 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKairosAgent: Agentic Time Series Forecasting with Fused Semantic Reasoning
May 28, 2026Cross-domain multimodal time series forecasting is a challenging task, requiring models to integrate precise numerical comprehension, cross-domain semantic understanding, and effective multimodal fusion. Existing approaches either build Time Series Foundation Models (TSFMs) from scratch or leverage pretrained Large Language Models (LLMs). However, TSFMs often overlook semantic understanding and lack the ability to perform future-oriented semantic reasoning, and LLMs struggle with numerical comprehension and accurate quantitative forecasting. To overcome these limitations, we propose KairosAgent, a novel agentic framework for multimodal time series forecasting, including an LLM-based reasoner and a TSFM-based forecaster. KairosAgent unifies textual reasoning and numerical forecasting by dynamically invoking analytical tools to enhance the numerical understanding and semantic reasoning capabilities of LLMs. The reasoning results are subsequently fused into the TSFM pipeline, enabling more accurate and reliable future predictions. To further improve the reasoning, we curate a large-scale corpus of high-quality trajectories, alongside a reinforcement learning from forecasting paradigm with multi-turn refinement and turn-level credit assignment. Experiments demonstrate that KairosAgent achieves superior zero-shot forecasting performance while maximizing the utility of pretrained LLMs and TSFMs, presenting a promising direction for efficient and interpretable time series agents. The project page is at https://foundation-model-research.github.io/KairosAgent .
OptSkills: Learning Generalizable Optimization Skills from Problem Archetypes via Cluster-Based Distillation
May 28, 2026Leveraging Large Language Models (LLMs) to automatically formulate and solve optimization problems from natural language has emerged as an efficient paradigm for automated optimization. However, existing methods still exhibit limited generalization: they are sensitive to superficial narrative variations, reuse experience mainly at the case level, and struggle to adapt to shifted or emerging problem types. We propose OptSkills, an archetype-centric skill learning and reasoning agent system for optimization modeling and solving. To improve robust generalization, our system clusters problems by their underlying archetypes rather than surface narratives. To improve in-distribution generalization, it explores diverse modeling paradigms and solver configurations within each cluster, then distills successful trajectories into reusable workflow-level skills. To improve out-of-distribution generalization, it refines existing skills or expands the skill library using newly obtained trajectories. Our system achieves a state-of-the-art micro-averaged accuracy of 68.27% on datasets encompassing diverse problem types and scenarios. In addition, on MIPLIB-NL, a highly challenging large-scale and high-dimensional benchmark, it achieves 26.91% accuracy, outperforming DeepSeek-V3.2-Thinking by 4.53%. After skill learning on Nano-CO, it reaches 72.79% on the OOD NLCO benchmark. Code and skills are available at https://github.com/fujiwaranoM0kou/OptSkills.
VCap: Hypergeometric Rewards for Weak-to-Strong Visual Captioning
May 27, 2026Visual captioning requires models to capture visual content faithfully while minimizing both omission and hallucination. As the dominant paradigm for captioning, MLLMs have achieved strong performance through scaling and high-quality data. Recently, RL has emerged as a key route to driving MLLMs toward higher precision and broader coverage, however, existing reward designs for captioning fail to provide fine-grained and reliable signals for factual verification, limiting their effectiveness. To address this, we propose VCap, a Witness-Adjudicator reward that pairs the reference caption (a witness) with the visual signal (an adjudicator). By explicitly verifying factual consistency between the reference and policy-generated captions grounded in the visual signal, VCap delivers a reward signal with hypergeometric-distribution-level precision for caption quality verification. This design enables effective learning even from imperfect references, facilitating weak-to-strong generalization in RL training. In our experiments, an 8B model trained with VCap outperforms open- and closed-source SOTA models on multiple image and video captioning benchmarks. Human evaluation further confirms its strong alignment with factual correctness. Additionally, VCap improves MLLM perceptual capability, generalizes across tasks, and surpasses best-of-N distillation, challenging prior assumptions about RLVR.
SepSeq: A Training-Free Framework for Long Numerical Sequence Processing in LLMs
Apr 09, 2026While transformer-based Large Language Models (LLMs) theoretically support massive context windows, they suffer from severe performance degradation when processing long numerical sequences. We attribute this failure to the attention dispersion in the Softmax mechanism, which prevents the model from concentrating attention. To overcome this, we propose Separate Sequence (SepSeq), a training-free, plug-and-play framework to mitigate dispersion by strategically inserting separator tokens. Mechanistically, we demonstrate that separator tokens act as an attention sink, recalibrating attention to focus on local segments while preserving global context. Extensive evaluations on 9 widely-adopted LLMs confirm the effectiveness of our approach: SepSeq yields an average relative accuracy improvement of 35.6% across diverse domains while reducing total inference token consumption by 16.4% on average.
ContextRL: Enhancing MLLM's Knowledge Discovery Efficiency with Context-Augmented RL
Feb 26, 2026We propose ContextRL, a novel framework that leverages context augmentation to overcome these bottlenecks. Specifically, to enhance Identifiability, we provide the reward model with full reference solutions as context, enabling fine-grained process verification to filter out false positives (samples with the right answer but low-quality reasoning process). To improve Reachability, we introduce a multi-turn sampling strategy where the reward model generates mistake reports for failed attempts, guiding the policy to "recover" correct responses from previously all-negative groups. Experimental results on 11 perception and reasoning benchmarks show that ContextRL significantly improves knowledge discovery efficiency. Notably, ContextRL enables the Qwen3-VL-8B model to achieve performance comparable to the 32B model, outperforming standard RLVR baselines by a large margin while effectively mitigating reward hacking. Our in-depth analysis reveals the significant potential of contextual information for improving reward model accuracy and document the widespread occurrence of reward hacking, offering valuable insights for future RLVR research.
Primary-Fine Decoupling for Action Generation in Robotic Imitation
Feb 25, 2026Multi-modal distribution in robotic manipulation action sequences poses critical challenges for imitation learning. To this end, existing approaches often model the action space as either a discrete set of tokens or a continuous, latent-variable distribution. However, both approaches present trade-offs: some methods discretize actions into tokens and therefore lose fine-grained action variations, while others generate continuous actions in a single stage tend to produce unstable mode transitions. To address these limitations, we propose Primary-Fine Decoupling for Action Generation (PF-DAG), a two-stage framework that decouples coarse action consistency from fine-grained variations. First, we compress action chunks into a small set of discrete modes, enabling a lightweight policy to select consistent coarse modes and avoid mode bouncing. Second, a mode conditioned MeanFlow policy is learned to generate high-fidelity continuous actions. Theoretically, we prove PF-DAG's two-stage design achieves a strictly lower MSE bound than single-stage generative policies. Empirically, PF-DAG outperforms state-of-the-art baselines across 56 tasks from Adroit, DexArt, and MetaWorld benchmarks. It further generalizes to real-world tactile dexterous manipulation tasks. Our work demonstrates that explicit mode-level decoupling enables both robust multi-modal modeling and reactive closed-loop control for robotic manipulation.
GhostShell: Streaming LLM Function Calls for Concurrent Embodied Programming
Aug 07, 2025



We present GhostShell, a novel approach that leverages Large Language Models (LLMs) to enable streaming and concurrent behavioral programming for embodied systems. In contrast to conventional methods that rely on pre-scheduled action sequences or behavior trees, GhostShell drives embodied systems to act on-the-fly by issuing function calls incrementally as tokens are streamed from the LLM. GhostShell features a streaming XML function token parser, a dynamic function interface mapper, and a multi-channel scheduler that orchestrates intra-channel synchronous and inter-channel asynchronous function calls, thereby coordinating serial-parallel embodied actions across multiple robotic components as directed by the LLM. We evaluate GhostShell on our robot prototype COCO through comprehensive grounded experiments across 34 real-world interaction tasks and multiple LLMs. The results demonstrate that our approach achieves state-of-the-art Behavioral Correctness Metric of 0.85 with Claude-4 Sonnet and up to 66X faster response times compared to LLM native function calling APIs. GhostShell also proves effective in long-horizon multimodal tasks, demonstrating strong robustness and generalization.
Precise Representation Model of SAR Saturated Interference: Mechanism and Verification
Jul 09, 2025Synthetic Aperture Radar (SAR) is highly susceptible to Radio Frequency Interference (RFI). Due to the performance limitations of components such as gain controllers and analog-to-digital converters in SAR receivers, high-power interference can easily cause saturation of the SAR receiver, resulting in nonlinear distortion of the interfered echoes, which are distorted in both the time domain and frequency domain. Some scholars have analyzed the impact of SAR receiver saturation on target echoes through simulations. However, the saturation function has non-smooth characteristics, making it difficult to conduct accurate analysis using traditional analytical methods. Current related studies have approximated and analyzed the saturation function based on the hyperbolic tangent function, but there are approximation errors. Therefore, this paper proposes a saturation interference analysis model based on Bessel functions, and verifies the accuracy of the proposed saturation interference analysis model by simulating and comparing it with the traditional saturation model based on smooth function approximation. This model can provide certain guidance for further work such as saturation interference suppression.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
Why Distillation can Outperform Zero-RL: The Role of Flexible Reasoning
May 27, 2025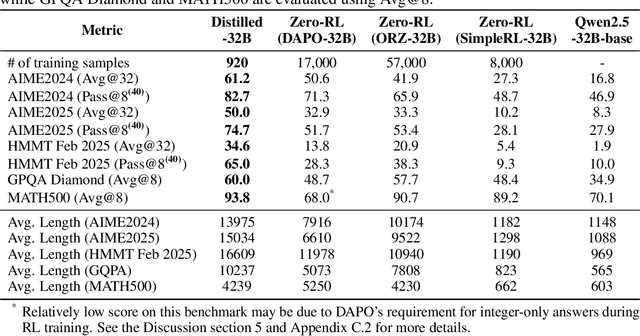
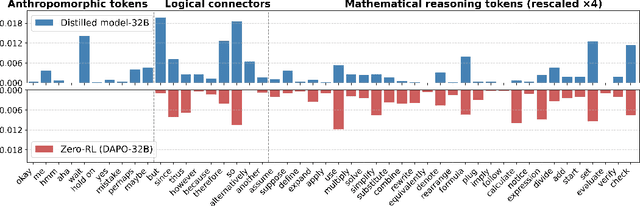

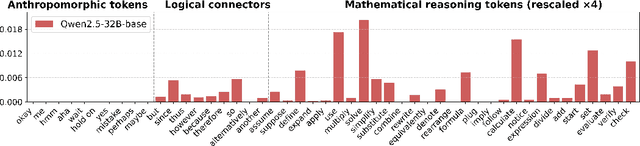
Reinforcement learning (RL) has played an important role in improving the reasoning ability of large language models (LLMs). Some studies apply RL directly to \textit{smaller} base models (known as zero-RL) and also achieve notable progress. However, in this paper, we show that using only 920 examples, a simple distillation method based on the base model can clearly outperform zero-RL, which typically requires much more data and computational cost. By analyzing the token frequency in model outputs, we find that the distilled model shows more flexible reasoning. It uses anthropomorphic tokens and logical connectors much more often than the zero-RL model. Further analysis reveals that distillation enhances the presence of two advanced cognitive behaviors: Multi-Perspective Thinking or Attempting and Metacognitive Awareness. Frequent occurrences of these two advanced cognitive behaviors give rise to flexible reasoning, which is essential for solving complex reasoning problems, while zero-RL fails to significantly boost the frequency of these behaviors.