 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYao Lu
Joint Optimization of Base Station Clustering and Service Caching in User-Centric MEC
Feb 21, 2023
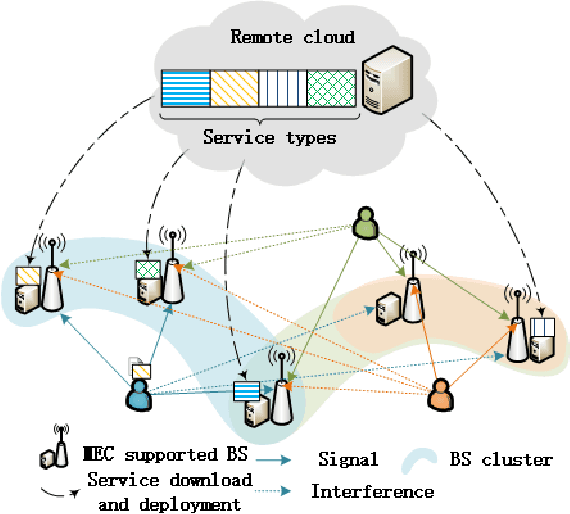
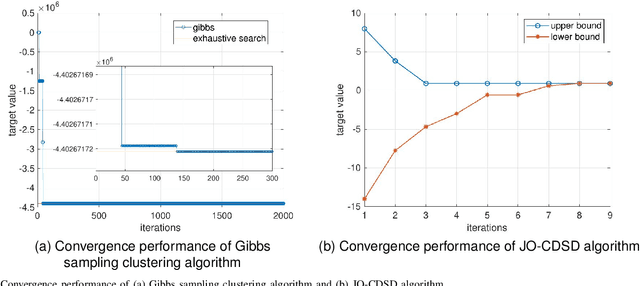
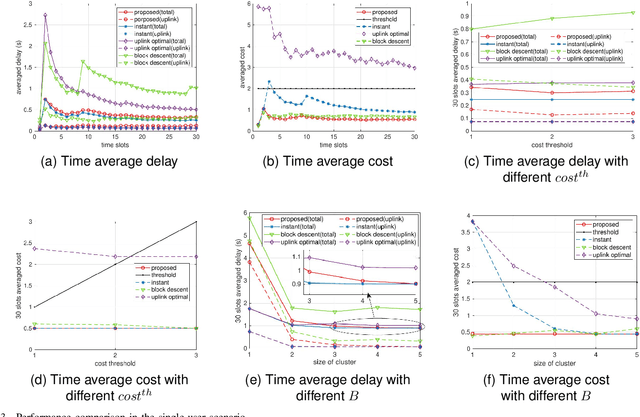
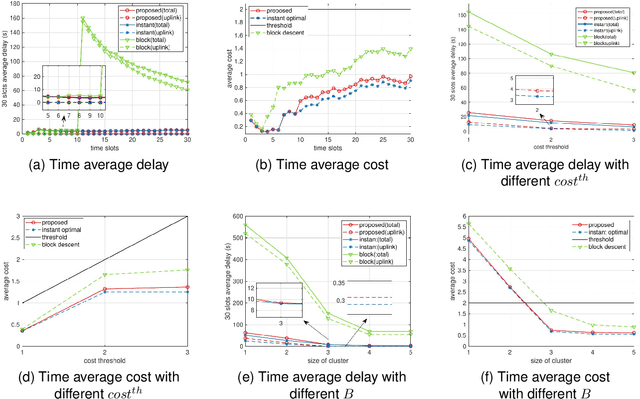
Edge service caching can effectively reduce the delay or bandwidth overhead for acquiring and initializing applications. To address single-base station (BS) transmission limitation and serious edge effect in traditional cellular-based edge service caching networks, in this paper, we proposed a novel user-centric edge service caching framework where each user is jointly provided with edge caching and wireless transmission services by a specific BS cluster instead of a single BS. To minimize the long-term average delay under the constraint of the caching cost, a mixed integer non-linear programming (MINLP) problem is formulated by jointly optimizing the BS clustering and service caching decisions. To tackle the problem, we propose JO-CDSD, an efficiently joint optimization algorithm based on Lyapunov optimization and generalized benders decomposition (GBD). In particular, the long-term optimization problem can be transformed into a primal problem and a master problem in each time slot that is much simpler to solve. The near-optimal clustering and caching strategy can be obtained through solving the primal and master problem alternately. Extensive simulations show that the proposed joint optimization algorithm outperforms other algorithms and can effectively reduce the long-term delay by at most $93.75% and caching cost by at most $53.12%.
RT-1: Robotics Transformer for Real-World Control at Scale
Dec 13, 2022



By transferring knowledge from large, diverse, task-agnostic datasets, modern machine learning models can solve specific downstream tasks either zero-shot or with small task-specific datasets to a high level of performance. While this capability has been demonstrated in other fields such as computer vision, natural language processing or speech recognition, it remains to be shown in robotics, where the generalization capabilities of the models are particularly critical due to the difficulty of collecting real-world robotic data. We argue that one of the keys to the success of such general robotic models lies with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the diverse, robotic data. In this paper, we present a model class, dubbed Robotics Transformer, that exhibits promising scalable model properties. We verify our conclusions in a study of different model classes and their ability to generalize as a function of the data size, model size, and data diversity based on a large-scale data collection on real robots performing real-world tasks. The project's website and videos can be found at robotics-transformer.github.io
Token Turing Machines
Nov 16, 2022
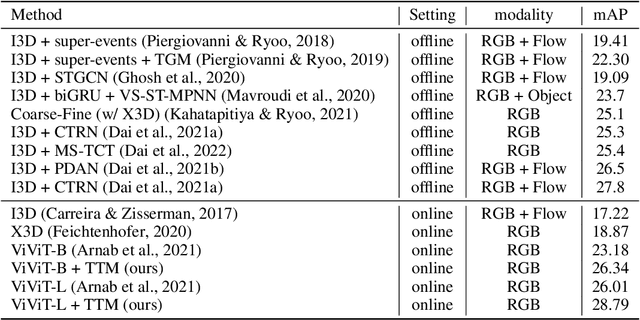
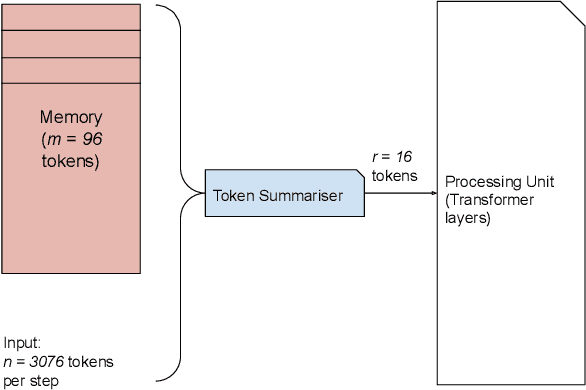
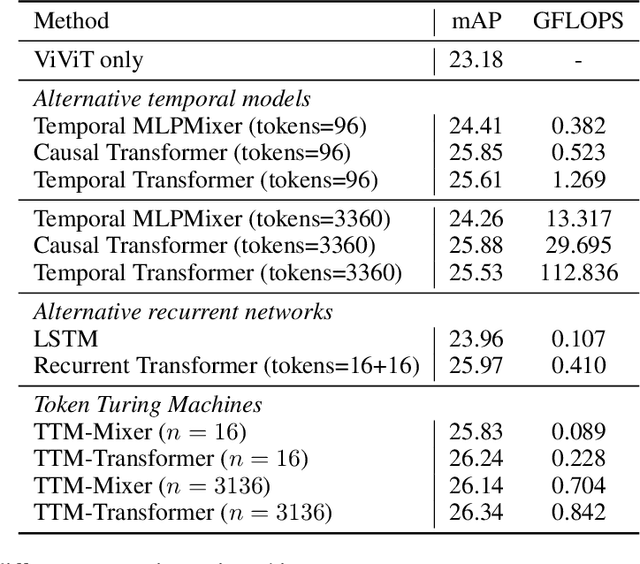
We propose Token Turing Machines (TTM), a sequential, autoregressive Transformer model with memory for real-world sequential visual understanding. Our model is inspired by the seminal Neural Turing Machine, and has an external memory consisting of a set of tokens which summarise the previous history (i.e., frames). This memory is efficiently addressed, read and written using a Transformer as the processing unit/controller at each step. The model's memory module ensures that a new observation will only be processed with the contents of the memory (and not the entire history), meaning that it can efficiently process long sequences with a bounded computational cost at each step. We show that TTM outperforms other alternatives, such as other Transformer models designed for long sequences and recurrent neural networks, on two real-world sequential visual understanding tasks: online temporal activity detection from videos and vision-based robot action policy learning.
Egocentric Hand-object Interaction Detection
Nov 16, 2022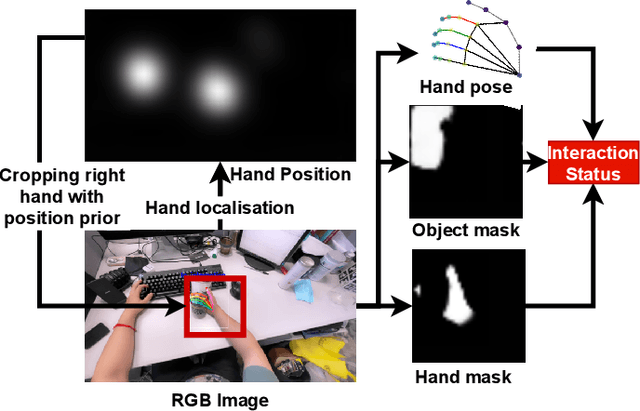


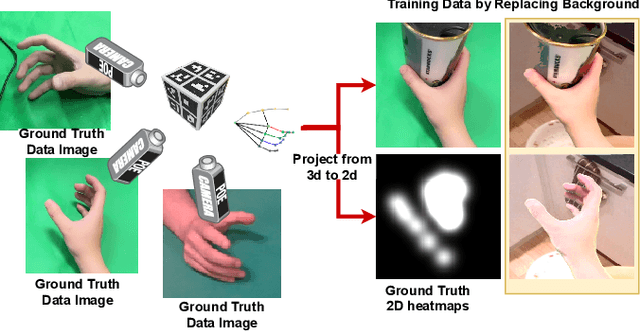
In this paper, we propose a method to jointly determine the status of hand-object interaction. This is crucial for egocentric human activity understanding and interaction. From a computer vision perspective, we believe that determining whether a hand is interacting with an object depends on whether there is an interactive hand pose and whether the hand is touching the object. Thus, we extract the hand pose, hand-object masks to jointly determine the interaction status. In order to solve the problem of hand pose estimation due to in-hand object occlusion, we use a multi-cam system to capture hand pose data from multiple perspectives. We evaluate and compare our method with the most recent work from Shan et al. \cite{Shan20} on selected images from EPIC-KITCHENS \cite{damen2018scaling} dataset and achieve $89\%$ accuracy on HOI (hand-object interaction) detection which is comparative to Shan's ($92\%$). However, for real-time performance, our method can run over $\textbf{30}$ FPS which is much more efficient than Shan's ($\textbf{1}\sim\textbf{2}$ FPS). A demo can be found from https://www.youtube.com/watch?v=XVj3zBuynmQ
Robotic Table Wiping via Reinforcement Learning and Whole-body Trajectory Optimization
Oct 19, 2022
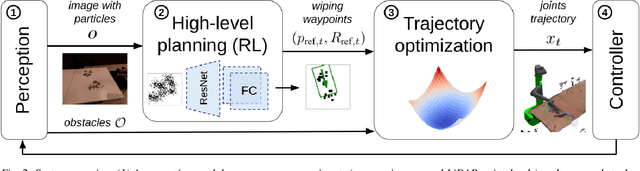

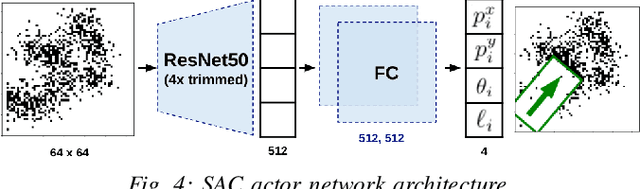
We propose a framework to enable multipurpose assistive mobile robots to autonomously wipe tables to clean spills and crumbs. This problem is challenging, as it requires planning wiping actions while reasoning over uncertain latent dynamics of crumbs and spills captured via high-dimensional visual observations. Simultaneously, we must guarantee constraints satisfaction to enable safe deployment in unstructured cluttered environments. To tackle this problem, we first propose a stochastic differential equation to model crumbs and spill dynamics and absorption with a robot wiper. Using this model, we train a vision-based policy for planning wiping actions in simulation using reinforcement learning (RL). To enable zero-shot sim-to-real deployment, we dovetail the RL policy with a whole-body trajectory optimization framework to compute base and arm joint trajectories that execute the desired wiping motions while guaranteeing constraints satisfaction. We extensively validate our approach in simulation and on hardware. Video: https://youtu.be/inORKP4F3EI
PI-QT-Opt: Predictive Information Improves Multi-Task Robotic Reinforcement Learning at Scale
Oct 15, 2022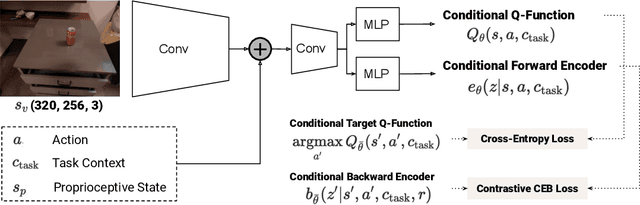



The predictive information, the mutual information between the past and future, has been shown to be a useful representation learning auxiliary loss for training reinforcement learning agents, as the ability to model what will happen next is critical to success on many control tasks. While existing studies are largely restricted to training specialist agents on single-task settings in simulation, in this work, we study modeling the predictive information for robotic agents and its importance for general-purpose agents that are trained to master a large repertoire of diverse skills from large amounts of data. Specifically, we introduce Predictive Information QT-Opt (PI-QT-Opt), a QT-Opt agent augmented with an auxiliary loss that learns representations of the predictive information to solve up to 297 vision-based robot manipulation tasks in simulation and the real world with a single set of parameters. We demonstrate that modeling the predictive information significantly improves success rates on the training tasks and leads to better zero-shot transfer to unseen novel tasks. Finally, we evaluate PI-QT-Opt on real robots, achieving substantial and consistent improvement over QT-Opt in multiple experimental settings of varying environments, skills, and multi-task configurations.
Low Error-Rate Approximate Multiplier Design for DNNs with Hardware-Driven Co-Optimization
Oct 08, 2022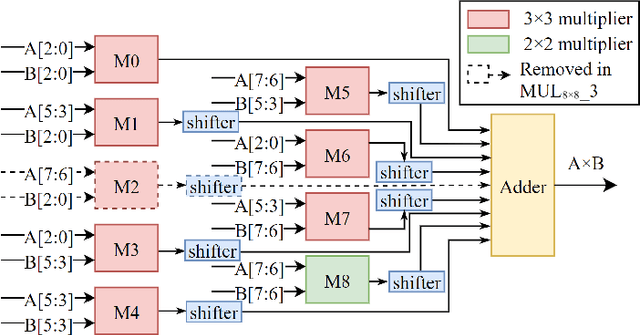
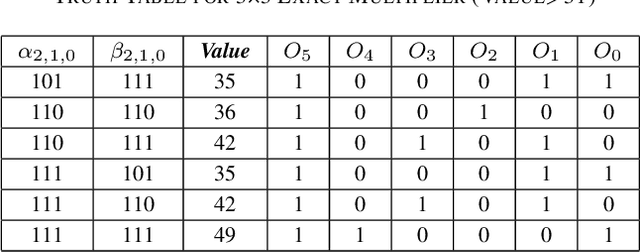
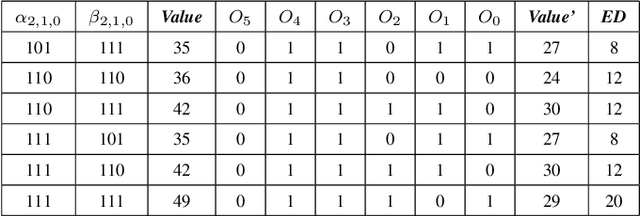
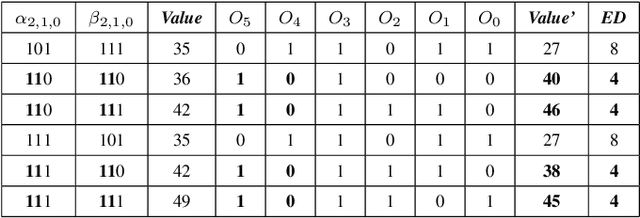
In this paper, two approximate 3*3 multipliers are proposed and the synthesis results of the ASAP-7nm process library justify that they can reduce the area by 31.38% and 36.17%, and the power consumption by 36.73% and 35.66% compared with the exact multiplier, respectively. They can be aggregated with a 2*2 multiplier to produce an 8*8 multiplier with low error rate based on the distribution of DNN weights. We propose a hardware-driven software co-optimization method to improve the DNN accuracy by retraining. Based on the proposed two approximate 3-bit multipliers, three approximate 8-bit multipliers with low error-rate are designed for DNNs. Compared with the exact 8-bit unsigned multiplier, our design can achieve a significant advantage over other approximate multipliers on the public dataset.
Alexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance
Sep 13, 2022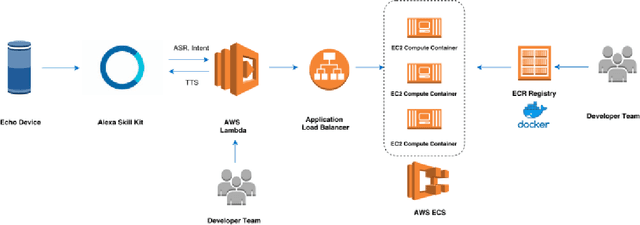
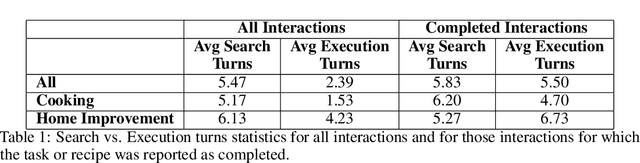
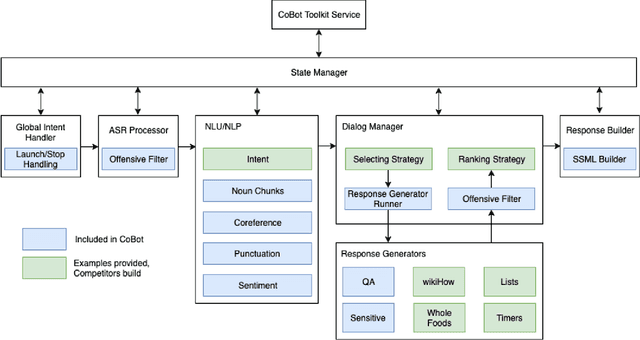

Since its inception in 2016, the Alexa Prize program has enabled hundreds of university students to explore and compete to develop conversational agents through the SocialBot Grand Challenge. The goal of the challenge is to build agents capable of conversing coherently and engagingly with humans on popular topics for 20 minutes, while achieving an average rating of at least 4.0/5.0. However, as conversational agents attempt to assist users with increasingly complex tasks, new conversational AI techniques and evaluation platforms are needed. The Alexa Prize TaskBot challenge, established in 2021, builds on the success of the SocialBot challenge by introducing the requirements of interactively assisting humans with real-world Cooking and Do-It-Yourself tasks, while making use of both voice and visual modalities. This challenge requires the TaskBots to identify and understand the user's need, identify and integrate task and domain knowledge into the interaction, and develop new ways of engaging the user without distracting them from the task at hand, among other challenges. This paper provides an overview of the TaskBot challenge, describes the infrastructure support provided to the teams with the CoBot Toolkit, and summarizes the approaches the participating teams took to overcome the research challenges. Finally, it analyzes the performance of the competing TaskBots during the first year of the competition.
The least-used key selection method for information retrieval in large-scale Cloud-based service repositories
Aug 16, 2022



As the number of devices connected to the Internet of Things (IoT) increases significantly, it leads to an exponential growth in the number of services that need to be processed and stored in the large-scale Cloud-based service repositories. An efficient service indexing model is critical for service retrieval and management of large-scale Cloud-based service repositories. The multilevel index model is the state-of-art service indexing model in recent years to improve service discovery and combination. This paper aims to optimize the model to consider the impact of unequal appearing probability of service retrieval request parameters and service input parameters on service retrieval and service addition operations. The least-used key selection method has been proposed to narrow the search scope of service retrieval and reduce its time. The experimental results show that the proposed least-used key selection method improves the service retrieval efficiency significantly compared with the designated key selection method in the case of the unequal appearing probability of parameters in service retrieval requests under three indexing models.
Serving and Optimizing Machine Learning Workflows on Heterogeneous Infrastructures
May 10, 2022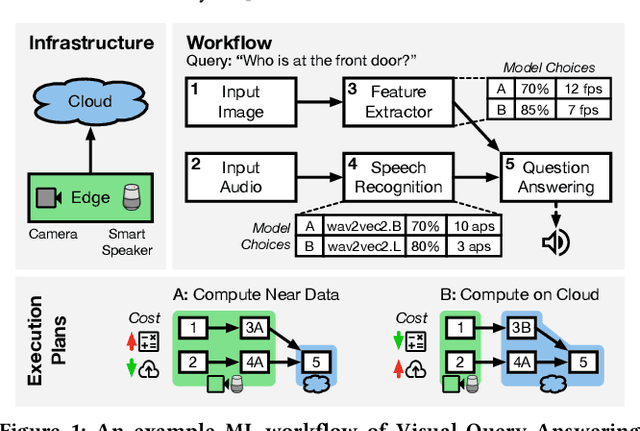
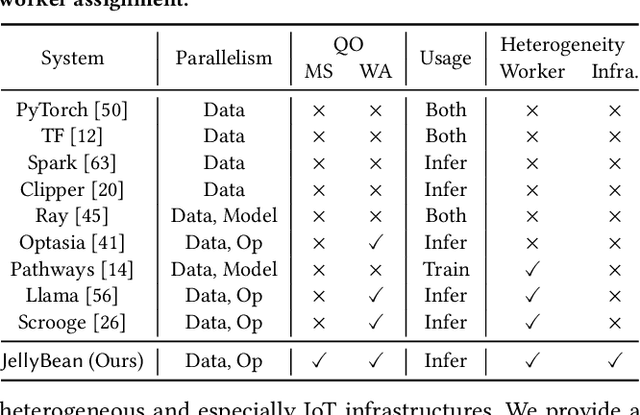
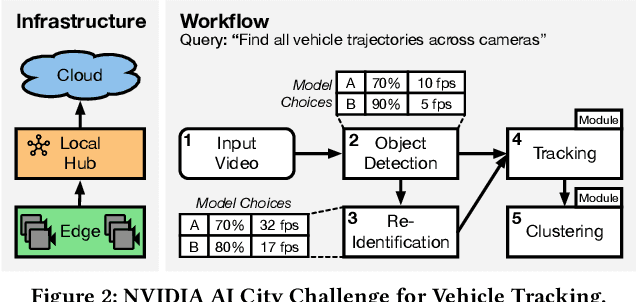

With the advent of ubiquitous deployment of smart devices and the Internet of Things, data sources for machine learning inference have increasingly moved to the edge of the network. Existing machine learning inference platforms typically assume a homogeneous infrastructure and do not take into account the more complex and tiered computing infrastructure that includes edge devices, local hubs, edge datacenters, and cloud datacenters. On the other hand, recent machine learning efforts have provided viable solutions for model compression, pruning and quantization for heterogeneous environments; for a machine learning model, now we may easily find or even generate a series of models with different tradeoffs between accuracy and efficiency. We design and implement JellyBean, a framework for serving and optimizing machine learning inference workflows on heterogeneous infrastructures. Given service-level objectives (e.g., throughput, accuracy), JellyBean automatically selects the most cost-efficient models that met the accuracy target and decides how to deploy them across different tiers of infrastructures. Evaluations show that JellyBean reduces the total serving cost of visual question answering by up to 58%, and vehicle tracking from the NVIDIA AI City Challenge by up to 36% compared with state-of-the-art model selection and worker assignment solutions. JellyBean also outperforms prior ML serving systems (e.g., Spark on the cloud) up to 5x in serving costs.