 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning
Mar 10, 2025We present MM-Eureka, a multimodal reasoning model that successfully extends large-scale rule-based reinforcement learning (RL) to multimodal reasoning. While rule-based RL has shown remarkable success in improving LLMs' reasoning abilities in text domains, its application to multimodal settings has remained challenging. Our work reproduces key characteristics of text-based RL systems like DeepSeek-R1 in the multimodal space, including steady increases in accuracy reward and response length, and the emergence of reflection behaviors. We demonstrate that both instruction-tuned and pre-trained models can develop strong multimodal reasoning capabilities through rule-based RL without supervised fine-tuning, showing superior data efficiency compared to alternative approaches. We open-source our complete pipeline to foster further research in this area. We release all our codes, models, data, etc. at https://github.com/ModalMinds/MM-EUREKA
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
An Egocentric Vision-Language Model based Portable Real-time Smart Assistant
Mar 06, 2025We present Vinci, a vision-language system designed to provide real-time, comprehensive AI assistance on portable devices. At its core, Vinci leverages EgoVideo-VL, a novel model that integrates an egocentric vision foundation model with a large language model (LLM), enabling advanced functionalities such as scene understanding, temporal grounding, video summarization, and future planning. To enhance its utility, Vinci incorporates a memory module for processing long video streams in real time while retaining contextual history, a generation module for producing visual action demonstrations, and a retrieval module that bridges egocentric and third-person perspectives to provide relevant how-to videos for skill acquisition. Unlike existing systems that often depend on specialized hardware, Vinci is hardware-agnostic, supporting deployment across a wide range of devices, including smartphones and wearable cameras. In our experiments, we first demonstrate the superior performance of EgoVideo-VL on multiple public benchmarks, showcasing its vision-language reasoning and contextual understanding capabilities. We then conduct a series of user studies to evaluate the real-world effectiveness of Vinci, highlighting its adaptability and usability in diverse scenarios. We hope Vinci can establish a new framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. Including the frontend, backend, and models, all codes of Vinci are available at https://github.com/OpenGVLab/vinci.
Modeling Fine-Grained Hand-Object Dynamics for Egocentric Video Representation Learning
Mar 02, 2025



In egocentric video understanding, the motion of hands and objects as well as their interactions play a significant role by nature. However, existing egocentric video representation learning methods mainly focus on aligning video representation with high-level narrations, overlooking the intricate dynamics between hands and objects. In this work, we aim to integrate the modeling of fine-grained hand-object dynamics into the video representation learning process. Since no suitable data is available, we introduce HOD, a novel pipeline employing a hand-object detector and a large language model to generate high-quality narrations with detailed descriptions of hand-object dynamics. To learn these fine-grained dynamics, we propose EgoVideo, a model with a new lightweight motion adapter to capture fine-grained hand-object motion information. Through our co-training strategy, EgoVideo effectively and efficiently leverages the fine-grained hand-object dynamics in the HOD data. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple egocentric downstream tasks, including improvements of 6.3% in EK-100 multi-instance retrieval, 5.7% in EK-100 classification, and 16.3% in EGTEA classification in zero-shot settings. Furthermore, our model exhibits robust generalization capabilities in hand-object interaction and robot manipulation tasks. Code and data are available at https://github.com/OpenRobotLab/EgoHOD/.
MMRC: A Large-Scale Benchmark for Understanding Multimodal Large Language Model in Real-World Conversation
Feb 17, 2025Recent multimodal large language models (MLLMs) have demonstrated significant potential in open-ended conversation, generating more accurate and personalized responses. However, their abilities to memorize, recall, and reason in sustained interactions within real-world scenarios remain underexplored. This paper introduces MMRC, a Multi-Modal Real-world Conversation benchmark for evaluating six core open-ended abilities of MLLMs: information extraction, multi-turn reasoning, information update, image management, memory recall, and answer refusal. With data collected from real-world scenarios, MMRC comprises 5,120 conversations and 28,720 corresponding manually labeled questions, posing a significant challenge to existing MLLMs. Evaluations on 20 MLLMs in MMRC indicate an accuracy drop during open-ended interactions. We identify four common failure patterns: long-term memory degradation, inadequacies in updating factual knowledge, accumulated assumption of error propagation, and reluctance to say no. To mitigate these issues, we propose a simple yet effective NOTE-TAKING strategy, which can record key information from the conversation and remind the model during its responses, enhancing conversational capabilities. Experiments across six MLLMs demonstrate significant performance improvements.
LimSim Series: An Autonomous Driving Simulation Platform for Validation and Enhancement
Feb 13, 2025



Closed-loop simulation environments play a crucial role in the validation and enhancement of autonomous driving systems (ADS). However, certain challenges warrant significant attention, including balancing simulation accuracy with duration, reconciling functionality with practicality, and establishing comprehensive evaluation mechanisms. This paper addresses these challenges by introducing the LimSim Series, a comprehensive simulation platform designed to support the rapid deployment and efficient iteration of ADS. The LimSim Series integrates multi-type information from road networks, employs human-like decision-making and planning algorithms for background vehicles, and introduces the concept of the Area of Interest (AoI) to optimize computational resources. The platform offers a variety of baseline algorithms and user-friendly interfaces, facilitating flexible validation of multiple technical pipelines. Additionally, the LimSim Series incorporates multi-dimensional evaluation metrics, delivering thorough insights into system performance, thus enabling researchers to promptly identify issues for further improvements. Experiments demonstrate that the LimSim Series is compatible with modular, end-to-end, and VLM-based knowledge-driven systems. It can assist in the iteration and updating of ADS by evaluating performance across various scenarios. The code of the LimSim Series is released at: https://github.com/PJLab-ADG/LimSim.
Lumina-Video: Efficient and Flexible Video Generation with Multi-scale Next-DiT
Feb 10, 2025Recent advancements have established Diffusion Transformers (DiTs) as a dominant framework in generative modeling. Building on this success, Lumina-Next achieves exceptional performance in the generation of photorealistic images with Next-DiT. However, its potential for video generation remains largely untapped, with significant challenges in modeling the spatiotemporal complexity inherent to video data. To address this, we introduce Lumina-Video, a framework that leverages the strengths of Next-DiT while introducing tailored solutions for video synthesis. Lumina-Video incorporates a Multi-scale Next-DiT architecture, which jointly learns multiple patchifications to enhance both efficiency and flexibility. By incorporating the motion score as an explicit condition, Lumina-Video also enables direct control of generated videos' dynamic degree. Combined with a progressive training scheme with increasingly higher resolution and FPS, and a multi-source training scheme with mixed natural and synthetic data, Lumina-Video achieves remarkable aesthetic quality and motion smoothness at high training and inference efficiency. We additionally propose Lumina-V2A, a video-to-audio model based on Next-DiT, to create synchronized sounds for generated videos. Codes are released at https://www.github.com/Alpha-VLLM/Lumina-Video.
Pre-trained Model Guided Mixture Knowledge Distillation for Adversarial Federated Learning
Jan 25, 2025



This paper aims to improve the robustness of a small global model while maintaining clean accuracy under adversarial attacks and non-IID challenges in federated learning. By leveraging the concise knowledge embedded in the class probabilities from a pre-trained model for both clean and adversarial image classification, we propose a Pre-trained Model-guided Adversarial Federated Learning (PM-AFL) training paradigm. This paradigm integrates vanilla mixture and adversarial mixture knowledge distillation to effectively balance accuracy and robustness while promoting local models to learn from diverse data. Specifically, for clean accuracy, we adopt a dual distillation strategy where the class probabilities of randomly paired images and their blended versions are aligned between the teacher model and the local models. For adversarial robustness, we use a similar distillation approach but replace clean samples on the local side with adversarial examples. Moreover, considering the bias between local and global models, we also incorporate a consistency regularization term to ensure that local adversarial predictions stay aligned with their corresponding global clean ones. These strategies collectively enable local models to absorb diverse knowledge from the teacher model while maintaining close alignment with the global model, thereby mitigating overfitting to local optima and enhancing the generalization of the global model. Experiments demonstrate that the PM-AFL-based paradigm outperforms other methods that integrate defense strategies by a notable margin.
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
Jan 24, 2025



This paper introduces the open-source dataset WanJuanSiLu, designed to provide high-quality training corpora for low-resource languages, thereby advancing the research and development of multilingual models. To achieve this, we have developed a systematic data processing framework tailored for low-resource languages. This framework encompasses key stages such as data extraction, corpus cleaning, content deduplication, security filtering, quality evaluation, and theme classification. Through the implementation of this framework, we have significantly improved both the quality and security of the dataset, while maintaining its linguistic diversity. As of now, data for all five languages have been fully open-sourced. The dataset can be accessed at https://opendatalab.com/applyMultilingualCorpus, and GitHub repository is available at https://github.com/opendatalab/WanJuan3.0
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Jan 21, 2025


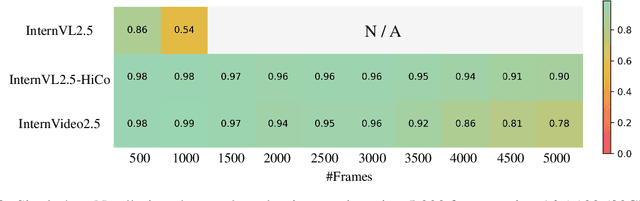
This paper aims to improve the performance of video multimodal large language models (MLLM) via long and rich context (LRC) modeling. As a result, we develop a new version of InternVideo2.5 with a focus on enhancing the original MLLMs' ability to perceive fine-grained details and capture long-form temporal structure in videos. Specifically, our approach incorporates dense vision task annotations into MLLMs using direct preference optimization and develops compact spatiotemporal representations through adaptive hierarchical token compression. Experimental results demonstrate this unique design of LRC greatly improves the results of video MLLM in mainstream video understanding benchmarks (short & long), enabling the MLLM to memorize significantly longer video inputs (at least 6x longer than the original), and master specialized vision capabilities like object tracking and segmentation. Our work highlights the importance of multimodal context richness (length and fineness) in empowering MLLM's innate abilites (focus and memory), providing new insights for future research on video MLLM. Code and models are available at https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5