 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Dec 31, 2025Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose \textbf{Youtu-Agent}, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a \textbf{Workflow} mode for standard tasks and a \textbf{Meta-Agent} mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an \textbf{Agent Practice} module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an \textbf{Agent RL} module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47\%) and GAIA (72.8\%) using open-weight models. Our automated generation pipeline achieves over 81\% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7\% and +5.4\% respectively. Moreover, our Agent RL training achieves 40\% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35\% and 21\% on Maths and general/multi-hop QA benchmarks.
LUCY: Linguistic Understanding and Control Yielding Early Stage of Her
Jan 27, 2025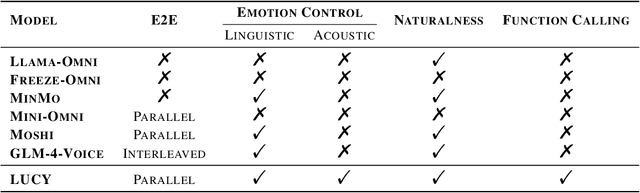
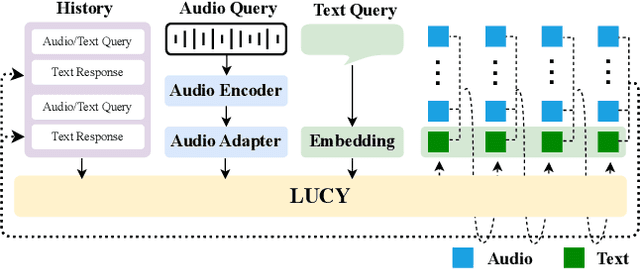
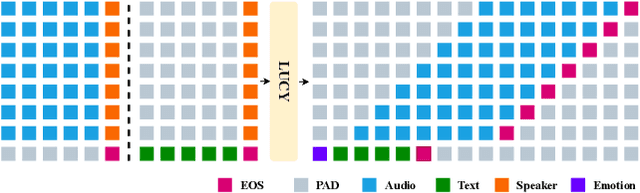
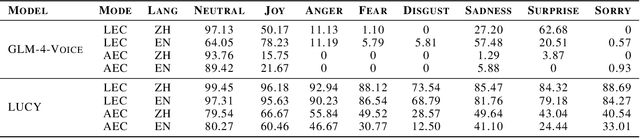
The film Her features Samantha, a sophisticated AI audio agent who is capable of understanding both linguistic and paralinguistic information in human speech and delivering real-time responses that are natural, informative and sensitive to emotional subtleties. Moving one step toward more sophisticated audio agent from recent advancement in end-to-end (E2E) speech systems, we propose LUCY, a E2E speech model that (1) senses and responds to user's emotion, (2) deliver responses in a succinct and natural style, and (3) use external tool to answer real-time inquiries. Experiment results show that LUCY is better at emotion control than peer models, generating emotional responses based on linguistic emotional instructions and responding to paralinguistic emotional cues. Lucy is also able to generate responses in a more natural style, as judged by external language models, without sacrificing much performance on general question answering. Finally, LUCY can leverage function calls to answer questions that are out of its knowledge scope.