is challenging. Existing systems rely on CPU-based ANN indexing and filtering services, suffering from non-negligible costs and forgoing joint optimization opportunities. Such inefficiency makes them difficult to support more complex model architectures, such as learned similarities and multi-task retrieval. In this paper, we propose SilverTorch, a model-based system for serving recommendation models on GPUs. SilverTorch unifies model serving by replacing standalone indexing and filtering services with layers of served models. We propose a Bloom index algorithm on GPUs for feature filtering and a tensor-native fused Int8 ANN kernel on GPUs for nearest neighbor search. We further co-design the ANN search index and filtering index to reduce GPU memory utilization and eliminate unnecessary computation. Benefit from SilverTorch's serving paradigm, we introduce a OverArch scoring layer and a Value Model to aggregate results across multi-tasks. These advancements improve the accuracy for retrieval and enable future studies for serving more complex models. For ranking, SilverTorch's design accelerates item embedding calculation by caching the pre-calculated embeddings inside the serving model. Our evaluation on the industry-scale datasets show that SilverTorch achieves up to 5.6x lower latency and 23.7x higher throughput compared to the state-of-the-art approaches. We also demonstrate that SilverTorch's solution is 13.35x more cost-efficient than CPU-based solution while improving accuracy via serving more complex models. SilverTorch serves over hundreds of models online across major products and recommends contents for billions of daily active users.
LMM-IR: Large-Scale Netlist-Aware Multimodal Framework for Static IR-Drop Prediction
Nov 16, 2025Static IR drop analysis is a fundamental and critical task in the field of chip design. Nevertheless, this process can be quite time-consuming, potentially requiring several hours. Moreover, addressing IR drop violations frequently demands iterative analysis, thereby causing the computational burden. Therefore, fast and accurate IR drop prediction is vital for reducing the overall time invested in chip design. In this paper, we firstly propose a novel multimodal approach that efficiently processes SPICE files through large-scale netlist transformer (LNT). Our key innovation is representing and processing netlist topology as 3D point cloud representations, enabling efficient handling of netlist with up to hundreds of thousands to millions nodes. All types of data, including netlist files and image data, are encoded into latent space as features and fed into the model for static voltage drop prediction. This enables the integration of data from multiple modalities for complementary predictions. Experimental results demonstrate that our proposed algorithm can achieve the best F1 score and the lowest MAE among the winning teams of the ICCAD 2023 contest and the state-of-the-art algorithms.
DeepPersona: A Generative Engine for Scaling Deep Synthetic Personas
Nov 11, 2025Simulating human profiles by instilling personas into large language models (LLMs) is rapidly transforming research in agentic behavioral simulation, LLM personalization, and human-AI alignment. However, most existing synthetic personas remain shallow and simplistic, capturing minimal attributes and failing to reflect the rich complexity and diversity of real human identities. We introduce DEEPPERSONA, a scalable generative engine for synthesizing narrative-complete synthetic personas through a two-stage, taxonomy-guided method. First, we algorithmically construct the largest-ever human-attribute taxonomy, comprising over hundreds of hierarchically organized attributes, by mining thousands of real user-ChatGPT conversations. Second, we progressively sample attributes from this taxonomy, conditionally generating coherent and realistic personas that average hundreds of structured attributes and roughly 1 MB of narrative text, two orders of magnitude deeper than prior works. Intrinsic evaluations confirm significant improvements in attribute diversity (32 percent higher coverage) and profile uniqueness (44 percent greater) compared to state-of-the-art baselines. Extrinsically, our personas enhance GPT-4.1-mini's personalized question answering accuracy by 11.6 percent on average across ten metrics and substantially narrow (by 31.7 percent) the gap between simulated LLM citizens and authentic human responses in social surveys. Our generated national citizens reduced the performance gap on the Big Five personality test by 17 percent relative to LLM-simulated citizens. DEEPPERSONA thus provides a rigorous, scalable, and privacy-free platform for high-fidelity human simulation and personalized AI research.
* 12 pages, 5 figures, accepted at LAW 2025 Workshop (NeurIPS 2025) Project page: https://deeppersona-ai.github.io/
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025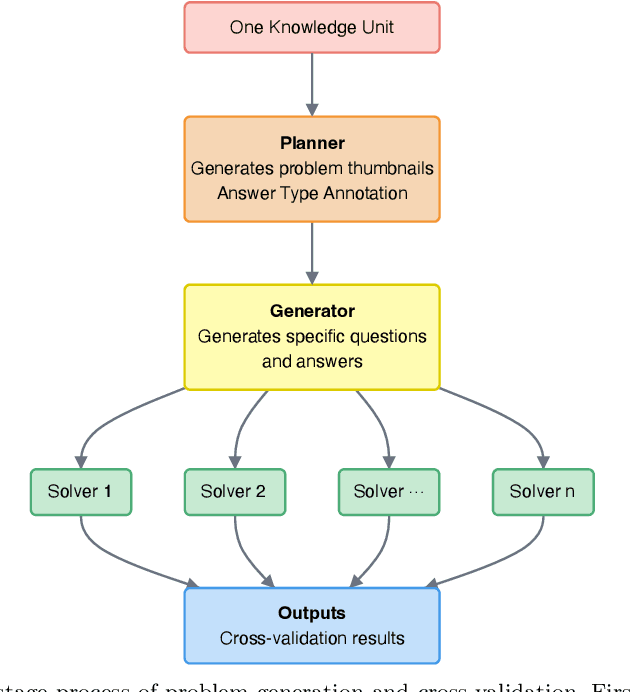
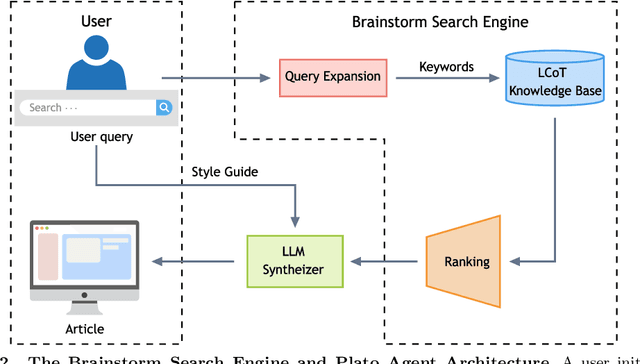
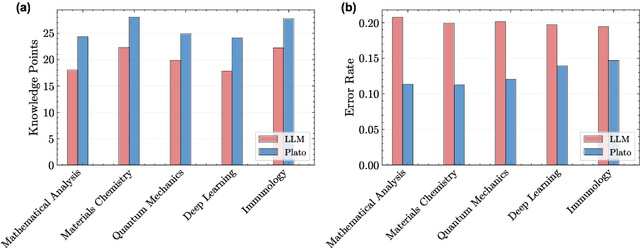
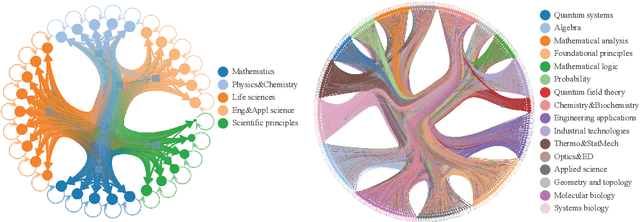
Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.
CoMo: Compositional Motion Customization for Text-to-Video Generation
Oct 27, 2025While recent text-to-video models excel at generating diverse scenes, they struggle with precise motion control, particularly for complex, multi-subject motions. Although methods for single-motion customization have been developed to address this gap, they fail in compositional scenarios due to two primary challenges: motion-appearance entanglement and ineffective multi-motion blending. This paper introduces CoMo, a novel framework for $\textbf{compositional motion customization}$ in text-to-video generation, enabling the synthesis of multiple, distinct motions within a single video. CoMo addresses these issues through a two-phase approach. First, in the single-motion learning phase, a static-dynamic decoupled tuning paradigm disentangles motion from appearance to learn a motion-specific module. Second, in the multi-motion composition phase, a plug-and-play divide-and-merge strategy composes these learned motions without additional training by spatially isolating their influence during the denoising process. To facilitate research in this new domain, we also introduce a new benchmark and a novel evaluation metric designed to assess multi-motion fidelity and blending. Extensive experiments demonstrate that CoMo achieves state-of-the-art performance, significantly advancing the capabilities of controllable video generation. Our project page is at https://como6.github.io/.
Composable Score-based Graph Diffusion Model for Multi-Conditional Molecular Generation
Sep 11, 2025Controllable molecular graph generation is essential for material and drug discovery, where generated molecules must satisfy diverse property constraints. While recent advances in graph diffusion models have improved generation quality, their effectiveness in multi-conditional settings remains limited due to reliance on joint conditioning or continuous relaxations that compromise fidelity. To address these limitations, we propose Composable Score-based Graph Diffusion model (CSGD), the first model that extends score matching to discrete graphs via concrete scores, enabling flexible and principled manipulation of conditional guidance. Building on this foundation, we introduce two score-based techniques: Composable Guidance (CoG), which allows fine-grained control over arbitrary subsets of conditions during sampling, and Probability Calibration (PC), which adjusts estimated transition probabilities to mitigate train-test mismatches. Empirical results on four molecular datasets show that CSGD achieves state-of-the-art performance, with a 15.3% average improvement in controllability over prior methods, while maintaining high validity and distributional fidelity. Our findings highlight the practical advantages of score-based modeling for discrete graph generation and its capacity for flexible, multi-property molecular design.
PerPilot: Personalizing VLM-based Mobile Agents via Memory and Exploration
Aug 25, 2025



Vision language model (VLM)-based mobile agents show great potential for assisting users in performing instruction-driven tasks. However, these agents typically struggle with personalized instructions -- those containing ambiguous, user-specific context -- a challenge that has been largely overlooked in previous research. In this paper, we define personalized instructions and introduce PerInstruct, a novel human-annotated dataset covering diverse personalized instructions across various mobile scenarios. Furthermore, given the limited personalization capabilities of existing mobile agents, we propose PerPilot, a plug-and-play framework powered by large language models (LLMs) that enables mobile agents to autonomously perceive, understand, and execute personalized user instructions. PerPilot identifies personalized elements and autonomously completes instructions via two complementary approaches: memory-based retrieval and reasoning-based exploration. Experimental results demonstrate that PerPilot effectively handles personalized tasks with minimal user intervention and progressively improves its performance with continued use, underscoring the importance of personalization-aware reasoning for next-generation mobile agents. The dataset and code are available at: https://github.com/xinwang-nwpu/PerPilot
LLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
Regret Minimization in Population Network Games: Vanishing Heterogeneity and Convergence to Equilibria
Jul 23, 2025Understanding and predicting the behavior of large-scale multi-agents in games remains a fundamental challenge in multi-agent systems. This paper examines the role of heterogeneity in equilibrium formation by analyzing how smooth regret-matching drives a large number of heterogeneous agents with diverse initial policies toward unified behavior. By modeling the system state as a probability distribution of regrets and analyzing its evolution through the continuity equation, we uncover a key phenomenon in diverse multi-agent settings: the variance of the regret distribution diminishes over time, leading to the disappearance of heterogeneity and the emergence of consensus among agents. This universal result enables us to prove convergence to quantal response equilibria in both competitive and cooperative multi-agent settings. Our work advances the theoretical understanding of multi-agent learning and offers a novel perspective on equilibrium selection in diverse game-theoretic scenarios.