 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldModelBench: Judging Video Generation Models As World Models
Feb 28, 2025



Video generation models have rapidly progressed, positioning themselves as video world models capable of supporting decision-making applications like robotics and autonomous driving. However, current benchmarks fail to rigorously evaluate these claims, focusing only on general video quality, ignoring important factors to world models such as physics adherence. To bridge this gap, we propose WorldModelBench, a benchmark designed to evaluate the world modeling capabilities of video generation models in application-driven domains. WorldModelBench offers two key advantages: (1) Against to nuanced world modeling violations: By incorporating instruction-following and physics-adherence dimensions, WorldModelBench detects subtle violations, such as irregular changes in object size that breach the mass conservation law - issues overlooked by prior benchmarks. (2) Aligned with large-scale human preferences: We crowd-source 67K human labels to accurately measure 14 frontier models. Using our high-quality human labels, we further fine-tune an accurate judger to automate the evaluation procedure, achieving 8.6% higher average accuracy in predicting world modeling violations than GPT-4o with 2B parameters. In addition, we demonstrate that training to align human annotations by maximizing the rewards from the judger noticeably improve the world modeling capability. The website is available at https://worldmodelbench-team.github.io.
Autellix: An Efficient Serving Engine for LLM Agents as General Programs
Feb 19, 2025Large language model (LLM) applications are evolving beyond simple chatbots into dynamic, general-purpose agentic programs, which scale LLM calls and output tokens to help AI agents reason, explore, and solve complex tasks. However, existing LLM serving systems ignore dependencies between programs and calls, missing significant opportunities for optimization. Our analysis reveals that programs submitted to LLM serving engines experience long cumulative wait times, primarily due to head-of-line blocking at both the individual LLM request and the program. To address this, we introduce Autellix, an LLM serving system that treats programs as first-class citizens to minimize their end-to-end latencies. Autellix intercepts LLM calls submitted by programs, enriching schedulers with program-level context. We propose two scheduling algorithms-for single-threaded and distributed programs-that preempt and prioritize LLM calls based on their programs' previously completed calls. Our evaluation demonstrates that across diverse LLMs and agentic workloads, Autellix improves throughput of programs by 4-15x at the same latency compared to state-of-the-art systems, such as vLLM.
SimpleStrat: Diversifying Language Model Generation with Stratification
Oct 11, 2024



Generating diverse responses from large language models (LLMs) is crucial for applications such as planning/search and synthetic data generation, where diversity provides distinct answers across generations. Prior approaches rely on increasing temperature to increase diversity. However, contrary to popular belief, we show not only does this approach produce lower quality individual generations as temperature increases, but it depends on model's next-token probabilities being similar to the true distribution of answers. We propose \method{}, an alternative approach that uses the language model itself to partition the space into strata. At inference, a random stratum is selected and a sample drawn from within the strata. To measure diversity, we introduce CoverageQA, a dataset of underspecified questions with multiple equally plausible answers, and assess diversity by measuring KL Divergence between the output distribution and uniform distribution over valid ground truth answers. As computing probability per response/solution for proprietary models is infeasible, we measure recall on ground truth solutions. Our evaluation show using SimpleStrat achieves higher recall by 0.05 compared to GPT-4o and 0.36 average reduction in KL Divergence compared to Llama 3.
Synthetic Programming Elicitation and Repair for Text-to-Code in Very Low-Resource Programming Languages
Jun 05, 2024



Recent advances in large language models (LLMs) for code applications have demonstrated remarkable zero-shot fluency and instruction following on challenging code related tasks ranging from test case generation to self-repair. Unsurprisingly, however, models struggle to compose syntactically valid programs in programming languages unrepresented in pre-training, referred to as very low-resource Programming Languages (VLPLs). VLPLs appear in crucial settings including domain-specific languages for internal to tools and tool-chains and legacy languages. Inspired by an HCI technique called natural program elicitation, we propose designing an intermediate language that LLMs ``naturally'' know how to use and which can be automatically compiled to the target VLPL. Specifically, we introduce synthetic programming elicitation and compilation (SPEAK), an approach that enables LLMs to generate syntactically valid code even for VLPLs. We empirically evaluate the performance of SPEAK in a case study and find that, compared to existing retrieval and fine-tuning baselines, SPEAK produces syntactically correct programs more frequently without sacrificing semantic correctness.
Stylus: Automatic Adapter Selection for Diffusion Models
Apr 29, 2024



Beyond scaling base models with more data or parameters, fine-tuned adapters provide an alternative way to generate high fidelity, custom images at reduced costs. As such, adapters have been widely adopted by open-source communities, accumulating a database of over 100K adapters-most of which are highly customized with insufficient descriptions. This paper explores the problem of matching the prompt to a set of relevant adapters, built on recent work that highlight the performance gains of composing adapters. We introduce Stylus, which efficiently selects and automatically composes task-specific adapters based on a prompt's keywords. Stylus outlines a three-stage approach that first summarizes adapters with improved descriptions and embeddings, retrieves relevant adapters, and then further assembles adapters based on prompts' keywords by checking how well they fit the prompt. To evaluate Stylus, we developed StylusDocs, a curated dataset featuring 75K adapters with pre-computed adapter embeddings. In our evaluation on popular Stable Diffusion checkpoints, Stylus achieves greater CLIP-FID Pareto efficiency and is twice as preferred, with humans and multimodal models as evaluators, over the base model. See stylus-diffusion.github.io for more.
The Wisdom of Hindsight Makes Language Models Better Instruction Followers
Feb 10, 2023



Reinforcement learning has seen wide success in finetuning large language models to better align with instructions via human feedback. The so-called algorithm, Reinforcement Learning with Human Feedback (RLHF) demonstrates impressive performance on the GPT series models. However, the underlying Reinforcement Learning (RL) algorithm is complex and requires an additional training pipeline for reward and value networks. In this paper, we consider an alternative approach: converting feedback to instruction by relabeling the original one and training the model for better alignment in a supervised manner. Such an algorithm doesn't require any additional parameters except for the original language model and maximally reuses the pretraining pipeline. To achieve this, we formulate instruction alignment problem for language models as a goal-reaching problem in decision making. We propose Hindsight Instruction Relabeling (HIR), a novel algorithm for aligning language models with instructions. The resulting two-stage algorithm shed light to a family of reward-free approaches that utilize the hindsightly relabeled instructions based on feedback. We evaluate the performance of HIR extensively on 12 challenging BigBench reasoning tasks and show that HIR outperforms the baseline algorithms and is comparable to or even surpasses supervised finetuning.
Context-Aware Streaming Perception in Dynamic Environments
Aug 16, 2022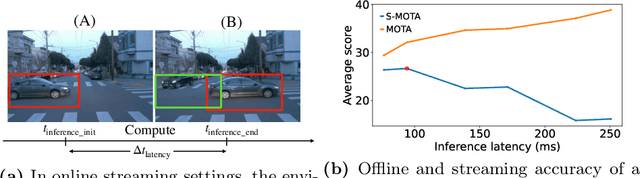
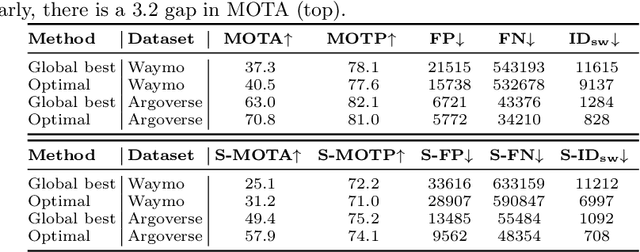
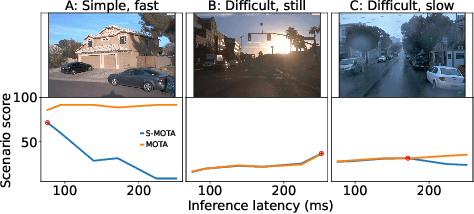
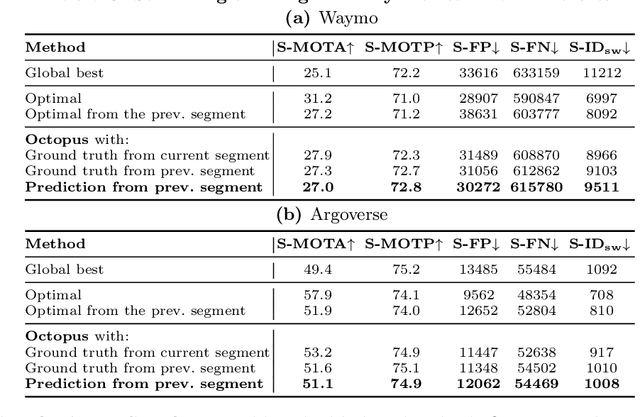
Efficient vision works maximize accuracy under a latency budget. These works evaluate accuracy offline, one image at a time. However, real-time vision applications like autonomous driving operate in streaming settings, where ground truth changes between inference start and finish. This results in a significant accuracy drop. Therefore, a recent work proposed to maximize accuracy in streaming settings on average. In this paper, we propose to maximize streaming accuracy for every environment context. We posit that scenario difficulty influences the initial (offline) accuracy difference, while obstacle displacement in the scene affects the subsequent accuracy degradation. Our method, Octopus, uses these scenario properties to select configurations that maximize streaming accuracy at test time. Our method improves tracking performance (S-MOTA) by 7.4% over the conventional static approach. Further, performance improvement using our method comes in addition to, and not instead of, advances in offline accuracy.
Addressing the IEEE AV Test Challenge with Scenic and VerifAI
Aug 20, 2021

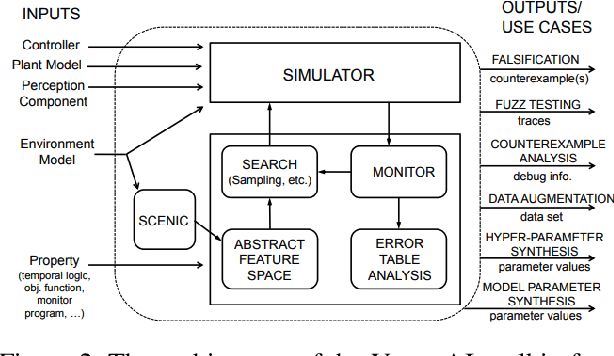
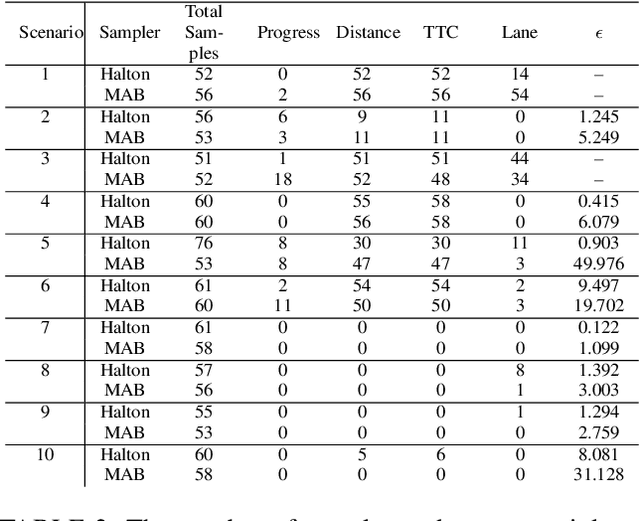
This paper summarizes our formal approach to testing autonomous vehicles (AVs) in simulation for the IEEE AV Test Challenge. We demonstrate a systematic testing framework leveraging our previous work on formally-driven simulation for intelligent cyber-physical systems. First, to model and generate interactive scenarios involving multiple agents, we used Scenic, a probabilistic programming language for specifying scenarios. A Scenic program defines an abstract scenario as a distribution over configurations of physical objects and their behaviors over time. Sampling from an abstract scenario yields many different concrete scenarios which can be run as test cases for the AV. Starting from a Scenic program encoding an abstract driving scenario, we can use the VerifAI toolkit to search within the scenario for failure cases with respect to multiple AV evaluation metrics. We demonstrate the effectiveness of our testing framework by identifying concrete failure scenarios for an open-source autopilot, Apollo, starting from a variety of realistic traffic scenarios.
Scaled-Time-Attention Robust Edge Network
Jul 09, 2021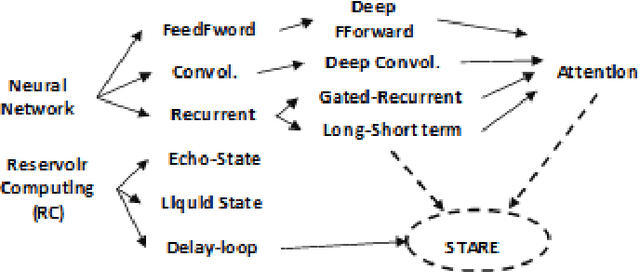
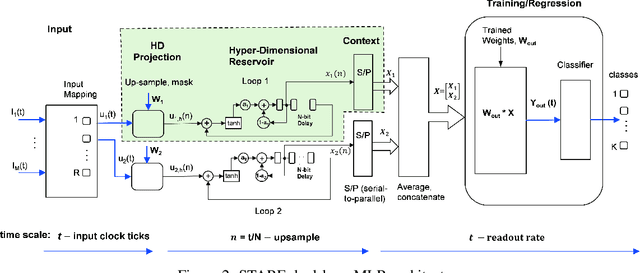
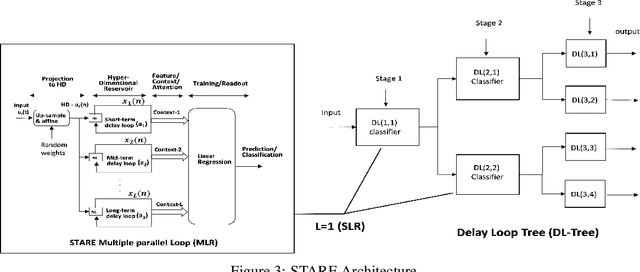
This paper describes a systematic approach towards building a new family of neural networks based on a delay-loop version of a reservoir neural network. The resulting architecture, called Scaled-Time-Attention Robust Edge (STARE) network, exploits hyper dimensional space and non-multiply-and-add computation to achieve a simpler architecture, which has shallow layers, is simple to train, and is better suited for Edge applications, such as Internet of Things (IoT), over traditional deep neural networks. STARE incorporates new AI concepts such as Attention and Context, and is best suited for temporal feature extraction and classification. We demonstrate that STARE is applicable to a variety of applications with improved performance and lower implementation complexity. In particular, we showed a novel way of applying a dual-loop configuration to detection and identification of drone vs bird in a counter Unmanned Air Systems (UAS) detection application by exploiting both spatial (video frame) and temporal (trajectory) information. We also demonstrated that the STARE performance approaches that of a State-of-the-Art deep neural network in classifying RF modulations, and outperforms Long Short-term Memory (LSTM) in a special case of Mackey Glass time series prediction. To demonstrate hardware efficiency, we designed and developed an FPGA implementation of the STARE algorithm to demonstrate its low-power and high-throughput operations. In addition, we illustrate an efficient structure for integrating a massively parallel implementation of the STARE algorithm for ASIC implementation.
A Meta Learning Approach to Discerning Causal Graph Structure
Jun 06, 2021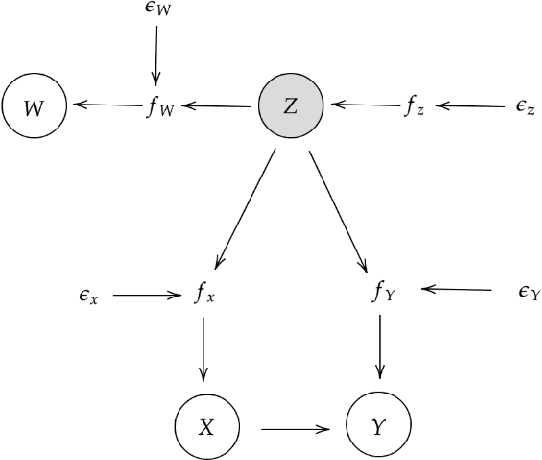
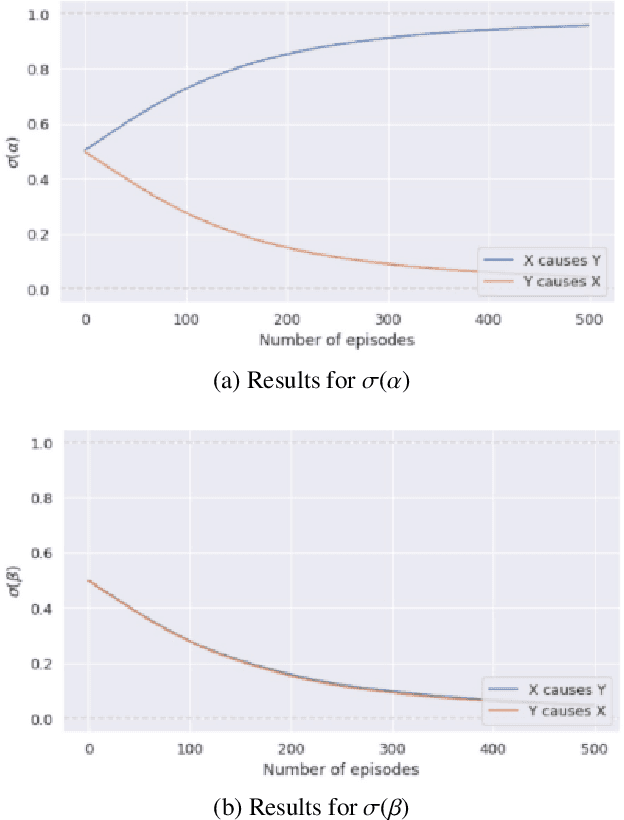
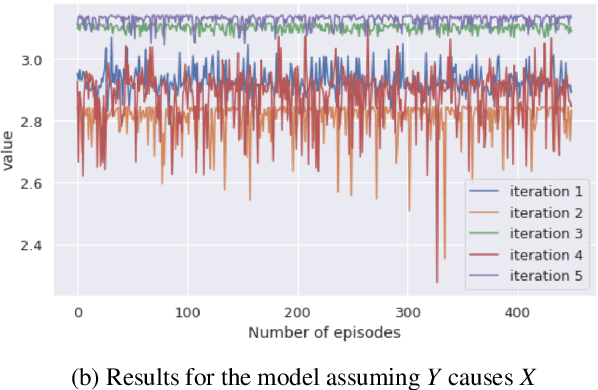
We explore the usage of meta-learning to derive the causal direction between variables by optimizing over a measure of distribution simplicity. We incorporate a stochastic graph representation which includes latent variables and allows for more generalizability and graph structure expression. Our model is able to learn causal direction indicators for complex graph structures despite effects of latent confounders. Further, we explore robustness of our method with respect to violations of our distributional assumptions and data scarcity. Our model is particularly robust to modest data scarcity, but is less robust to distributional changes. By interpreting the model predictions as stochastic events, we propose a simple ensemble method classifier to reduce the outcome variability as an average of biased events. This methodology demonstrates ability to infer the existence as well as the direction of a causal relationship between data distributions.