 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization
Feb 03, 2026Despite rapid progress in autoregressive video diffusion, an emerging system algorithm bottleneck limits both deployability and generation capability: KV cache memory. In autoregressive video generation models, the KV cache grows with generation history and quickly dominates GPU memory, often exceeding 30 GB, preventing deployment on widely available hardware. More critically, constrained KV cache budgets restrict the effective working memory, directly degrading long horizon consistency in identity, layout, and motion. To address this challenge, we present Quant VideoGen (QVG), a training free KV cache quantization framework for autoregressive video diffusion models. QVG leverages video spatiotemporal redundancy through Semantic Aware Smoothing, producing low magnitude, quantization friendly residuals. It further introduces Progressive Residual Quantization, a coarse to fine multi stage scheme that reduces quantization error while enabling a smooth quality memory trade off. Across LongCat Video, HY WorldPlay, and Self Forcing benchmarks, QVG establishes a new Pareto frontier between quality and memory efficiency, reducing KV cache memory by up to 7.0 times with less than 4% end to end latency overhead while consistently outperforming existing baselines in generation quality.
VNU-Bench: A Benchmarking Dataset for Multi-Source Multimodal News Video Understanding
Jan 06, 2026News videos are carefully edited multimodal narratives that combine narration, visuals, and external quotations into coherent storylines. In recent years, there have been significant advances in evaluating multimodal large language models (MLLMs) for news video understanding. However, existing benchmarks largely focus on single-source, intra-video reasoning, where each report is processed in isolation. In contrast, real-world news consumption is inherently multi-sourced: the same event is reported by different outlets with complementary details, distinct narrative choices, and sometimes conflicting claims that unfold over time. Robust news understanding, therefore, requires models to compare perspectives from different sources, align multimodal evidence across sources, and synthesize multi-source information. To fill this gap, we introduce VNU-Bench, the first benchmark for multi-source, cross-video understanding in the news domain. We design a set of new question types that are unique in testing models' ability of understanding multi-source multimodal news from a variety of different angles. We design a novel hybrid human-model QA generation process that addresses the issues of scalability and quality control in building a large dataset for cross-source news understanding. The dataset comprises 429 news groups, 1,405 videos, and 2,501 high-quality questions. Comprehensive evaluation of both closed- and open-source multimodal models shows that VNU-Bench poses substantial challenges for current MLLMs.
Pretraining Frame Preservation in Autoregressive Video Memory Compression
Dec 29, 2025We present PFP, a neural network structure to compress long videos into short contexts, with an explicit pretraining objective to preserve the high-frequency details of single frames at arbitrary temporal positions. The baseline model can compress a 20-second video into a context at about 5k length, where random frames can be retrieved with perceptually preserved appearances. Such pretrained models can be directly fine-tuned as memory encoders for autoregressive video models, enabling long history memory with low context cost and relatively low fidelity loss. We evaluate the framework with ablative settings and discuss the trade-offs of possible neural architecture designs.
StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
Nov 10, 2025



Generative models are reshaping the live-streaming industry by redefining how content is created, styled, and delivered. Previous image-based streaming diffusion models have powered efficient and creative live streaming products but have hit limits on temporal consistency due to the foundation of image-based designs. Recent advances in video diffusion have markedly improved temporal consistency and sampling efficiency for offline generation. However, offline generation systems primarily optimize throughput by batching large workloads. In contrast, live online streaming operates under strict service-level objectives (SLOs): time-to-first-frame must be minimal, and every frame must meet a per-frame deadline with low jitter. Besides, scalable multi-GPU serving for real-time streams remains largely unresolved so far. To address this, we present StreamDiffusionV2, a training-free pipeline for interactive live streaming with video diffusion models. StreamDiffusionV2 integrates an SLO-aware batching scheduler and a block scheduler, together with a sink-token--guided rolling KV cache, a motion-aware noise controller, and other system-level optimizations. Moreover, we introduce a scalable pipeline orchestration that parallelizes the diffusion process across denoising steps and network layers, achieving near-linear FPS scaling without violating latency guarantees. The system scales seamlessly across heterogeneous GPU environments and supports flexible denoising steps (e.g., 1--4), enabling both ultra-low-latency and higher-quality modes. Without TensorRT or quantization, StreamDiffusionV2 renders the first frame within 0.5s and attains 58.28 FPS with a 14B-parameter model and 64.52 FPS with a 1.3B-parameter model on four H100 GPUs, making state-of-the-art generative live streaming practical and accessible--from individual creators to enterprise-scale platforms.
LongLive: Real-time Interactive Long Video Generation
Sep 26, 2025We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
Radial Attention: $O(n\log n)$ Sparse Attention with Energy Decay for Long Video Generation
Jun 24, 2025Recent advances in diffusion models have enabled high-quality video generation, but the additional temporal dimension significantly increases computational costs, making training and inference on long videos prohibitively expensive. In this paper, we identify a phenomenon we term Spatiotemporal Energy Decay in video diffusion models: post-softmax attention scores diminish as spatial and temporal distance between tokens increase, akin to the physical decay of signal or waves over space and time in nature. Motivated by this, we propose Radial Attention, a scalable sparse attention mechanism with $O(n \log n)$ complexity that translates energy decay into exponentially decaying compute density, which is significantly more efficient than standard $O(n^2)$ dense attention and more expressive than linear attention. Specifically, Radial Attention employs a simple, static attention mask where each token attends to spatially nearby tokens, with the attention window size shrinking with temporal distance. Moreover, it allows pre-trained video diffusion models to extend their generation length with efficient LoRA-based fine-tuning. Extensive experiments show that Radial Attention maintains video quality across Wan2.1-14B, HunyuanVideo, and Mochi 1, achieving up to a 1.9$\times$ speedup over the original dense attention. With minimal tuning, it enables video generation up to 4$\times$ longer while reducing training costs by up to 4.4$\times$ compared to direct fine-tuning and accelerating inference by up to 3.7$\times$ compared to dense attention inference.
Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation
May 24, 2025Diffusion Transformers (DiTs) are essential for video generation but suffer from significant latency due to the quadratic complexity of attention. By computing only critical tokens, sparse attention reduces computational costs and offers a promising acceleration approach. However, we identify that existing methods fail to approach optimal generation quality under the same computation budget for two reasons: (1) Inaccurate critical token identification: current methods cluster tokens based on position rather than semantics, leading to imprecise aggregated representations. (2) Excessive computation waste: critical tokens are scattered among non-critical ones, leading to wasted computation on GPUs, which are optimized for processing contiguous tokens. In this paper, we propose SVG2, a training-free framework that maximizes identification accuracy and minimizes computation waste, achieving a Pareto frontier trade-off between generation quality and efficiency. The core of SVG2 is semantic-aware permutation, which clusters and reorders tokens based on semantic similarity using k-means. This approach ensures both a precise cluster representation, improving identification accuracy, and a densified layout of critical tokens, enabling efficient computation without padding. Additionally, SVG2 integrates top-p dynamic budget control and customized kernel implementations, achieving up to 2.30x and 1.89x speedup while maintaining a PSNR of up to 30 and 26 on HunyuanVideo and Wan 2.1, respectively.
Advances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025


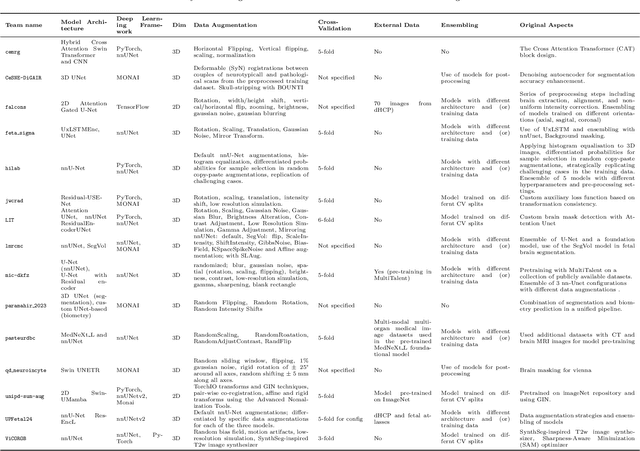
Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
Token-Efficient Long Video Understanding for Multimodal LLMs
Mar 06, 2025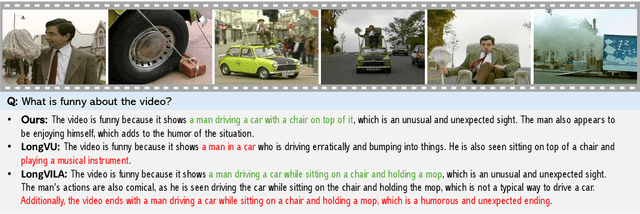
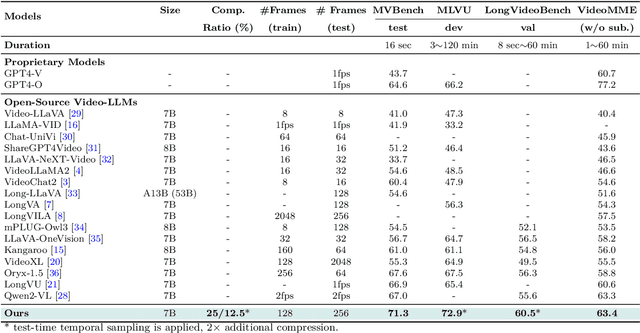
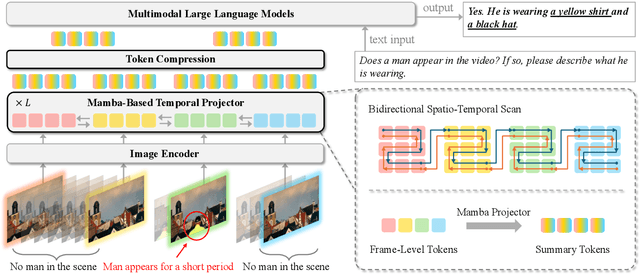
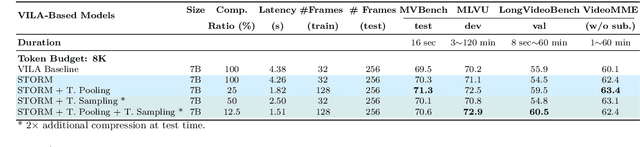
Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (\textbf{S}patiotemporal \textbf{TO}ken \textbf{R}eduction for \textbf{M}ultimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5\% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
Enhanced Feature-based Image Stitching for Endoscopic Videos in Pediatric Eosinophilic Esophagitis
Feb 06, 2025



Video endoscopy represents a major advance in the investigation of gastrointestinal diseases. Reviewing endoscopy videos often involves frequent adjustments and reorientations to piece together a complete view, which can be both time-consuming and prone to errors. Image stitching techniques address this issue by providing a continuous and complete visualization of the examined area. However, endoscopic images, particularly those of the esophagus, present unique challenges. The smooth surface, lack of distinct feature points, and non-horizontal orientation complicate the stitching process, rendering traditional feature-based methods often ineffective for these types of images. In this paper, we propose a novel preprocessing pipeline designed to enhance endoscopic image stitching through advanced computational techniques. Our approach converts endoscopic video data into continuous 2D images by following four key steps: (1) keyframe selection, (2) image rotation adjustment to correct distortions, (3) surface unwrapping using polar coordinate transformation to generate a flat image, and (4) feature point matching enhanced by Adaptive Histogram Equalization for improved feature detection. We evaluate stitching quality through the assessment of valid feature point match pairs. Experiments conducted on 20 pediatric endoscopy videos demonstrate that our method significantly improves image alignment and stitching quality compared to traditional techniques, laying a robust foundation for more effective panoramic image creation.