 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSkill: Open-World Self-Evolution for LLM Agents
Jun 04, 2026Self-evolving agents requires adaptation after deployment, but existing approaches assume a usable learning loop, such as curated skills, successful trajectories, or verifier signals. Real open-world deployments may provide none of these, offering only a task prompt. In this work, we study open-world self-evolution, where an agent must build both its skills and its own verification signals from scratch, using open-world resources but no target-task supervision. We propose OpenSkill, a framework that bootstraps this loop: it acquires grounded knowledge and verification anchors from documentation, repositories, and the web, synthesizes them into transferable skills, and refines those skills against self-built virtual tasks grounded in the anchors rather than in target answers. The open world thus supplies both the knowledge to be learned and a supervision-independent practice environment, with target-task supervision reserved for final evaluation. Across three benchmarks and two target agents, OpenSkill attains the best automated pass rate while satisfying the no-supervision constraint. Analysis shows its skills transfer across models without model-specific adaptation, and its self-built verifier aligns with ground-truth outcomes despite never accessing them.
AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery
May 22, 2026Scientific research is being reshaped by AI systems that move beyond isolated assistance toward longer-horizon workflows spanning literature grounding, hypothesis generation, experimentation, validation, reporting, and revision. This shift marks a transition from task-level AI for science to workflow-level research automation. Yet current systems remain fragmented, differing in autonomy, domain scope, execution environment, validation mechanism, and human oversight, while still struggling with evidence preservation, reproducibility, weak-direction rejection, provenance tracking, cross-domain robustness, and accountable scientific closure. This survey examines these developments through AutoResearch, defined as the developmental spectrum of AI-powered scientific workflow automation. Within it, Vibe Research denotes the human-steered region of prompt-based assistance and human-verified execution, whereas emerging AI-led systems coordinate larger portions of the discovery loop without achieving robust autonomy. We analyze how research systems redistribute control, evidence, execution, validation, and accountability across workflows and organize the field around five workflow conditions: literature and research grounding; hypothesis formation and planning; experimentation and tool use; feedback, validation, and review; and reporting and knowledge communication. We further synthesize AI scientist systems, mixed-initiative co-research frameworks, benchmarks, domain deployments, and open-source infrastructures. Finally, we propose five evaluation dimensions--novelty, validity, impact, reliability, and provenance--and show that AutoResearch autonomy is domain-conditioned, being more credible in structured, executable, and rapidly verifiable settings but limited in embodied, delayed, heterogeneous, ethical, or institutionally accountable contexts.
Towards a Medical AI Scientist
Mar 30, 2026Autonomous systems that generate scientific hypotheses, conduct experiments, and draft manuscripts have recently emerged as a promising paradigm for accelerating discovery. However, existing AI Scientists remain largely domain-agnostic, limiting their applicability to clinical medicine, where research is required to be grounded in medical evidence with specialized data modalities. In this work, we introduce Medical AI Scientist, the first autonomous research framework tailored to clinical autonomous research. It enables clinically grounded ideation by transforming extensively surveyed literature into actionable evidence through clinician-engineer co-reasoning mechanism, which improves the traceability of generated research ideas. It further facilitates evidence-grounded manuscript drafting guided by structured medical compositional conventions and ethical policies. The framework operates under 3 research modes, namely paper-based reproduction, literature-inspired innovation, and task-driven exploration, each corresponding to a distinct level of automated scientific inquiry with progressively increasing autonomy. Comprehensive evaluations by both large language models and human experts demonstrate that the ideas generated by the Medical AI Scientist are of substantially higher quality than those produced by commercial LLMs across 171 cases, 19 clinical tasks, and 6 data modalities. Meanwhile, our system achieves strong alignment between the proposed method and its implementation, while also demonstrating significantly higher success rates in executable experiments. Double-blind evaluations by human experts and the Stanford Agentic Reviewer suggest that the generated manuscripts approach MICCAI-level quality, while consistently surpassing those from ISBI and BIBM. The proposed Medical AI Scientist highlights the potential of leveraging AI for autonomous scientific discovery in healthcare.
Can MLLMs Read Students' Minds? Unpacking Multimodal Error Analysis in Handwritten Math
Mar 26, 2026Assessing student handwritten scratchwork is crucial for personalized educational feedback but presents unique challenges due to diverse handwriting, complex layouts, and varied problem-solving approaches. Existing educational NLP primarily focuses on textual responses and neglects the complexity and multimodality inherent in authentic handwritten scratchwork. Current multimodal large language models (MLLMs) excel at visual reasoning but typically adopt an "examinee perspective", prioritizing generating correct answers rather than diagnosing student errors. To bridge these gaps, we introduce ScratchMath, a novel benchmark specifically designed for explaining and classifying errors in authentic handwritten mathematics scratchwork. Our dataset comprises 1,720 mathematics samples from Chinese primary and middle school students, supporting two key tasks: Error Cause Explanation (ECE) and Error Cause Classification (ECC), with seven defined error types. The dataset is meticulously annotated through rigorous human-machine collaborative approaches involving multiple stages of expert labeling, review, and verification. We systematically evaluate 16 leading MLLMs on ScratchMath, revealing significant performance gaps relative to human experts, especially in visual recognition and logical reasoning. Proprietary models notably outperform open-source models, with large reasoning models showing strong potential for error explanation. All evaluation data and frameworks are publicly available to facilitate further research.
LiveMedBench: A Contamination-Free Medical Benchmark for LLMs with Automated Rubric Evaluation
Feb 10, 2026The deployment of Large Language Models (LLMs) in high-stakes clinical settings demands rigorous and reliable evaluation. However, existing medical benchmarks remain static, suffering from two critical limitations: (1) data contamination, where test sets inadvertently leak into training corpora, leading to inflated performance estimates; and (2) temporal misalignment, failing to capture the rapid evolution of medical knowledge. Furthermore, current evaluation metrics for open-ended clinical reasoning often rely on either shallow lexical overlap (e.g., ROUGE) or subjective LLM-as-a-Judge scoring, both inadequate for verifying clinical correctness. To bridge these gaps, we introduce LiveMedBench, a continuously updated, contamination-free, and rubric-based benchmark that weekly harvests real-world clinical cases from online medical communities, ensuring strict temporal separation from model training data. We propose a Multi-Agent Clinical Curation Framework that filters raw data noise and validates clinical integrity against evidence-based medical principles. For evaluation, we develop an Automated Rubric-based Evaluation Framework that decomposes physician responses into granular, case-specific criteria, achieving substantially stronger alignment with expert physicians than LLM-as-a-Judge. To date, LiveMedBench comprises 2,756 real-world cases spanning 38 medical specialties and multiple languages, paired with 16,702 unique evaluation criteria. Extensive evaluation of 38 LLMs reveals that even the best-performing model achieves only 39.2%, and 84% of models exhibit performance degradation on post-cutoff cases, confirming pervasive data contamination risks. Error analysis further identifies contextual application-not factual knowledge-as the dominant bottleneck, with 35-48% of failures stemming from the inability to tailor medical knowledge to patient-specific constraints.
Enhancing Vector Quantization with Distributional Matching: A Theoretical and Empirical Study
Jun 18, 2025The success of autoregressive models largely depends on the effectiveness of vector quantization, a technique that discretizes continuous features by mapping them to the nearest code vectors within a learnable codebook. Two critical issues in existing vector quantization methods are training instability and codebook collapse. Training instability arises from the gradient discrepancy introduced by the straight-through estimator, especially in the presence of significant quantization errors, while codebook collapse occurs when only a small subset of code vectors are utilized during training. A closer examination of these issues reveals that they are primarily driven by a mismatch between the distributions of the features and code vectors, leading to unrepresentative code vectors and significant data information loss during compression. To address this, we employ the Wasserstein distance to align these two distributions, achieving near 100\% codebook utilization and significantly reducing the quantization error. Both empirical and theoretical analyses validate the effectiveness of the proposed approach.
Agentic Robot: A Brain-Inspired Framework for Vision-Language-Action Models in Embodied Agents
May 29, 2025Long-horizon robotic manipulation poses significant challenges for autonomous systems, requiring extended reasoning, precise execution, and robust error recovery across complex sequential tasks. Current approaches, whether based on static planning or end-to-end visuomotor policies, suffer from error accumulation and lack effective verification mechanisms during execution, limiting their reliability in real-world scenarios. We present Agentic Robot, a brain-inspired framework that addresses these limitations through Standardized Action Procedures (SAP)--a novel coordination protocol governing component interactions throughout manipulation tasks. Drawing inspiration from Standardized Operating Procedures (SOPs) in human organizations, SAP establishes structured workflows for planning, execution, and verification phases. Our architecture comprises three specialized components: (1) a large reasoning model that decomposes high-level instructions into semantically coherent subgoals, (2) a vision-language-action executor that generates continuous control commands from real-time visual inputs, and (3) a temporal verifier that enables autonomous progression and error recovery through introspective assessment. This SAP-driven closed-loop design supports dynamic self-verification without external supervision. On the LIBERO benchmark, Agentic Robot achieves state-of-the-art performance with an average success rate of 79.6\%, outperforming SpatialVLA by 6.1\% and OpenVLA by 7.4\% on long-horizon tasks. These results demonstrate that SAP-driven coordination between specialized components enhances both performance and interpretability in sequential manipulation, suggesting significant potential for reliable autonomous systems. Project Github: https://agentic-robot.github.io.
Aligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025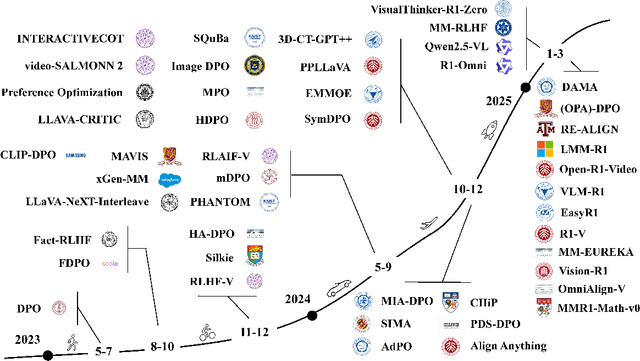
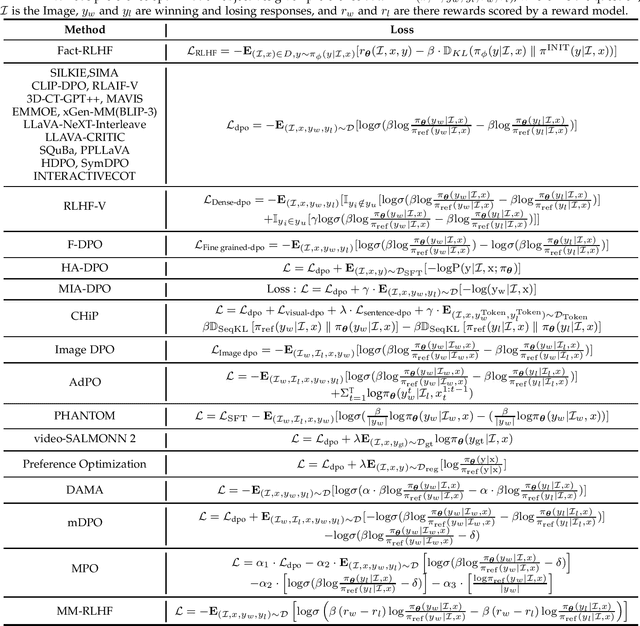
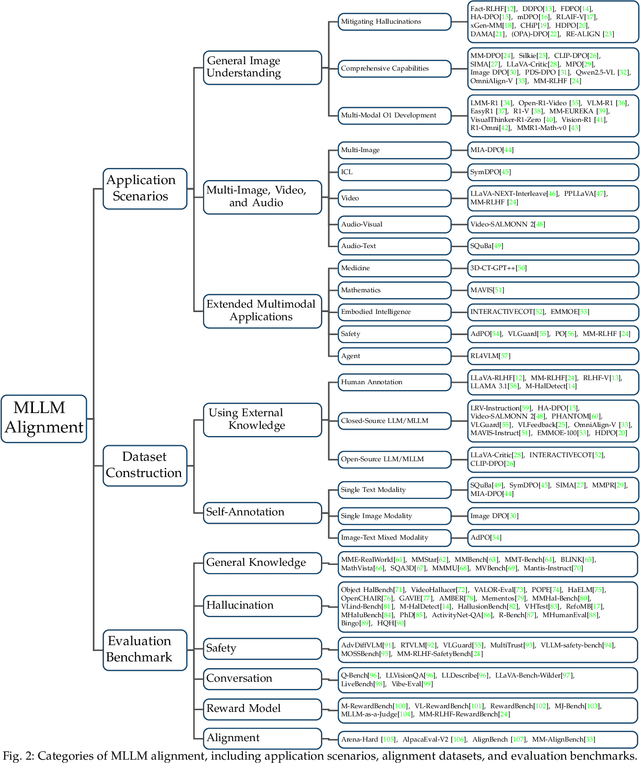

Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
A Survey on Post-training of Large Language Models
Mar 08, 2025The emergence of Large Language Models (LLMs) has fundamentally transformed natural language processing, making them indispensable across domains ranging from conversational systems to scientific exploration. However, their pre-trained architectures often reveal limitations in specialized contexts, including restricted reasoning capacities, ethical uncertainties, and suboptimal domain-specific performance. These challenges necessitate advanced post-training language models (PoLMs) to address these shortcomings, such as OpenAI-o1/o3 and DeepSeek-R1 (collectively known as Large Reasoning Models, or LRMs). This paper presents the first comprehensive survey of PoLMs, systematically tracing their evolution across five core paradigms: Fine-tuning, which enhances task-specific accuracy; Alignment, which ensures alignment with human preferences; Reasoning, which advances multi-step inference despite challenges in reward design; Efficiency, which optimizes resource utilization amidst increasing complexity; and Integration and Adaptation, which extend capabilities across diverse modalities while addressing coherence issues. Charting progress from ChatGPT's foundational alignment strategies to DeepSeek-R1's innovative reasoning advancements, we illustrate how PoLMs leverage datasets to mitigate biases, deepen reasoning capabilities, and enhance domain adaptability. Our contributions include a pioneering synthesis of PoLM evolution, a structured taxonomy categorizing techniques and datasets, and a strategic agenda emphasizing the role of LRMs in improving reasoning proficiency and domain flexibility. As the first survey of its scope, this work consolidates recent PoLM advancements and establishes a rigorous intellectual framework for future research, fostering the development of LLMs that excel in precision, ethical robustness, and versatility across scientific and societal applications.
From Correctness to Comprehension: AI Agents for Personalized Error Diagnosis in Education
Feb 19, 2025



Large Language Models (LLMs), such as GPT-4, have demonstrated impressive mathematical reasoning capabilities, achieving near-perfect performance on benchmarks like GSM8K. However, their application in personalized education remains limited due to an overemphasis on correctness over error diagnosis and feedback generation. Current models fail to provide meaningful insights into the causes of student mistakes, limiting their utility in educational contexts. To address these challenges, we present three key contributions. First, we introduce \textbf{MathCCS} (Mathematical Classification and Constructive Suggestions), a multi-modal benchmark designed for systematic error analysis and tailored feedback. MathCCS includes real-world problems, expert-annotated error categories, and longitudinal student data. Evaluations of state-of-the-art models, including \textit{Qwen2-VL}, \textit{LLaVA-OV}, \textit{Claude-3.5-Sonnet} and \textit{GPT-4o}, reveal that none achieved classification accuracy above 30\% or generated high-quality suggestions (average scores below 4/10), highlighting a significant gap from human-level performance. Second, we develop a sequential error analysis framework that leverages historical data to track trends and improve diagnostic precision. Finally, we propose a multi-agent collaborative framework that combines a Time Series Agent for historical analysis and an MLLM Agent for real-time refinement, enhancing error classification and feedback generation. Together, these contributions provide a robust platform for advancing personalized education, bridging the gap between current AI capabilities and the demands of real-world teaching.