 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025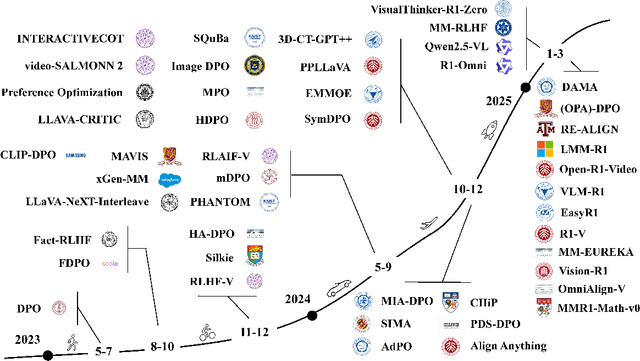
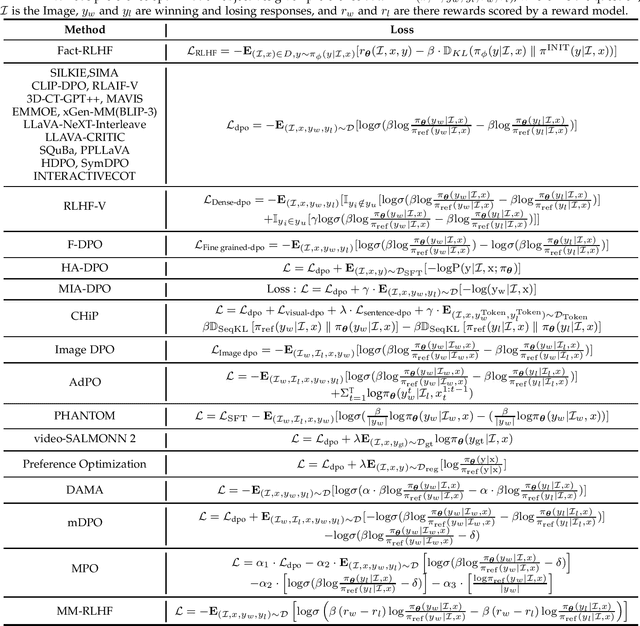
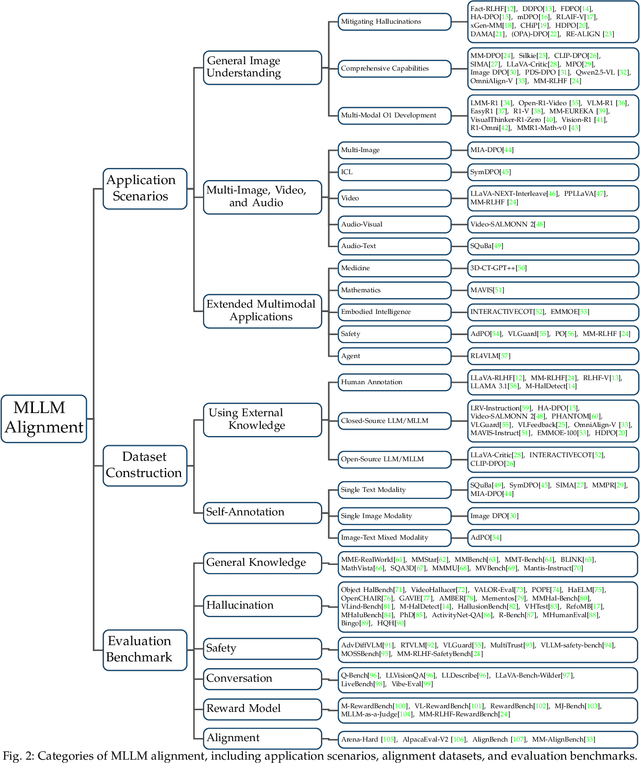

Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
LLaVA-RadZ: Can Multimodal Large Language Models Effectively Tackle Zero-shot Radiology Recognition?
Mar 10, 2025Recently, multimodal large models (MLLMs) have demonstrated exceptional capabilities in visual understanding and reasoning across various vision-language tasks. However, MLLMs usually perform poorly in zero-shot medical disease recognition, as they do not fully exploit the captured features and available medical knowledge. To address this challenge, we propose LLaVA-RadZ, a simple yet effective framework for zero-shot medical disease recognition. Specifically, we design an end-to-end training strategy, termed Decoding-Side Feature Alignment Training (DFAT) to take advantage of the characteristics of the MLLM decoder architecture and incorporate modality-specific tokens tailored for different modalities, which effectively utilizes image and text representations and facilitates robust cross-modal alignment. Additionally, we introduce a Domain Knowledge Anchoring Module (DKAM) to exploit the intrinsic medical knowledge of large models, which mitigates the category semantic gap in image-text alignment. DKAM improves category-level alignment, allowing for accurate disease recognition. Extensive experiments on multiple benchmarks demonstrate that our LLaVA-RadZ significantly outperforms traditional MLLMs in zero-shot disease recognition and exhibits the state-of-the-art performance compared to the well-established and highly-optimized CLIP-based approaches.
Training-free Anomaly Event Detection via LLM-guided Symbolic Pattern Discovery
Feb 09, 2025



Anomaly event detection plays a crucial role in various real-world applications. However, current approaches predominantly rely on supervised learning, which faces significant challenges: the requirement for extensive labeled training data and lack of interpretability in decision-making processes. To address these limitations, we present a training-free framework that integrates open-set object detection with symbolic regression, powered by Large Language Models (LLMs) for efficient symbolic pattern discovery. The LLMs guide the symbolic reasoning process, establishing logical relationships between detected entities. Through extensive experiments across multiple domains, our framework demonstrates several key advantages: (1) achieving superior detection accuracy through direct reasoning without any training process; (2) providing highly interpretable logical expressions that are readily comprehensible to humans; and (3) requiring minimal annotation effort - approximately 1% of the data needed by traditional training-based methods.To facilitate comprehensive evaluation and future research, we introduce two datasets: a large-scale private dataset containing over 110,000 annotated images covering various anomaly scenarios including construction site safety violations, illegal fishing activities, and industrial hazards, along with a public benchmark dataset of 5,000 samples with detailed anomaly event annotations. Code is available at here.
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuray
Feb 07, 2025Establishing the long-context capability of large vision-language models is crucial for video understanding, high-resolution image understanding, multi-modal agents and reasoning. We introduce Long-VITA, a simple yet effective large multi-modal model for long-context visual-language understanding tasks. It is adept at concurrently processing and analyzing modalities of image, video, and text over 4K frames or 1M tokens while delivering advanced performances on short-context multi-modal tasks. We propose an effective multi-modal training schema that starts with large language models and proceeds through vision-language alignment, general knowledge learning, and two sequential stages of long-sequence fine-tuning. We further implement context-parallelism distributed inference and logits-masked language modeling head to scale Long-VITA to infinitely long inputs of images and texts during model inference. Regarding training data, Long-VITA is built on a mix of $17$M samples from public datasets only and demonstrates the state-of-the-art performance on various multi-modal benchmarks, compared against recent cutting-edge models with internal data. Long-VITA is fully reproducible and supports both NPU and GPU platforms for training and testing. We hope Long-VITA can serve as a competitive baseline and offer valuable insights for the open-source community in advancing long-context multi-modal understanding.
LUCY: Linguistic Understanding and Control Yielding Early Stage of Her
Jan 27, 2025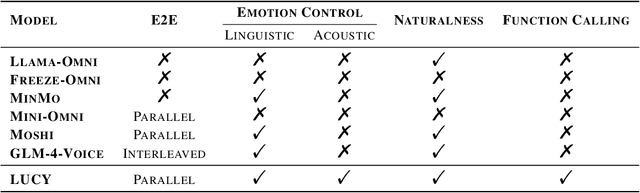
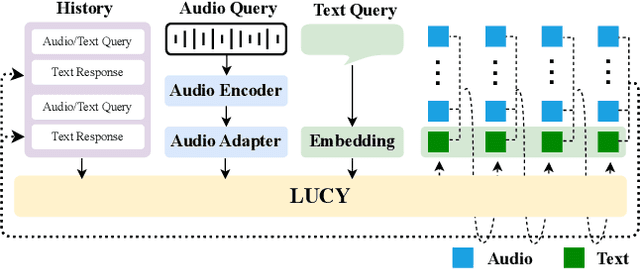
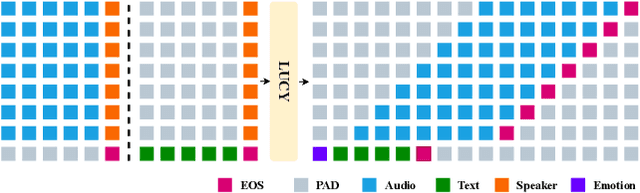
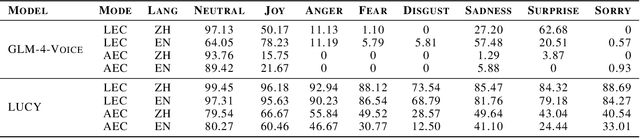
The film Her features Samantha, a sophisticated AI audio agent who is capable of understanding both linguistic and paralinguistic information in human speech and delivering real-time responses that are natural, informative and sensitive to emotional subtleties. Moving one step toward more sophisticated audio agent from recent advancement in end-to-end (E2E) speech systems, we propose LUCY, a E2E speech model that (1) senses and responds to user's emotion, (2) deliver responses in a succinct and natural style, and (3) use external tool to answer real-time inquiries. Experiment results show that LUCY is better at emotion control than peer models, generating emotional responses based on linguistic emotional instructions and responding to paralinguistic emotional cues. Lucy is also able to generate responses in a more natural style, as judged by external language models, without sacrificing much performance on general question answering. Finally, LUCY can leverage function calls to answer questions that are out of its knowledge scope.
Solving the Catastrophic Forgetting Problem in Generalized Category Discovery
Jan 09, 2025Generalized Category Discovery (GCD) aims to identify a mix of known and novel categories within unlabeled data sets, providing a more realistic setting for image recognition. Essentially, GCD needs to remember existing patterns thoroughly to recognize novel categories. Recent state-of-the-art method SimGCD transfers the knowledge from known-class data to the learning of novel classes through debiased learning. However, some patterns are catastrophically forgot during adaptation and thus lead to poor performance in novel categories classification. To address this issue, we propose a novel learning approach, LegoGCD, which is seamlessly integrated into previous methods to enhance the discrimination of novel classes while maintaining performance on previously encountered known classes. Specifically, we design two types of techniques termed as Local Entropy Regularization (LER) and Dual-views Kullback Leibler divergence constraint (DKL). The LER optimizes the distribution of potential known class samples in unlabeled data, thus ensuring the preservation of knowledge related to known categories while learning novel classes. Meanwhile, DKL introduces Kullback Leibler divergence to encourage the model to produce a similar prediction distribution of two view samples from the same image. In this way, it successfully avoids mismatched prediction and generates more reliable potential known class samples simultaneously. Extensive experiments validate that the proposed LegoGCD effectively addresses the known category forgetting issue across all datasets, eg, delivering a 7.74% and 2.51% accuracy boost on known and novel classes in CUB, respectively. Our code is available at: https://github.com/Cliffia123/LegoGCD.
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Jan 03, 2025



Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
Probability-density-aware Semi-supervised Learning
Dec 23, 2024Semi-supervised learning (SSL) assumes that neighbor points lie in the same category (neighbor assumption), and points in different clusters belong to various categories (cluster assumption). Existing methods usually rely on similarity measures to retrieve the similar neighbor points, ignoring cluster assumption, which may not utilize unlabeled information sufficiently and effectively. This paper first provides a systematical investigation into the significant role of probability density in SSL and lays a solid theoretical foundation for cluster assumption. To this end, we introduce a Probability-Density-Aware Measure (PM) to discern the similarity between neighbor points. To further improve Label Propagation, we also design a Probability-Density-Aware Measure Label Propagation (PMLP) algorithm to fully consider the cluster assumption in label propagation. Last but not least, we prove that traditional pseudo-labeling could be viewed as a particular case of PMLP, which provides a comprehensive theoretical understanding of PMLP's superior performance. Extensive experiments demonstrate that PMLP achieves outstanding performance compared with other recent methods.
Dynamic Contrastive Knowledge Distillation for Efficient Image Restoration
Dec 12, 2024



Knowledge distillation (KD) is a valuable yet challenging approach that enhances a compact student network by learning from a high-performance but cumbersome teacher model. However, previous KD methods for image restoration overlook the state of the student during the distillation, adopting a fixed solution space that limits the capability of KD. Additionally, relying solely on L1-type loss struggles to leverage the distribution information of images. In this work, we propose a novel dynamic contrastive knowledge distillation (DCKD) framework for image restoration. Specifically, we introduce dynamic contrastive regularization to perceive the student's learning state and dynamically adjust the distilled solution space using contrastive learning. Additionally, we also propose a distribution mapping module to extract and align the pixel-level category distribution of the teacher and student models. Note that the proposed DCKD is a structure-agnostic distillation framework, which can adapt to different backbones and can be combined with methods that optimize upper-bound constraints to further enhance model performance. Extensive experiments demonstrate that DCKD significantly outperforms the state-of-the-art KD methods across various image restoration tasks and backbones.
FlashSloth: Lightning Multimodal Large Language Models via Embedded Visual Compression
Dec 05, 2024



Despite a big leap forward in capability, multimodal large language models (MLLMs) tend to behave like a sloth in practical use, i.e., slow response and large latency. Recent efforts are devoted to building tiny MLLMs for better efficiency, but the plethora of visual tokens still used limit their actual speedup. In this paper, we propose a powerful and fast tiny MLLM called FlashSloth. Different from previous efforts, FlashSloth focuses on improving the descriptive power of visual tokens in the process of compressing their redundant semantics. In particular, FlashSloth introduces embedded visual compression designs to capture both visually salient and instruction-related image information, so as to achieving superior multimodal performance with fewer visual tokens. Extensive experiments are conducted to validate the proposed FlashSloth, and a bunch of tiny but strong MLLMs are also comprehensively compared, e.g., InternVL2, MiniCPM-V2 and Qwen2-VL. The experimental results show that compared with these advanced tiny MLLMs, our FlashSloth can greatly reduce the number of visual tokens, training memory and computation complexity while retaining high performance on various VL tasks.