 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoITG: Multimodal Video Understanding with Instructed Temporal Grounding
Jul 17, 2025Recent studies have revealed that selecting informative and relevant video frames can significantly improve the performance of Video Large Language Models (Video-LLMs). Current methods, such as reducing inter-frame redundancy, employing separate models for image-text relevance assessment, or utilizing temporal video grounding for event localization, substantially adopt unsupervised learning paradigms, whereas they struggle to address the complex scenarios in long video understanding. We propose Instructed Temporal Grounding for Videos (VideoITG), featuring customized frame sampling aligned with user instructions. The core of VideoITG is the VidThinker pipeline, an automated annotation framework that explicitly mimics the human annotation process. First, it generates detailed clip-level captions conditioned on the instruction; then, it retrieves relevant video segments through instruction-guided reasoning; finally, it performs fine-grained frame selection to pinpoint the most informative visual evidence. Leveraging VidThinker, we construct the VideoITG-40K dataset, containing 40K videos and 500K instructed temporal grounding annotations. We then design a plug-and-play VideoITG model, which takes advantage of visual language alignment and reasoning capabilities of Video-LLMs, for effective frame selection in a discriminative manner. Coupled with Video-LLMs, VideoITG achieves consistent performance improvements across multiple multimodal video understanding benchmarks, showing its superiority and great potentials for video understanding.
Chi-Square Wavelet Graph Neural Networks for Heterogeneous Graph Anomaly Detection
May 25, 2025



Graph Anomaly Detection (GAD) in heterogeneous networks presents unique challenges due to node and edge heterogeneity. Existing Graph Neural Network (GNN) methods primarily focus on homogeneous GAD and thus fail to address three key issues: (C1) Capturing abnormal signal and rich semantics across diverse meta-paths; (C2) Retaining high-frequency content in HIN dimension alignment; and (C3) Learning effectively from difficult anomaly samples with class imbalance. To overcome these, we propose ChiGAD, a spectral GNN framework based on a novel Chi-Square filter, inspired by the wavelet effectiveness in diverse domains. Specifically, ChiGAD consists of: (1) Multi-Graph Chi-Square Filter, which captures anomalous information via applying dedicated Chi-Square filters to each meta-path graph; (2) Interactive Meta-Graph Convolution, which aligns features while preserving high-frequency information and incorporates heterogeneous messages by a unified Chi-Square Filter; and (3) Contribution-Informed Cross-Entropy Loss, which prioritizes difficult anomalies to address class imbalance. Extensive experiments on public and industrial datasets show that ChiGAD outperforms state-of-the-art models on multiple metrics. Additionally, its homogeneous variant, ChiGNN, excels on seven GAD datasets, validating the effectiveness of Chi-Square filters. Our code is available at https://github.com/HsipingLi/ChiGAD.
Training-free Anomaly Event Detection via LLM-guided Symbolic Pattern Discovery
Feb 09, 2025



Anomaly event detection plays a crucial role in various real-world applications. However, current approaches predominantly rely on supervised learning, which faces significant challenges: the requirement for extensive labeled training data and lack of interpretability in decision-making processes. To address these limitations, we present a training-free framework that integrates open-set object detection with symbolic regression, powered by Large Language Models (LLMs) for efficient symbolic pattern discovery. The LLMs guide the symbolic reasoning process, establishing logical relationships between detected entities. Through extensive experiments across multiple domains, our framework demonstrates several key advantages: (1) achieving superior detection accuracy through direct reasoning without any training process; (2) providing highly interpretable logical expressions that are readily comprehensible to humans; and (3) requiring minimal annotation effort - approximately 1% of the data needed by traditional training-based methods.To facilitate comprehensive evaluation and future research, we introduce two datasets: a large-scale private dataset containing over 110,000 annotated images covering various anomaly scenarios including construction site safety violations, illegal fishing activities, and industrial hazards, along with a public benchmark dataset of 5,000 samples with detailed anomaly event annotations. Code is available at here.
Video-RAG: Visually-aligned Retrieval-Augmented Long Video Comprehension
Nov 20, 2024



Existing large video-language models (LVLMs) struggle to comprehend long videos correctly due to limited context. To address this problem, fine-tuning long-context LVLMs and employing GPT-based agents have emerged as promising solutions. However, fine-tuning LVLMs would require extensive high-quality data and substantial GPU resources, while GPT-based agents would rely on proprietary models (e.g., GPT-4o). In this paper, we propose Video Retrieval-Augmented Generation (Video-RAG), a training-free and cost-effective pipeline that employs visually-aligned auxiliary texts to help facilitate cross-modality alignment while providing additional information beyond the visual content. Specifically, we leverage open-source external tools to extract visually-aligned information from pure video data (e.g., audio, optical character, and object detection), and incorporate the extracted information into an existing LVLM as auxiliary texts, alongside video frames and queries, in a plug-and-play manner. Our Video-RAG offers several key advantages: (i) lightweight with low computing overhead due to single-turn retrieval; (ii) easy implementation and compatibility with any LVLM; and (iii) significant, consistent performance gains across long video understanding benchmarks, including Video-MME, MLVU, and LongVideoBench. Notably, our model demonstrates superior performance over proprietary models like Gemini-1.5-Pro and GPT-4o when utilized with a 72B model.
Generative Pretraining at Scale: Transformer-Based Encoding of Transactional Behavior for Fraud Detection
Dec 22, 2023In this work, we introduce an innovative autoregressive model leveraging Generative Pretrained Transformer (GPT) architectures, tailored for fraud detection in payment systems. Our approach innovatively confronts token explosion and reconstructs behavioral sequences, providing a nuanced understanding of transactional behavior through temporal and contextual analysis. Utilizing unsupervised pretraining, our model excels in feature representation without the need for labeled data. Additionally, we integrate a differential convolutional approach to enhance anomaly detection, bolstering the security and efficacy of one of the largest online payment merchants in China. The scalability and adaptability of our model promise broad applicability in various transactional contexts.
Realization Scheme for Visual Cryptography with Computer-generated Holograms
Dec 10, 2022

We propose to realize visual cryptography in an indirect way with the help of computer-generated hologram. At present, the recovery method of visual cryptography is mainly superimposed on transparent film or superimposed by computer equipment, which greatly limits the application range of visual cryptography. In this paper, the shares of the visual cryptography were encoded with computer-generated hologram, and the shares is reproduced by optical means, and then superimposed and decrypted. This method can expand the application range of visual cryptography and further increase the security of visual cryptography.
CROLoss: Towards a Customizable Loss for Retrieval Models in Recommender Systems
Aug 05, 2022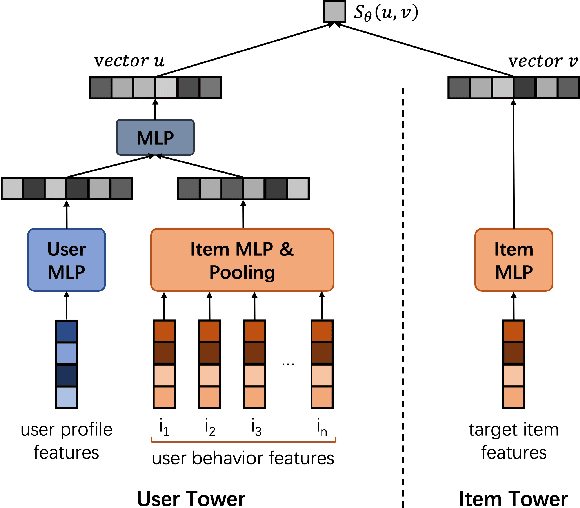
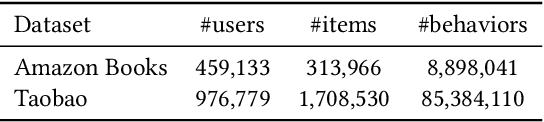
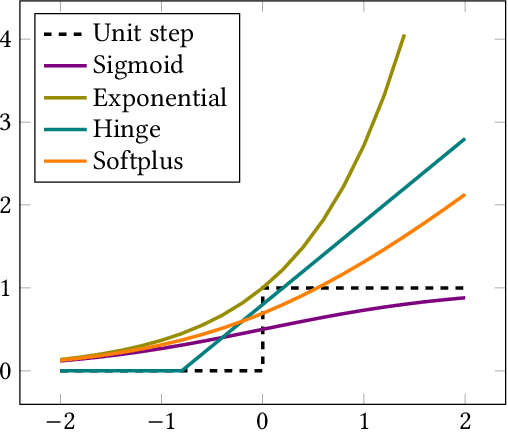
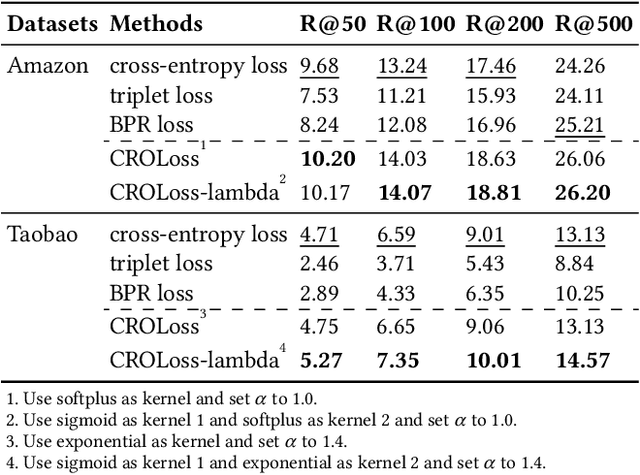
In large-scale recommender systems, retrieving top N relevant candidates accurately with resource constrain is crucial. To evaluate the performance of such retrieval models, Recall@N, the frequency of positive samples being retrieved in the top N ranking, is widely used. However, most of the conventional loss functions for retrieval models such as softmax cross-entropy and pairwise comparison methods do not directly optimize Recall@N. Moreover, those conventional loss functions cannot be customized for the specific retrieval size N required by each application and thus may lead to sub-optimal performance. In this paper, we proposed the Customizable Recall@N Optimization Loss (CROLoss), a loss function that can directly optimize the Recall@N metrics and is customizable for different choices of N. This proposed CROLoss formulation defines a more generalized loss function space, covering most of the conventional loss functions as special cases. Furthermore, we develop the Lambda method, a gradient-based method that invites more flexibility and can further boost the system performance. We evaluate the proposed CROLoss on two public benchmark datasets. The results show that CROLoss achieves SOTA results over conventional loss functions for both datasets with various choices of retrieval size N. CROLoss has been deployed onto our online E-commerce advertising platform, where a fourteen-day online A/B test demonstrated that CROLoss contributes to a significant business revenue growth of 4.75%.
DropNAS: Grouped Operation Dropout for Differentiable Architecture Search
Jan 27, 2022Neural architecture search (NAS) has shown encouraging results in automating the architecture design. Recently, DARTS relaxes the search process with a differentiable formulation that leverages weight-sharing and SGD where all candidate operations are trained simultaneously. Our empirical results show that such procedure results in the co-adaption problem and Matthew Effect: operations with fewer parameters would be trained maturely earlier. This causes two problems: firstly, the operations with more parameters may never have the chance to express the desired function since those with less have already done the job; secondly, the system will punish those underperforming operations by lowering their architecture parameter, and they will get smaller loss gradients, which causes the Matthew Effect. In this paper, we systematically study these problems and propose a novel grouped operation dropout algorithm named DropNAS to fix the problems with DARTS. Extensive experiments demonstrate that DropNAS solves the above issues and achieves promising performance. Specifically, DropNAS achieves 2.26% test error on CIFAR-10, 16.39% on CIFAR-100 and 23.4% on ImageNet (with the same training hyperparameters as DARTS for a fair comparison). It is also observed that DropNAS is robust across variants of the DARTS search space. Code is available at https://github.com/wiljohnhong/DropNAS.
Relaxed Conditional Image Transfer for Semi-supervised Domain Adaptation
Jan 05, 2021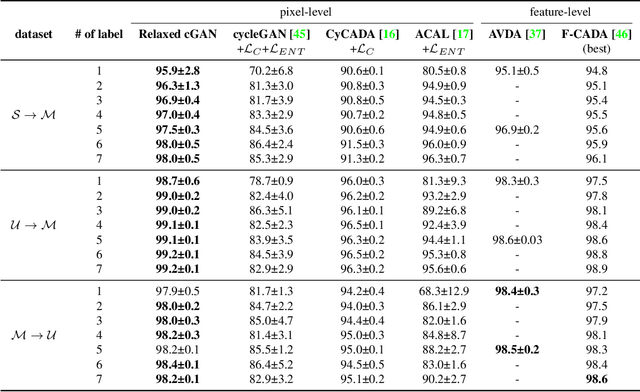
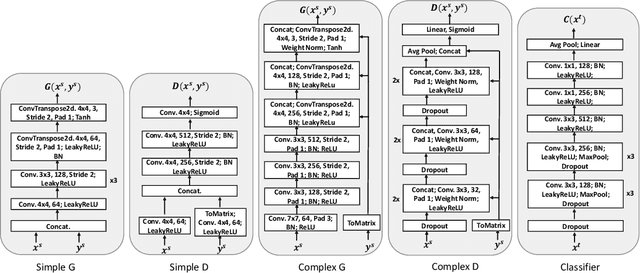
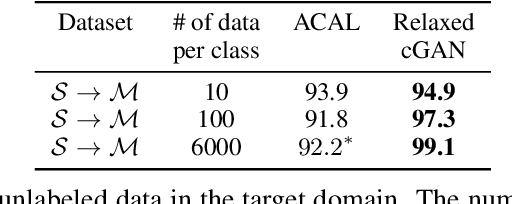
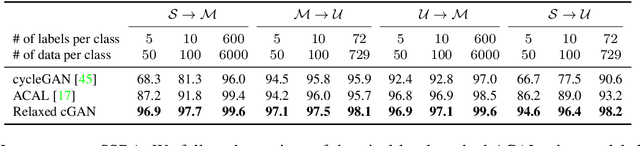
Semi-supervised domain adaptation (SSDA), which aims to learn models in a partially labeled target domain with the assistance of the fully labeled source domain, attracts increasing attention in recent years. To explicitly leverage the labeled data in both domains, we naturally introduce a conditional GAN framework to transfer images without changing the semantics in SSDA. However, we identify a label-domination problem in such an approach. In fact, the generator tends to overlook the input source image and only memorizes prototypes of each class, which results in unsatisfactory adaptation performance. To this end, we propose a simple yet effective Relaxed conditional GAN (Relaxed cGAN) framework. Specifically, we feed the image without its label to our generator. In this way, the generator has to infer the semantic information of input data. We formally prove that its equilibrium is desirable and empirically validate its practical convergence and effectiveness in image transfer. Additionally, we propose several techniques to make use of unlabeled data in the target domain, enhancing the model in SSDA settings. We validate our method on the well-adopted datasets: Digits, DomainNet, and Office-Home. We achieve state-of-the-art performance on DomainNet, Office-Home and most digit benchmarks in low-resource and high-resource settings.
AutoFIS: Automatic Feature Interaction Selection in Factorization Models for Click-Through Rate Prediction
Mar 26, 2020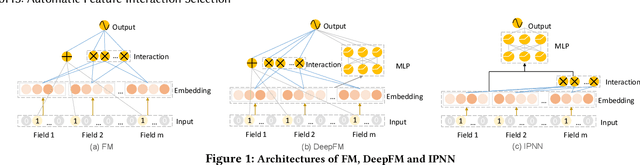
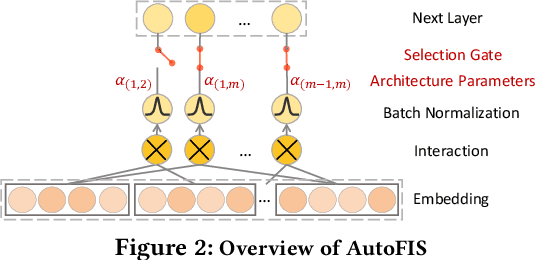
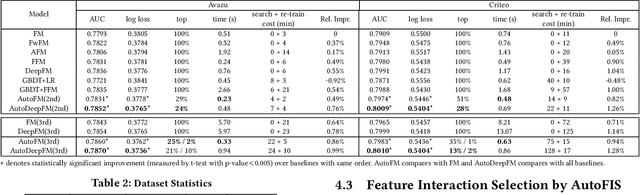
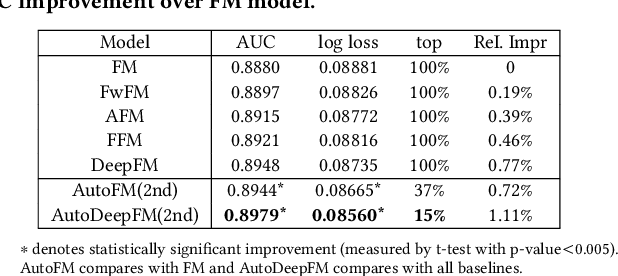
Learning effective feature interactions is crucial for click-through rate (CTR) prediction tasks in recommender systems. In most of the existing deep learning models, feature interactions are either manually designed or simply enumerated. However, enumerating all feature interactions brings large memory and computation cost. Even worse, useless interactions may introduce unnecessary noise and complicate the training process. In this work, we propose a two-stage algorithm called Automatic Feature Interaction Selection (AutoFIS). AutoFIS can automatically identify all the important feature interactions for factorization models with just the computational cost equivalent to training the target model to convergence. In the \emph{search stage}, instead of searching over a discrete set of candidate feature interactions, we relax the choices to be continuous by introducing the architecture parameters. By implementing a regularized optimizer over the architecture parameters, the model can automatically identify and remove the redundant feature interactions during the training process of the model. In the \emph{re-train stage}, we keep the architecture parameters serving as an attention unit to further boost the performance. Offline experiments on three large-scale datasets (two public benchmarks, one private) demonstrate that the proposed AutoFIS can significantly improve various FM based models. AutoFIS has been deployed onto the training platform of Huawei App Store recommendation service, where a 10-day online A/B test demonstrated that AutoFIS improved the DeepFM model by 20.3\% and 20.1\% in terms of CTR and CVR respectively.