 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVITA-VLA: Efficiently Teaching Vision-Language Models to Act via Action Expert Distillation
Oct 10, 2025Vision-Language Action (VLA) models significantly advance robotic manipulation by leveraging the strong perception capabilities of pretrained vision-language models (VLMs). By integrating action modules into these pretrained models, VLA methods exhibit improved generalization. However, training them from scratch is costly. In this work, we propose a simple yet effective distillation-based framework that equips VLMs with action-execution capability by transferring knowledge from pretrained small action models. Our architecture retains the original VLM structure, adding only an action token and a state encoder to incorporate physical inputs. To distill action knowledge, we adopt a two-stage training strategy. First, we perform lightweight alignment by mapping VLM hidden states into the action space of the small action model, enabling effective reuse of its pretrained action decoder and avoiding expensive pretraining. Second, we selectively fine-tune the language model, state encoder, and action modules, enabling the system to integrate multimodal inputs with precise action generation. Specifically, the action token provides the VLM with a direct handle for predicting future actions, while the state encoder allows the model to incorporate robot dynamics not captured by vision alone. This design yields substantial efficiency gains over training large VLA models from scratch. Compared with previous state-of-the-art methods, our method achieves 97.3% average success rate on LIBERO (11.8% improvement) and 93.5% on LIBERO-LONG (24.5% improvement). In real-world experiments across five manipulation tasks, our method consistently outperforms the teacher model, achieving 82.0% success rate (17% improvement), which demonstrate that action distillation effectively enables VLMs to generate precise actions while substantially reducing training costs.
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuray
Feb 07, 2025Establishing the long-context capability of large vision-language models is crucial for video understanding, high-resolution image understanding, multi-modal agents and reasoning. We introduce Long-VITA, a simple yet effective large multi-modal model for long-context visual-language understanding tasks. It is adept at concurrently processing and analyzing modalities of image, video, and text over 4K frames or 1M tokens while delivering advanced performances on short-context multi-modal tasks. We propose an effective multi-modal training schema that starts with large language models and proceeds through vision-language alignment, general knowledge learning, and two sequential stages of long-sequence fine-tuning. We further implement context-parallelism distributed inference and logits-masked language modeling head to scale Long-VITA to infinitely long inputs of images and texts during model inference. Regarding training data, Long-VITA is built on a mix of $17$M samples from public datasets only and demonstrates the state-of-the-art performance on various multi-modal benchmarks, compared against recent cutting-edge models with internal data. Long-VITA is fully reproducible and supports both NPU and GPU platforms for training and testing. We hope Long-VITA can serve as a competitive baseline and offer valuable insights for the open-source community in advancing long-context multi-modal understanding.
LUCY: Linguistic Understanding and Control Yielding Early Stage of Her
Jan 27, 2025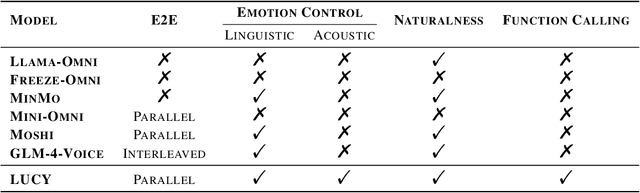
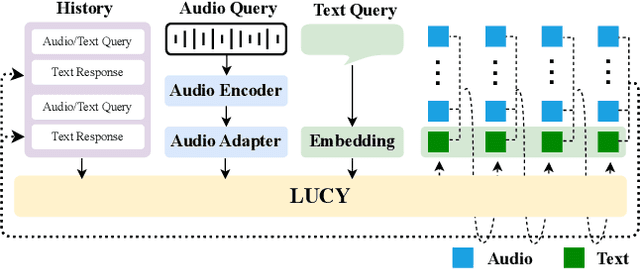
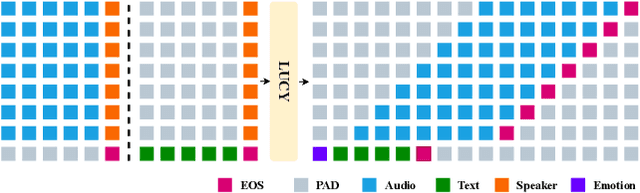
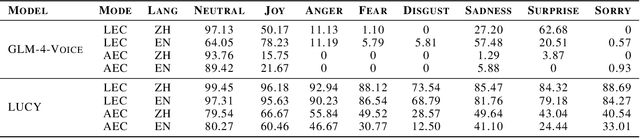
The film Her features Samantha, a sophisticated AI audio agent who is capable of understanding both linguistic and paralinguistic information in human speech and delivering real-time responses that are natural, informative and sensitive to emotional subtleties. Moving one step toward more sophisticated audio agent from recent advancement in end-to-end (E2E) speech systems, we propose LUCY, a E2E speech model that (1) senses and responds to user's emotion, (2) deliver responses in a succinct and natural style, and (3) use external tool to answer real-time inquiries. Experiment results show that LUCY is better at emotion control than peer models, generating emotional responses based on linguistic emotional instructions and responding to paralinguistic emotional cues. Lucy is also able to generate responses in a more natural style, as judged by external language models, without sacrificing much performance on general question answering. Finally, LUCY can leverage function calls to answer questions that are out of its knowledge scope.