 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Dec 31, 2025Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose \textbf{Youtu-Agent}, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a \textbf{Workflow} mode for standard tasks and a \textbf{Meta-Agent} mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an \textbf{Agent Practice} module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an \textbf{Agent RL} module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47\%) and GAIA (72.8\%) using open-weight models. Our automated generation pipeline achieves over 81\% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7\% and +5.4\% respectively. Moreover, our Agent RL training achieves 40\% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35\% and 21\% on Maths and general/multi-hop QA benchmarks.
SmartSnap: Proactive Evidence Seeking for Self-Verifying Agents
Dec 26, 2025Agentic reinforcement learning (RL) holds great promise for the development of autonomous agents under complex GUI tasks, but its scalability remains severely hampered by the verification of task completion. Existing task verification is treated as a passive, post-hoc process: a verifier (i.e., rule-based scoring script, reward or critic model, and LLM-as-a-Judge) analyzes the agent's entire interaction trajectory to determine if the agent succeeds. Such processing of verbose context that contains irrelevant, noisy history poses challenges to the verification protocols and therefore leads to prohibitive cost and low reliability. To overcome this bottleneck, we propose SmartSnap, a paradigm shift from this passive, post-hoc verification to proactive, in-situ self-verification by the agent itself. We introduce the Self-Verifying Agent, a new type of agent designed with dual missions: to not only complete a task but also to prove its accomplishment with curated snapshot evidences. Guided by our proposed 3C Principles (Completeness, Conciseness, and Creativity), the agent leverages its accessibility to the online environment to perform self-verification on a minimal, decisive set of snapshots. Such evidences are provided as the sole materials for a general LLM-as-a-Judge verifier to determine their validity and relevance. Experiments on mobile tasks across model families and scales demonstrate that our SmartSnap paradigm allows training LLM-driven agents in a scalable manner, bringing performance gains up to 26.08% and 16.66% respectively to 8B and 30B models. The synergizing between solution finding and evidence seeking facilitates the cultivation of efficient, self-verifying agents with competitive performance against DeepSeek V3.1 and Qwen3-235B-A22B.
Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
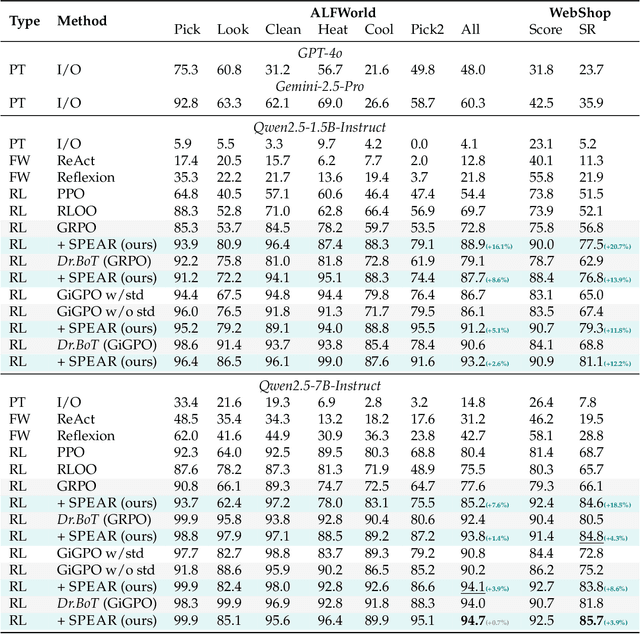
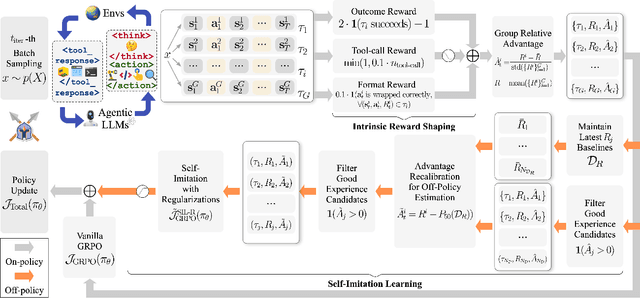
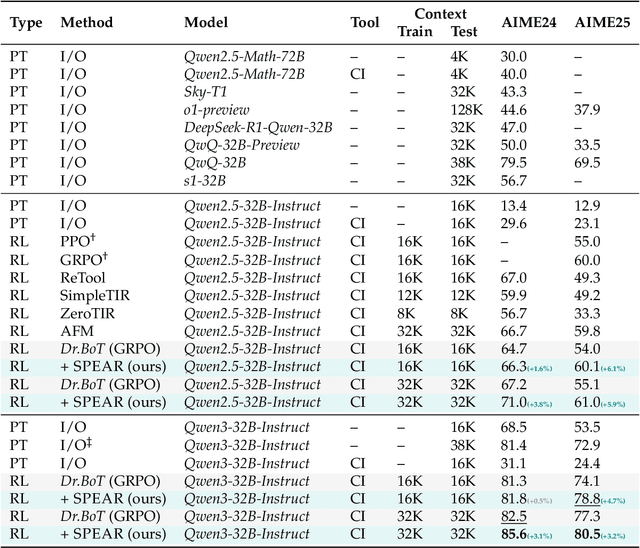
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
QuoTA: Query-oriented Token Assignment via CoT Query Decouple for Long Video Comprehension
Mar 11, 2025



Recent advances in long video understanding typically mitigate visual redundancy through visual token pruning based on attention distribution. However, while existing methods employ post-hoc low-response token pruning in decoder layers, they overlook the input-level semantic correlation between visual tokens and instructions (query). In this paper, we propose QuoTA, an ante-hoc training-free modular that extends existing large video-language models (LVLMs) for visual token assignment based on query-oriented frame-level importance assessment. The query-oriented token selection is crucial as it aligns visual processing with task-specific requirements, optimizing token budget utilization while preserving semantically relevant content. Specifically, (i) QuoTA strategically allocates frame-level importance scores based on query relevance, enabling one-time visual token assignment before cross-modal interactions in decoder layers, (ii) we decouple the query through Chain-of-Thoughts reasoning to facilitate more precise LVLM-based frame importance scoring, and (iii) QuoTA offers a plug-and-play functionality that extends to existing LVLMs. Extensive experimental results demonstrate that implementing QuoTA with LLaVA-Video-7B yields an average performance improvement of 3.2% across six benchmarks (including Video-MME and MLVU) while operating within an identical visual token budget as the baseline. Codes are open-sourced at https://github.com/MAC-AutoML/QuoTA.
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Jan 03, 2025



Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
Video-RAG: Visually-aligned Retrieval-Augmented Long Video Comprehension
Nov 20, 2024



Existing large video-language models (LVLMs) struggle to comprehend long videos correctly due to limited context. To address this problem, fine-tuning long-context LVLMs and employing GPT-based agents have emerged as promising solutions. However, fine-tuning LVLMs would require extensive high-quality data and substantial GPU resources, while GPT-based agents would rely on proprietary models (e.g., GPT-4o). In this paper, we propose Video Retrieval-Augmented Generation (Video-RAG), a training-free and cost-effective pipeline that employs visually-aligned auxiliary texts to help facilitate cross-modality alignment while providing additional information beyond the visual content. Specifically, we leverage open-source external tools to extract visually-aligned information from pure video data (e.g., audio, optical character, and object detection), and incorporate the extracted information into an existing LVLM as auxiliary texts, alongside video frames and queries, in a plug-and-play manner. Our Video-RAG offers several key advantages: (i) lightweight with low computing overhead due to single-turn retrieval; (ii) easy implementation and compatibility with any LVLM; and (iii) significant, consistent performance gains across long video understanding benchmarks, including Video-MME, MLVU, and LongVideoBench. Notably, our model demonstrates superior performance over proprietary models like Gemini-1.5-Pro and GPT-4o when utilized with a 72B model.
VITA: Towards Open-Source Interactive Omni Multimodal LLM
Aug 09, 2024



The remarkable multimodal capabilities and interactive experience of GPT-4o underscore their necessity in practical applications, yet open-source models rarely excel in both areas. In this paper, we introduce VITA, the first-ever open-source Multimodal Large Language Model (MLLM) adept at simultaneous processing and analysis of Video, Image, Text, and Audio modalities, and meanwhile has an advanced multimodal interactive experience. Starting from Mixtral 8x7B as a language foundation, we expand its Chinese vocabulary followed by bilingual instruction tuning. We further endow the language model with visual and audio capabilities through two-stage multi-task learning of multimodal alignment and instruction tuning. VITA demonstrates robust foundational capabilities of multilingual, vision, and audio understanding, as evidenced by its strong performance across a range of both unimodal and multimodal benchmarks. Beyond foundational capabilities, we have made considerable progress in enhancing the natural multimodal human-computer interaction experience. To the best of our knowledge, we are the first to exploit non-awakening interaction and audio interrupt in MLLM. VITA is the first step for the open-source community to explore the seamless integration of multimodal understanding and interaction. While there is still lots of work to be done on VITA to get close to close-source counterparts, we hope that its role as a pioneer can serve as a cornerstone for subsequent research. Project Page: https://vita-home.github.io.
Rethinking 3D Dense Caption and Visual Grounding in A Unified Framework through Prompt-based Localization
Apr 17, 2024



3D Visual Grounding (3DVG) and 3D Dense Captioning (3DDC) are two crucial tasks in various 3D applications, which require both shared and complementary information in localization and visual-language relationships. Therefore, existing approaches adopt the two-stage "detect-then-describe/discriminate" pipeline, which relies heavily on the performance of the detector, resulting in suboptimal performance. Inspired by DETR, we propose a unified framework, 3DGCTR, to jointly solve these two distinct but closely related tasks in an end-to-end fashion. The key idea is to reconsider the prompt-based localization ability of the 3DVG model. In this way, the 3DVG model with a well-designed prompt as input can assist the 3DDC task by extracting localization information from the prompt. In terms of implementation, we integrate a Lightweight Caption Head into the existing 3DVG network with a Caption Text Prompt as a connection, effectively harnessing the existing 3DVG model's inherent localization capacity, thereby boosting 3DDC capability. This integration facilitates simultaneous multi-task training on both tasks, mutually enhancing their performance. Extensive experimental results demonstrate the effectiveness of this approach. Specifically, on the ScanRefer dataset, 3DGCTR surpasses the state-of-the-art 3DDC method by 4.3% in CIDEr@0.5IoU in MLE training and improves upon the SOTA 3DVG method by 3.16% in Acc@0.25IoU.
A Unified Framework for 3D Point Cloud Visual Grounding
Aug 23, 2023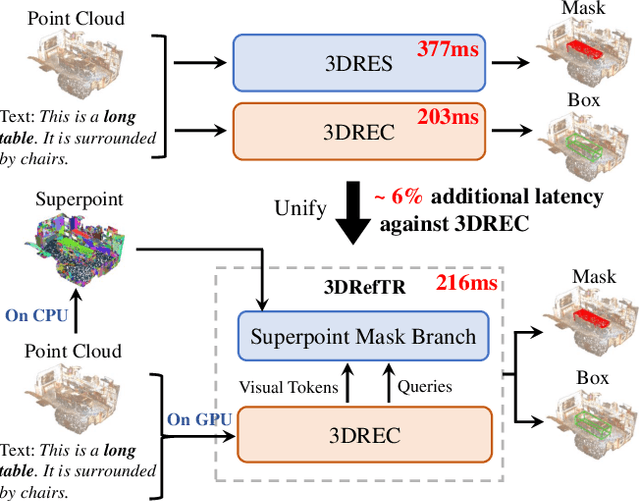
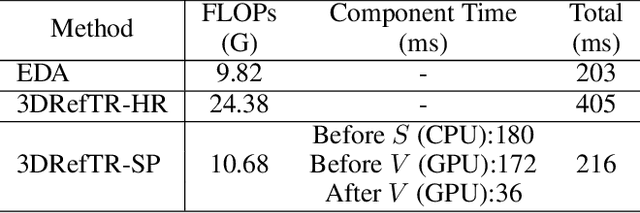
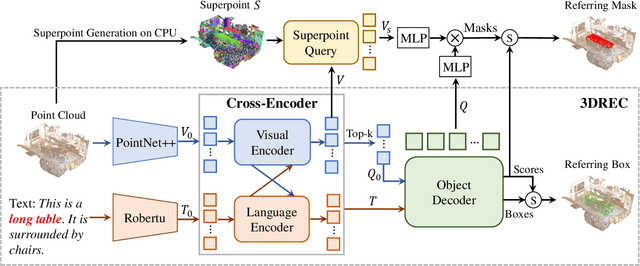

3D point cloud visual grounding plays a critical role in 3D scene comprehension, encompassing 3D referring expression comprehension (3DREC) and segmentation (3DRES). We argue that 3DREC and 3DRES should be unified in one framework, which is also a natural progression in the community. To explain, 3DREC can help 3DRES locate the referent, while 3DRES can also facilitate 3DREC via more finegrained language-visual alignment. To achieve this, this paper takes the initiative step to integrate 3DREC and 3DRES into a unified framework, termed 3D Referring Transformer (3DRefTR). Its key idea is to build upon a mature 3DREC model and leverage ready query embeddings and visual tokens from the 3DREC model to construct a dedicated mask branch. Specially, we propose Superpoint Mask Branch, which serves a dual purpose: i) By leveraging the heterogeneous CPU-GPU parallelism, while the GPU is occupied generating visual tokens, the CPU concurrently produces superpoints, equivalently accomplishing the upsampling computation; ii) By harnessing on the inherent association between the superpoints and point cloud, it eliminates the heavy computational overhead on the high-resolution visual features for upsampling. This elegant design enables 3DRefTR to achieve both well-performing 3DRES and 3DREC capacities with only a 6% additional latency compared to the original 3DREC model. Empirical evaluations affirm the superiority of 3DRefTR. Specifically, on the ScanRefer dataset, 3DRefTR surpasses the state-of-the-art 3DRES method by 12.43% in mIoU and improves upon the SOTA 3DREC method by 0.6% Acc@0.25IoU.